« Previous 1 2 3 Next »
Boosting Performance with Intel’s QuickAssist Technology
Fast Help
Execution Flow
In the case of a userspace application, the accelerator rings must be exposed to the process. The SAL must be configured to expose the logical instance to the userspace process. The instances are declared in the QuickAssist driver configuration file. The QuickAssist driver enables the userspace application to register with QuickAssist via icp_sal_userStartMultiProcess(). Similarly, when the process exits, it needs to call icp_sal_userStop().
The sequence described in Figure 4 shows the example of a case where the user has configured two compression logical instances for a process called SSL. The userspace process may then access these logical instances by calling cpaDcGetInstances(). The application may then initiate a session with these logical instances and perform in the present example a compression or decompression operation.
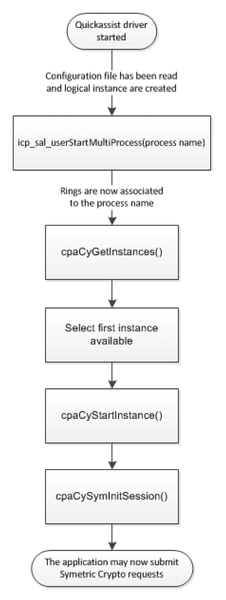 Figure 4: Intel QuickAssist API execution order.
Figure 4: Intel QuickAssist API execution order.
The driver does not allocate any memory. The application is entirely responsible for allocating the necessary resources for the Intel QuickAssist APIs to execute successfully. The application must provide instance allocation, session allocation, and payload buffers.
QuickAssist Compression Service
Bringing down storage cost is the key to any data storage solution. Support for stateful dynamic compression in the Intel QuickAssist compression service improves the compression ratio and provides checksum information that is useful for data integrity checking.
QuickAssist also offers a Compress and a Decompress API. These APIs take both the source and destination data as Scatter-Gather List buffers. After execution, the APIs return the statistics of the request.
The Intel QuickAssist compression service (Figure 5) offers two modes of operation:
 Figure 5: QuickAssist compression service description.
Figure 5: QuickAssist compression service description.
- Stateless operation mode: This mode can be defined as compress and forget mode. In this mode, the current request has no dependency on the previous request.
- Stateful operation mode: The current request has a dependency on a previous buffer of the same stream. When a request completes, a portion of the source data is saved in a history buffer. The history buffer is then restored on the following request. This mode offers a better compression ratio than the Stateless mode for compression operations. For decompression, the stateful mode enables the application to decompress partial fragments of data.
The checksum output is computed over the lifetime of the stream. The checksum is stored in a data structure that is saved and restored between requests just like the story buffer.
The diagram in Figure 6 shows the dependency between requests during stateful operation mode. With the history updated and transferred from one request to another, matching patterns are searched across the source and the history buffers, which contributes to improving the compression ratio.
 Figure 6: Stateful compression requests.
Figure 6: Stateful compression requests.
Batch and Pack
The save and restore functions associated with the stateful mode of operations do affect the bandwidth and IO performance. The history can be up to 48KB for some of the compression levels. Saving and restoring the history between each request means transferring to DRAM 96KB (48 x2) of data for each request. This constraint affects host interface bandwidth and reduces the performance of the compression/decompression engine because of the time spent saving and restoring state.
However if all the requests could be batched into one and submitted at once, history could remain local to the group of requests.
In storage usage models, the client sends a buffer (usually 4 to 8KB) to the storage controller. The controller takes several of these user IOs and packs them together in a single output buffer. Depending upon the storage controller architecture, the controller can decide that each user IO is either stateful or stateless compared to the previous one in the buffer list. For example, if multiple user IOs happen to be contiguous, it is feasible to make them stateful, thereby improving the overall compression ratio (compared with the use case where each user IO was individually compressed).
On a user IO write, the controller batches multiple user IOs, compresses them, and packs them before writing back to the storage media. Finally, when the client reads the user IO data, the controller seeks the buffer of interest, decompresses the data, and returns the inflated data back to the user.
Thanks to a smart software algorithm and a flexible hardware accelerator, the Batch and Pack QuickAssist feature improves the compression ratio, system resource utilizations, and read performance, as well as keeping the I/O operations to a minimum.
The Batch and Pack feature is intended to optimize the implementation of seekable compression. Seekable compression involves compressing multiple streams into one deflate stream, providing the facility to decompress only a portion of the deflate stream. The Batch and Pack feature allows grouping multiple compression jobs into a single request (batch). The deflated output data is concatenated in one buffer (pack). The Batch and Pack feature is exposed via a QuickAssist API.
The user has the option to select between stateful and stateless operation mode within the API. With stateful, the history is shared across all the jobs within the batch. As a consequence, the current job does not take advantage of the history from just the previous job (as with standard stateful requests), but from all the previous jobs instead. This behavior is the key to improving the compression ratio. However, it imposes a restriction: the entire "packed" buffer must be decompressed even if a single stream within the batch is needed by the application. No data dependency exists between multiple Batch and Pack requests; the Batch and Pack feature behaves in stateless mode.
In case the application would like to insert its own metadata, the Batch and Pack API provides a mechanism allowing the application to insert its metadata in the deflate output. Metadata is stored in a skip region added either at the end or at the beginning of a job.
If a skip region is included in the job source data, the Batch and Pack API will skip it. Data inside a skip region is not processed and is not available in the deflate bit stream. Figure 7 shows the behavior of the Batch and Pack feature across two requests in stateful mode. As you can see, the statefulness is kept within the jobs inside the request but not between requests. Table 2 lists the QuickAssist Batch and Pack API features.
Table 2
Batch and Pack API Feature List
| Input Parameters | Output Parameters |
|---|---|
| Unlimited number of Jobs | Deflated output available in one single for all the jobs within the batch |
| Each job data is stored in a scatter-gather buffer list | Statistics available for each job |
| Support for skip regions at the beginning or at the end of each job | |
| Support to reset history |
 Figure 7: Batch and Pack behavior in stateful mode.
Figure 7: Batch and Pack behavior in stateful mode.
The Batch and Pack feature makes it possible to decompress a specific portion of a long stream without having to decompress the entire stream. The skip region allows inserting user metadata, which can easily be accommodated to store checksums, deflate block lengths, and offsets. With the history reset capability, it is possible to decompress only a portion of the deflate stream to retrieve the data segment of interest.
Figure 8 shows an example of how seekable decompression is achieved with Batch and Pack. Even if the deflate stream is very long, it is possible to decompress only a section of it. When the QuickAssist Batch and Pack API is called with the history reset on a particular job, you can decompress the deflate output from this job on.
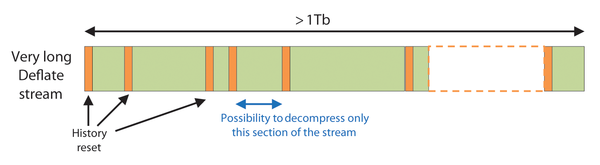 Figure 8: Batch and Pack used for seekable decompression.
Figure 8: Batch and Pack used for seekable decompression.
« Previous 1 2 3 Next »
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
File Compression for HPC

One of the most underutilized capabilities in Linux and HPC is compressing unused data files.
-
Read-only File Compression with SquashFS

If you are an intensive, or even a typical, computer user, you store an amazing amount of data on your personal systems, servers, and HPC systems that you rarely touch. SquashFS is an underestimated filesystem that can address that needed, but little used, data.
-
Parallel and Encrypted Compression

You have the cores, so use them – to compress, that is.
-
Read-only file compression with SquashFS
 If you are an intensive, or even a typical, computer user, you store an amazing amount of data on your personal computers, servers, and HPC systems that you rarely touch. SquashFS is an underestimated filesystem that can address that needed, but little used, data.
If you are an intensive, or even a typical, computer user, you store an amazing amount of data on your personal computers, servers, and HPC systems that you rarely touch. SquashFS is an underestimated filesystem that can address that needed, but little used, data. -
Kafka: Scaling producers and consumers
 A guide to 10x scaling in Kafka with real-world metrics for high throughput, low latency, and cross-geographic data movement.
A guide to 10x scaling in Kafka with real-world metrics for high throughput, low latency, and cross-geographic data movement.
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
