« Previous 1 2 3 Next »
Apache Storm
Analyzing large volumes of data with Apache Storm
Starting the Storm Environment
All Storm daemons are fast-fail systems – this means that they automatically stop when an unexpected error occurs. Thus, individual components in the environment can fail "safely" and then successfully restart without negatively affecting the entire system. Of course, this approach only works if the Storm daemons are also restarted immediately after a failure, which requires the use of various tools to guarantee reliable monitoring.
Most Linux systems, such as Debian and distributions based on it, have a supervisor component that specifically monitors daemons, keeps an eye on their status, and restarts them if necessary. In Ubuntu, you can install the supervisor using the following command:
sudo apt-get --yes install supervisor
This command installs and starts the supervisor service. Its main configuration file is saved in /etc/supervisor/supervisord.conf. The supervisord configuration file automatically includes all files that correspond to the pattern ".conf" in /etc/supervisord/conf.d/.
To keep the Storm configuration files under permanent control, place them in this directory. Next, create a configuration file for each daemon that is to be monitored by the supervisor component. The file will include the following data:
- Unique name for the service to be monitored.
- Execution command.
- Working directory in which the command is run.
- Autostart option which determines whether the service should be restarted.
- User to whom the service belongs.
Then create three configuration files to ensure that the Storm components are automatically started (and restarted) by the supervisor service: /etc/supervisord/conf.d/storm-nimbus.conf. Assign the following content to the configuration file:
[program:storm-nimbus] command=storm nimbus directory=/home/storm autorestart=true user=storm
The configuration file /etc/supervisord/conf.d/storm-supervisor.conf should look like this:
[program:storm-supervisor] command=storm supervisor directory=/home/storm autorestart=true user=storm
Finally create a configuration file /etc/supervisord/conf.d/storm-ui.conf for the Storm GUI:
[program:storm-ui] command=storm ui directory=/home/storm autorestart=true user=storm
You can now start the supervisor service and stop again if necessary:
sudo /etc/init.d/supervisor start sudo /etc/init.d/supervisor stop
The supervisor service loads the new configurations and starts various Storm daemons. You can then verify the availability of the Storm services using the web GUI (Figure 3).
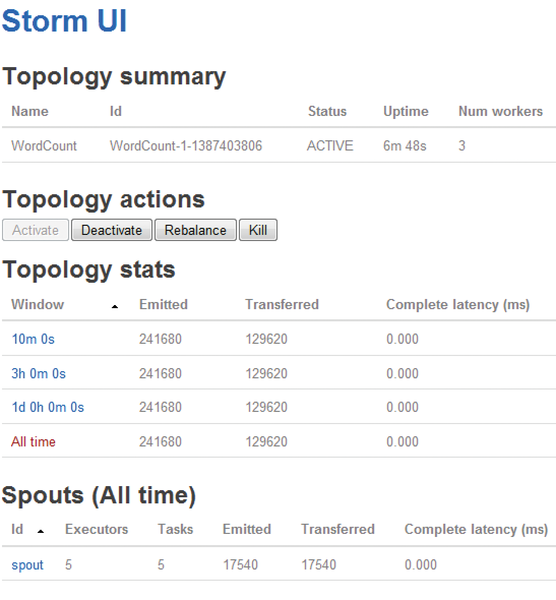 Figure 3: The Storm web UI provides a variety of status information but does not allow any intervention with the environment.
Figure 3: The Storm web UI provides a variety of status information but does not allow any intervention with the environment.
To do this, access the URL http://localhost:8080 using your browser. You can see from the simple web interface that Storm is executed; however, no topologies are currently running. If you are unable to access the GUI, you will find possible clues in the logfiles:
- Storm GUI:
/var/log/storm/ui.log - Nimbus:
/var/log/storm/nimbus.log - Supervisor:
/var/log/storm/supervisor.log
You now have an operable basic installation of Storm that you can refine according to your needs.
Adjustments to the Basic Configuration
The next step is modifying the basic configuration. The Storm configuration consists of various YAML properties. When the Storm daemon starts, it loads various default values and then the file storm.yaml. Listing 1 shows such a file with the necessary information.
Listing 1
Minimum storm-yaml File
01 # List of hosts in the ZooKeeper cluster 02 storm.zookeeper.servers: 03 - "localhost" 04 # Nimbus node host name 05 nimbus.host: "localhost" 06 # supervisor port 07 supervisor.slots.ports: 08 - 6700 09 - 6701 10 - 6702 11 - 6703 12 # Directory in which Nimbus and Supervisor store data 13 storm.local.dir: "/home/storm" 14 # Optional list of hosts which acts as a storm DRPC server 15 # drpc.servers: 16 # - "localhost"
If you want to use a multihosting environment, you will need some additional settings. Using storm.zookeeper.servers lets you create a list of host names in the ZooKeeper cluster according to the scheme above. The designation localhost is okay for a pseudo-cluster. When setting up a real cluster, you will also need to define the Nimbus nodes with nimbus.host.
The Storm configuration uses a dot-separated naming convention for the different configuration categories, where the first keyword determines the respective category:
storm.*: General Storm settingsnimbus.*: Nimbus configurationui.*: Storm UI configurationdrpc.*: DRPC server configurationsupervisor.*: Supervisor configurationworker.*: Worker configurationzmq.*: ZeroMQ configurationtopology.*: Topology configuration
The default Storm configuration is set in the defaults.yaml file. You can, of course, also make changes here that affect the whole Storm environment. You can, for example, change the web interface standard port 8080 using ui.port.
You can specify the JVM options that are added to the Java command line when starting the GUI using ui.childopts. You can also transfer the custom options to the supervisor daemon execution using supervisor.child-opts.
The execution of topologies is controlled using the "topology" configuration. Storm provides several customization options for this. Using
topology.message.timeout.secs
determines the maximum amount of time that the receipt of a tuple is allowed to last until the operation is regarded as having failed. The default value is 30 seconds, but a higher setting may make sense in a live environment.
The option topology.max.spout.pending, with as the default configuration, passes tuples onto spouts as quickly as they can receive the information. Processing can be optimized by using a value other than . The two most important customizations for tuning the topology execution are available in topology.enable.message.timeout.
You can use the timeout configuration to determine whether tuple processing uses a timeout (true) or not (false). Before disabling the timeout functions, you should experiment with different second values until you have found the optimal performance.
Running Topologies
If you have not already done so, you can start the Storm environment after making any changes. To do this, you need to execute the three core components:
./storm nimbus./storm supervisor./storm ui
You have now created the right conditions for executing topologies. However, what is the best way to develop topologies? Nathan Marz provides different predefined scripts for download via GitHub [2] within the Storm starter package. These scripts are ideal for becoming acquainted with Storm.
The example in Listing 2 comes from this collection and implements a word count that consists of a bolt and a reduction transformation for other bolts.
Listing 2
Word Count Script for Storm
01 TopologyBuilder builder = new TopologyBuilder();
02
03 builder.setSpout("spout", new RandomSentenceSpout(), 5);
04
05 builder.setBolt("map", new SplitSentence(), 4).shuffleGrouping("spout");
06
07 builder.setBolt("reduce", new WordCount(), 8).fieldsGrouping("map", new Fields("word"));
08
09 Config conf = new Config();
10 conf.setDebug(true);
11
12 LocalCluster cluster = new LocalCluster();
13 cluster.submitTopology("word-count", conf, builder.createTopology());
14
15 Thread.sleep(10000);
16
17 cluster.shutdown();
This script begins with the declaration of a new topology that uses the TopologyBuilder category. Line 3 defines a spout with the name spout and uses the RandomSentenceSpout category. This category in turn outputs one of five sets from the output data. Line 5 defines the first bolt, specifically a split bolt, which applies the SplitSentence category to split the input stream and outputs individual words. The shuffleGrouping category ensures the random grouping of words.
Next, line 7 includes the definition of the last bolt, which serves as a reducing mechanism. The WordCount method implements the actual word count. Lines 9 and 10 include the creation and definition of a configuration object and the debugging mode. Lines 12 and 13 are responsible for the creation of a local cluster (in "local" mode) and the cluster name. Finally, Storm rests for the duration in second specified in line 15 and then shuts down with the shutdown command in line 17.
« Previous 1 2 3 Next »
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
Automate complex IT infrastructures with StackStorm
 StackStorm is an open source, event-based platform for runbook automation.
StackStorm is an open source, event-based platform for runbook automation. - Splunk Announces Splunk Storm
- Cray Embraces Deep Learning
-
Coordinating distributed systems with ZooKeeper
 Anyone who manages many clusters should be meticulous in ensuring that organized processes prevail in the distributed server zoo. We describe how Apache ZooKeeper fulfills this task.
Anyone who manages many clusters should be meticulous in ensuring that organized processes prevail in the distributed server zoo. We describe how Apache ZooKeeper fulfills this task. -
Processing streaming events with Apache Kafka
 Apache Kafka reads and writes events virtually in real time, and you can extend it to take on a wide range of roles in today's world of big data and event streaming.
Apache Kafka reads and writes events virtually in real time, and you can extend it to take on a wide range of roles in today's world of big data and event streaming.
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
