Comparing Ceph and GlusterFS
Shared storage systems GlusterFS and Ceph compared
Metadata in GlusterFS
A special feature of GlusterFS is its treatment of metadata. Experts know that this is often a performance killer. Incidentally, this is just not a phenomenon of shared data repositories; even local filesystems such as ext3, ext4, or XFS have learned the hard way here. Implementation of dedicated metadata entities is a typical approach for shared filesystems. The idea is to set them up to be as powerful and scalable as possible, so that there is no bottleneck.
GlusterFS goes about this in a completely different way and does not use any metadata servers. For this approach to work, other mechanisms are, of course, necessary.
The metadata can be broadly divided into two categories. On one hand, you have information that a normal filesystem also manages: permissions, timestamps, size. Because GlusterFS works on a file basis, it can mostly use the back-end filesystem. The information just mentioned is also available there and often does not require separate management at the GlusterFS level.
However, the nature of shared storage systems requires additional metadata, among other things. Information about the server/brick on which data is currently residing is very important – particularly if distributed volumes are used. In that case, the data are distributed across multiple bricks. Users does not see anything of this; to them, it looks like a single directory. GlusterFS also partially uses the back-end filesystem for the metadata – or, to be more precise, the extended file attributes (Figure 3). For the rest, GlusterFS stores nothing; instead, it simply computes the required information.
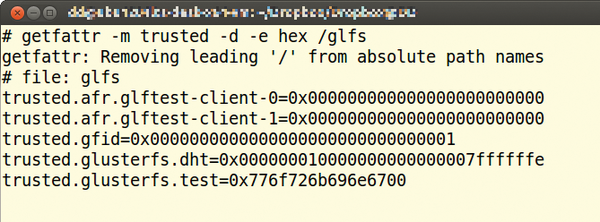 Figure 3: GlusterFS uses the extended attributes of the back-end filesystem for storing metadata.
Figure 3: GlusterFS uses the extended attributes of the back-end filesystem for storing metadata.
The elastic hash algorithm forms the basis of this computation. Each file is assigned a hash value based on its name and path. The namespace is then partitioned with respect to the possible hash values. Each area is assigned bricks.
This solution sounds very elegant, but it also has its drawbacks. If a file name changes, the hash value changes, too, which can lead to another server now being responsible for it. The consequence of renaming is then a copy action for the corresponding data. If the user saves multiple files with similar names on GlusterFS, the files may well all end up on the same brick. In the end, it can happen that space remains in the volume itself but that one of the bricks involved is full. In such a case, previous versions of GlusterFS were helpless. Now, the software can also forward such requests to alternative bricks. An asymmetrically filled namespace is therefore no longer a problem.
Ceph Growth
If you think about the history of Ceph, some events seem strange. Originally, Ceph did not work as a universal object store. Instead, it was designed to be a POSIX-compatible filesystem – but with the trick that the filesystem was spread across different computers (i.e., a typical distributed filesystem). Ceph started to grow when the developers notice that the underpinnings for the filesystem were also quite useful for other storage services. However, because the entire project has always operated under the name of the filesystem and the Ceph name was familiar, it was unceremoniously decided to use Ceph as the project name and to rename the actual filesystem. To this day, it firmly remains a part of Ceph and is now somewhat awkwardly called CephFS (although the matching CephFS module is still called ceph.ko in the kernel – a little time may still have to pass before the names are synced).
CephFS offers users access to a Ceph cluster, as if it were a POSIX-compatible filesystem. For the admin, access to CephFS looks just like access to any other filesystem; however, in the background, the CephFS driver on the client is communicating with a Ceph cluster and storing data on it.
Because the filesystem is POSIX compliant, all tools that otherwise work in a normal filesystem also work on CephFS. CephFS directly draws the property of shared data storage from the functions of the object store itself (i.e., from Ceph). What is also important in CephFS, however, is that it enables parallel access by multiple clients in the style of a shared filesystem. According to Sage Weil, the founder and CTO of InkTank, this functionality was one of the main challenges in developing CephFS: observing POSIX compatibility and guaranteeing decent locking, while different clients simultaneously access the filesystem.
In CephFS, the Metadata Server (MDS) plays a role in solving this problem. The MDS in Ceph is responsible for reading the POSIX metadata of objects and keeping them available as a huge cache. This design is an absolutely essential difference compared with Lustre, which also uses a metadata server, but it is basically a huge database in which the object locations are recorded. A metadata server in CephFS simply accesses the POSIX information already stored in the user extended attributes of the Ceph objects and delivers them to CephFS clients. If needed, several metadata servers covering the individual branches of a filesystem can work together. In this case, clients receive a list of all MDSs via the monitoring server, which allows them to determine which MDS they need to contact for specific information.
The Linux kernel provides a driver for CephFS out the box; a FUSE module is also available, which is largely used on Unix-style systems that have FUSE but do not have a native CephFS client.
The big drawback to CephFS at the moment is that InkTank still classifies Ceph as beta (i.e., the component is not yet ready for production operation). According to various statements by Sage Weil, there should not be any problems if only one metadata server is available. Problems concerning metadata partitioning are currently causing Weil and his team a real headache.
Ceph's previously mentioned unified storage concept is reflected in the admin's everyday work when it comes to scaling the cluster horizontally. Typical Ceph clusters will grow, and the appropriate functionalities are present in Ceph for this. Adding new OSDs on the fly is no problem, nor is downsizing a cluster. OSDs are responsible for keeping the cluster consistent in the background, in collaboration with the MONs, whereas users always see the cluster but never the individual OSDs. A 20TB cluster grows to the appropriate size after adding new hard drives in the CRUSH algorithm configuration file (this is Ceph's internal scheduling mechanism), or shrinks accordingly. However, none of these operations can be seen on the front end.
Extensibility in GlusterFS
Easy management and extensibility were the self-imposed challenges for GlusterFS developers. Extensibility in particular did not cause the usual headaches, and, actually, the conditions are good. Adding new bricks or even new servers to the GlusterFS pool is very simple. The trust relationship, however, cannot be established by the new server itself – contact must be made from a previously integrated GlusterFS member. The same applies to the opposite case (i.e., if the GlusterFS cluster needs to shrink). Increasing and decreasing the size of volumes is not difficult, but a few items must be considered.
The number of bricks must match the volume setup, especially if replication is in play. With a copying factor of three, GlusterFS only allows an extension to n "bricks" if n is divisible by three. This also applies to removing bricks. If the volume is replicating and distributed, then this is a little tricky. You must be careful that the order of the bricks is correct. Otherwise, replication and distribution will go haywire. Unfortunately, the management interface is not very helpful with this task. If the number of bricks changes, the partitioning of the namespace changes, too. This applies automatically for new files.
Existing files, which should now be somewhere else, do not migrate automatically to the right place. The admin must push-start the rebalance process. The right time to do this depends on various factors: How much data needs to be migrated? Is client-server communication affected? How stressed is your legacy hardware? Unfortunately, there is no good rule of thumb. GlusterFS admins must gain their own experience, depending on their system.
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
GlusterFS

Sure, you could pay for cloud services, but with GlusterFS, you can take the idle space in your own data center and create a large data warehouse quickly and easily.
-
Red Hat Storage Server 2.1
 If you believe Red Hat's marketing hype, the company has no less than revolutionized data storage with version 2.1 of its Storage Server. The facts tell a rather different story.
If you believe Red Hat's marketing hype, the company has no less than revolutionized data storage with version 2.1 of its Storage Server. The facts tell a rather different story. -
GlusterFS Storage Pools

GlusterFS stores data across the network and can be used as a storage back end in cloud environments.
-
Build storage pools with GlusterFS
 GlusterFS stores data across the network and can be used as a storage back end in cloud environments.
GlusterFS stores data across the network and can be used as a storage back end in cloud environments. -
Getting Ready for the New Ceph Object Store

The Ceph object store remains a project in transition: The developers announced a new GUI, a new storage back end, and CephFS stability in the just released Ceph v10.2.x, Jewel.
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
