« Previous 1 2 3 Next »
Harden your OpenStack configuration
Fortress in the Clouds
Updates
A second important building block for hardening OpenStack is consistently installing updates for all components. This need for updates also applies to servers that are not directly accessible from the outside: A vulnerability in KVM that makes an outbreak from the VM possible could erode any network-based isolation.
The point about installing updates may be a truism, but based on my experience, it is essential to remind cloud users that updates are still important. You can see the panic in the eyes of many OpenStack cloud admins at the thought of updates. Because OpenStack is complex and difficult to set up, the prospect of updating is often quite daunting.
Manually installed OpenStack environments are more similar to modern art than to easily maintainable software platforms, but you can avoid some of the biggest pains if you pay attention to a couple of important principles:
- Only automated deployment – No manually installed servers should exist in a production environment. It must be possible at any time to remove any node from the setup and to replace it with an automated reinstall that puts the latest software on the disk. Manual changes to the nodes in the cloud are automatically prohibited, because they are not easily reproducible (Figure 3).
- Replaceable systems – To make it easier to remove and reinstall a computer for updates, the VMs on each node must support migration to another cloud node at any time during operation – without downtime for customers.
 Figure 3: Red Hat OpenStack Platform SUSE Cloud, and Ubuntu offer automated deployment tools and make it clear: Automation is essential in the cloud.
Figure 3: Red Hat OpenStack Platform SUSE Cloud, and Ubuntu offer automated deployment tools and make it clear: Automation is essential in the cloud.
In classic clouds, storage is the problem most of the time: If you do not put your OpenStack VMs on distributed storage, but on virtual disks directly attached to the hypervisor, you'll end up in with a maintenance nightmare, because the data of the VM exists precisely once on the hypervisor.
Distributed storage solutions such as Ceph make more sense: If a VM resides on Ceph, the RBD drive associated with it can be connected to the VM on a different host at any time. The combination of VMware and libvirt including RBD drivers can handle this form of live migration with ease. Other SDN solutions available on the market also support this functionality; there is thus nothing to prevent a successful live migration.
By ensuring that any VM on a hypervisor can change to an another hypervisor at any time, you make it easier to install updates. In some scenarios, installing updates actually becomes unnecessary: If a computer has outdated software, you simply reinstall it with the latest packages.
Fast and easy replacement offers another advantage: If there is even the slightest suspicion that a computer may have been compromised, it can be quickly removed from the cloud for forensic investigations. Once you are finished, automatic reinstallation ensures that the server is available again.
Sore Point: Keystone
The OpenStack Keystone identity service, officially dubbed Identity, is the root of all functionality in OpenStack. All clients that want to do something in OpenStack first need to pick up a token from Keystone with a combination of username and password and then send requests to authenticate. A token is a temporarily valid password, based on which Keystone checks the legitimacy of a request.
Keystone is accordingly difficult when it comes to OpenStack clouds: Attackers who manage to get to a valid set of credentials can do whatever they want, at least within the projects in which the affected access credentials play a role. Furthermore, service access points are usually unrestricted. Handling with this sensitive information is thus a critical task.
The Unspeakable Admin Token
The admin token is a relic left over from the early days of Keystone that can exist in plaintext in keystone.conf. The token is practically a master key for the entire cloud: You can create and modify any other account with it. The admin token was previously used to add the first set of user data to Keystone at the start of an OpenStack installation. There is now a bootstrap command in keystone-manage for this purpose that allows the initial setup without a remote admin token. OpenStack admins need to ensure that the admin_token entry is commented out in keystone.conf file and does not contain a value.
Any OpenStack service that wants to talk to Keystone needs to know the credentials for service access. Virtually all components expect this information in the form of a separate entry in their own configuration. The relevant data is typically available in plain text.
From an admin perspective, it is desirable to restrict read access to the configuration files in an appropriate manner. Although attackers should not even make it onto the affected hosts, if they do manage to log in, they should not be able to read the service configuration files with a normal user account.
At service level you can defuse the Keystone situation by configuring an appropriate user role schema. Keystone is not particularly granular by default – it only has two relevant roles from the user's point of view: the admin and the user role. Many admins inadvertently assign the admin role to users in projects because they assume that they are assigning special rights within the project to the user by doing so. However, if you have the admin role for one project, you can gain access to other projects in a roundabout way. It is thus a bad idea to assign the admin role to users.
The risks involved with the user role can also be defused. The service identifies users by their login data, which consists of the username, the password, and the project for which the user requests a token. Keystone also stores the mappings defining the roles a user has in a specific project.
Keystone itself, however, does not decide what a user with a specific role can do in a project; this is decided by the individual components: Each of the OpenStack services has a file named policy.json (Figure 4), in which the role needed by the service is stated for all API operations known to the service.
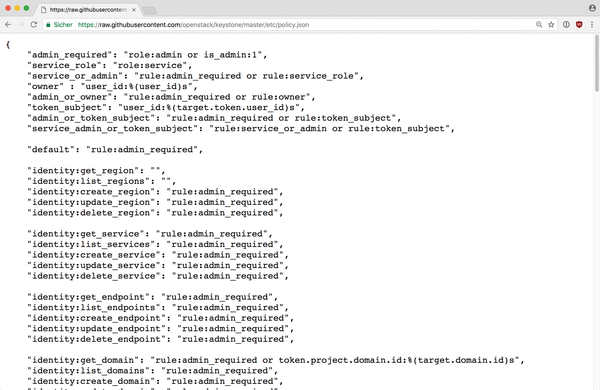 Figure 4: policy.json files control how the OpenStack services access individual APIs.
Figure 4: policy.json files control how the OpenStack services access individual APIs.
By adapting the policy.json files of all services, you can define a system based only on the user role. You might create an operator role for writing API operations (say, creating a new VM or a virtual network) and a viewer role for read operations. Then the principle of separation of concerns applies: If you perform only read operations, you are only assigned the viewer roll. If you need write access, you are additionally assigned the operator role.
This approach follows the principle of risk mitigation: The less frequent the write access, the lower the risk that an account will fall into the wrong hands. For the sake of completeness, I should mention that OpenStack does not make it easy for the admin to create policy.json files to match the desired setup. On the one hand, many API operations are not documented at all, or are poorly documented, and the total number of API operations is huge – well above 1,000. If you want to polish your policy.json files, you need to schedule a long lead time.
« Previous 1 2 3 Next »
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
The state of OpenStack in 2022
 The unprecedented hype surrounding OpenStack 10 years ago changed to disillusionment, which has nevertheless had a positive effect: OpenStack is still evolving and is now mainly deployed where it actually makes sense to do so.
The unprecedented hype surrounding OpenStack 10 years ago changed to disillusionment, which has nevertheless had a positive effect: OpenStack is still evolving and is now mainly deployed where it actually makes sense to do so. -
Kickstack: OpenStack with Puppet

Kickstack uses Puppet modules to automate the installation of OpenStack and facilitate maintenance.
-
Simple OpenStack deployment with Kickstack
 Kickstack uses Puppet modules to automate the installation of OpenStack and facilitate maintenance.
Kickstack uses Puppet modules to automate the installation of OpenStack and facilitate maintenance. -
Do You Know Juno?
 The OpenStack cloud platform plays a major role in the increasingly important cloud industry, so a new release is big news for cloud integrators and admins. The new version 2014.2 "Juno" release mostly cleans up and maintains the working model but adds a few innovations.
The OpenStack cloud platform plays a major role in the increasingly important cloud industry, so a new release is big news for cloud integrators and admins. The new version 2014.2 "Juno" release mostly cleans up and maintains the working model but adds a few innovations. -
OpenStack: Shooting star in the cloud
 OpenStack is attracting lots of publicity. Is the solution actually qualified as a cloud prime mover? We take a close look at the OpenStack cloud environment and how it works.
OpenStack is attracting lots of publicity. Is the solution actually qualified as a cloud prime mover? We take a close look at the OpenStack cloud environment and how it works.
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
