« Previous 1 2 3 4 Next »
OpenStack Sahara brings Hadoop as a Service
Computing Machine
Sahara's Long Arm in the VM
For Sahara to be able to configure the services within the Hadoop VMs in a way that ends in a working Hadoop cluster, it must work primarily on the VMs. The developers have followed the Trove model and other services of this kind and use an agent to implement the configuration. You need to obtain a corresponding basic image to use Sahara or build one yourself [4] for the magic to work.
In the old mechanism, the cloud-init script configured an SSH server, which Sahara then addressed externally. The agent solution, implemented in 2014, is much more elegant and also closes the barn door that previously needed to be kept open for incoming SSH connections to Hadoop VMs.
Unlike Trove, the Sahara agent contributes genuine added value. For example, MySQL can be installed and configured quite easily, although this is not the case with Hadoop, so the agent really does pay dividends in Sahara's case.
CLI or Dashboard?
Like any OpenStack service, users have two options for using Sahara's services. Option one is Horizon (Figure 4), the OpenStack dashboard. However, this still involves a touch of manual work for administrators because the required files are not yet available as a package. The Sahara components are also not part of the official dashboard.
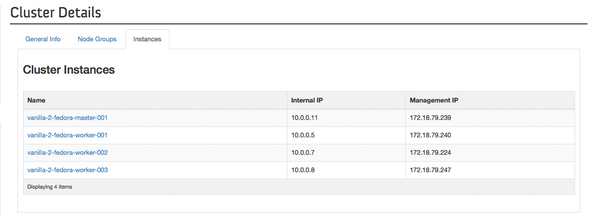 Figure 4: The Sahara pages in the OpenStack dashboard quickly provide information about which nodes belong to a Sahara cluster.
Figure 4: The Sahara pages in the OpenStack dashboard quickly provide information about which nodes belong to a Sahara cluster.
As usual, the command-line client is less complicated. Following the example of other OpenStack services, python-saharaclient allows all important operations to be performed at the command line. At the same time, it is also possible to use the corresponding Python library from scripts. Anyone wanting access to Sahara at a programming level has found a home.
Automatic Scaling
The Sahara provisioning engine can do a lot more than just launch VMs for running new Hadoop installations. However, working with Hadoop is – depending on the extent of the material you need to plow through – CPU and memory intensive. Naturally, corporations will want to spend as little money as possible.
On the one hand, administrators could initially equip their Hadoop clusters with so many virtual CPUs and so much virtual memory that they will certainly have enough to process the upcoming tasks in a meaningful way. On the other hand, Hadoop clusters are regularly assigned new tasks. To keep up with the dynamic growth, administrators would need to integrate more and more virtual resources than are initially necessary, but that would contradict the requirement for efficiency.
Sahara therefore has the ability to modify the number of VMs automatically in Hadoop clusters out of the box in line with factors set by the administrator. Administrators can tell Hadoop to start more workers if the strain on the existing workers exceeds a certain limit (e.g., taking into account factors such as CPU usage of each instance). Hadoop thus scales the cluster itself as required.
This approach also works if you use Sahara in its Analytics-as-a-Service mode: You only need to establish a limit that must not be exceeded in terms of the number of instances and their shared resources (Figure 5). Sahara and the integrated provisioning engine look after everything else themselves.
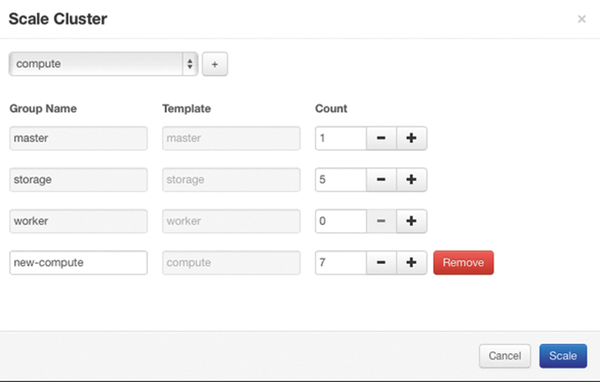 Figure 5: A cluster can be scaled in Sahara either manually by the administrator or automatically in Analytics-as-a-Service mode.
Figure 5: A cluster can be scaled in Sahara either manually by the administrator or automatically in Analytics-as-a-Service mode.
ISPs already operating an OpenStack platform and planning to integrate this feature in Sahara need to tackle the topic of hardware wisely. One thing is clear: To operate Hadoop sensibly, customers need a great deal of deployable performance in terms of CPU, RAM, and the network. Because a Hadoop cluster is very network intensive, even gigabit links can be saturated without much difficulty.
« Previous 1 2 3 4 Next »
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
The new OpenStack version 2014.1 alias "Icehouse"
 The new OpenStack version "Icehouse" comes with new features and new components, on top of numerous improvements to existing components.
The new OpenStack version "Icehouse" comes with new features and new components, on top of numerous improvements to existing components. -
Big data tools for midcaps and others
 Hadoop 2.x and its associated tools promise to deliver big data solutions not just to the IT-heavy big players, but to anyone with unstructured data and the need for multidimensional data analysis.
Hadoop 2.x and its associated tools promise to deliver big data solutions not just to the IT-heavy big players, but to anyone with unstructured data and the need for multidimensional data analysis. -
Hadoop for Small-to-Medium-Sized Businesses

Hadoop 2.x and its associated tools promise to deliver big data solutions not just to the IT-heavy big players, but to anyone with unstructured data and the need for multidimensional data analysis.
-
Ubuntu Server 14.04 LTS, 64-Bit
 The 64-bit server install image on this month's CD is for computers with the AMD64 or EM64T architecture (e.g., Athlon64, Opteron, EM64T Xeon, Core 2). Ubuntu Server emphasizes scale-out computing, whether you are administering an OpenStack cloud, a Hadoop cluster, or a massive render farm.
The 64-bit server install image on this month's CD is for computers with the AMD64 or EM64T architecture (e.g., Athlon64, Opteron, EM64T Xeon, Core 2). Ubuntu Server emphasizes scale-out computing, whether you are administering an OpenStack cloud, a Hadoop cluster, or a massive render farm. -
The New Hadoop

Hadoop version 2 expands Hadoop beyond MapReduce and opens the door to MPI applications operating on large parallel data stores.
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
