
We look at the new features in Ceph version 0.56, alias “Bobtail,” talk about who would benefit from CephX Ceph encryption, and show you how a Ceph Cluster can be used as a replacement for classic block storage in virtual environments.
The RADOS Object Store and Ceph Filesystem: Part 3
Access control to existing storage is an important topic. If you are offering your users tailor-made storage areas, you will usually also want to ensure that users do not have access to any other users’ storage. In Ceph, this is exactly what CephX does: on the one hand, CephX ensures that administrative work is only carried out by authorized admins; on the other, it controls access to storage by normal users. But there’s a flaw – although the mechanism is still reasonably easy to enable (in the new v0.56, three lines in /etc/ceph/ceph.conf are all it takes), activating CephX will make many everyday tasks a bit cumbersome in Ceph.
CephX in Daily Use
A good example is the ceph -w command. If you have set up a Ceph cluster as per the guidelines in parts one and two of this series, you will know that Ceph uses the -w paramater to output information about the current status of the cluster, as well as any changes. Once CephX is active, this no longer that simple. The admin who runs ceph -w has to authenticate and thus tell Ceph that that they are actually permitted to view this information. This is compounded by the fact that the various command-line tools from the Ceph universe – ceph, RBD, and RADOS – use different parameters, in part to provide the appropriate info to CephX. In the case of ceph -w with CephX enabled, you need to do this,
ceph --id admin --keyring /etc/ceph/keyring.admin -w
given that the keyring belonging to the client.admin user resides in /etc/ceph/keyring.admin. In this case, the output is exactly the same as the output you would see without CephX.
Of course, this long command is annoying – if you want to avoid all the typing, you can automate the key selection: /etc/ceph/ceph.conf lets you define where a user’s keyring is located. The following entry stipulates, for example, that the keyring for client.admin resides in the /etc/ceph/keyring.admin file:
[client.admin]
keyring = /etc/ceph/keyring.adminFrom now on, Ceph assumes that admin is always used as the ID and executes a ceph -w command with this ID using the appropriate keyring. Incidentally, letting users omit the leading ‘client.’ from their IDs is a CephX convention that has to do with the internal workings of Ceph. OSDs and MONs also have their own keys with names that start ‘osd.’ or ‘mon.’. Because users will hardly want to log in to Ceph as OSDs or MONs, and thus only ‘client.’, Ceph assumes this for user requests.
Mounting CephFS with CephX
Enabling CephX also affects the Ceph filesystem, CephFS. For a mount operation, you also need to specify a user and a password (Figure 1). The example assumes a username of admin; first you need to discover admin’s password:
ceph-authtool --name client.admin --print-key /etc/ceph/keyring.admin
The example uses AQBNTxZRWId7JxAA/Ac4ToR7ZfNdOGDSToGHpA== as the password. The mount command is then:
mount -o name=admin,secret=AQBNTxZRWId7JxAA/Ac4ToR7ZfNdOGDSToGHpA==,\ noatime -t ceph 192.168.133.111:/ /mnt
If you do not want to use a password in plain text, you can also store it in a file (in this example, /etc/ceph/secret.admin) and reference the file during the mount:
mount -o name=admin,secretfile=/etc/ceph/secret.admin,\ noatime -t ceph 192.168.133.111:/ /mnt
You could, incidentally, add this mount command to /etc/fstab to activate CephFS automatically at boot time.
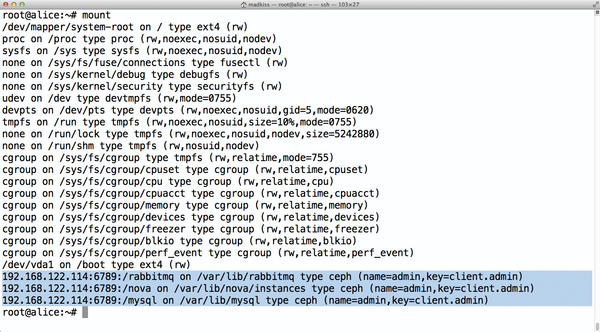 Figure 1: CephFS mounts do not show the password in plain text in the output of mount or in /prot/mtab.
Figure 1: CephFS mounts do not show the password in plain text in the output of mount or in /prot/mtab.
Separate Pools for Separate Users
Pools in Ceph are like a kind of name tag. Although they do not affect the internal organization of the object store, they do allow you to assign individual objects to specific users. It is only in the CephX context that you can leverage their abilities to the full: Nothing is preventing you from creating separate pools for individual users or user groups and restricting access to storage to these pools.
To implement this concept, you first need a pool. Again, this configuration works a little differently if CephX is active. The
ceph OSD pool create test 1000
command would fail because the user who executes the command is not a Ceph administrator. Similar to the ceph -w example, the
ceph --id admin --keyring /etc/ceph/keyring.admin osd pool create test 1000
command does the trick. The command returns no output, apart from a 0. If in doubt, you can check its success with echo $?.
The pool is in place, but you are still missing a user who is allowed exclusive use of it. In the last few months, user management in Ceph has gone through a number of changes in terms of additional functions, so large parts of the documentation on the web is more or less obsolete. First and foremost, each user usually has a keyring file on the Ceph hosts (in this example, with the admin user, /etc/ceph/keyring.admin). However, this is not precisely the file that Ceph references to check user authorizations; instead, the MON servers have their own, internal keyrings. When a user is added to a Ceph installation, it’s not enough to create a keyring file on the Ceph hosts in /etc/ceph. Additionally, you need to integrate the key into the cluster with ceph auth add. Alternatively, both procedures can be completed with a single command. For example, to create a key for a user test and enable it in Ceph at the same time, you would enter:
ceph --id admin \
--keyring /etc/ceph/keyring.admin \
auth get-or-create client.test \
mds ‘allow’ osd ‘allow * pool=test’ \
mon ‘allow *’ > /etc/ceph/keyring.testThe command only makes sense if a pool named test already exists. Now, /etc/ceph/keyring.test contains the keyring of the user who can only access the test pool. If this user attempted to access a different pool, Ceph would reject the attempt with a Permission Denied error message.
Customizing User Permissions
It is also possible to change credentials once assigned (Figure 2). The public documentation for this is incomplete, but it still works: First, you need to ensure that the user’s keyring contains the new, full credentials. The keyring for the previously created test user in /etc/keyring/keyring.test might look like this directly after being created:
[client.test] key = AQA5XRZRUPvHABAABBkwuCgELluyyXSSYc5Ajw==
Ceph knows that this user can access the test pool because this was stated specifically in the command used to create the user. If this user now also needs access to the test2 pool, you need to modify the /etc/ceph/keyring.test file:
[client.test]
key = AQA5XRZRUPvHABAABBkwuCgELluyyXSSYc5Ajw==
caps osd = “allow * pool=test, allow * pool=test2”
caps mds = “allow”
caps mon = “allow *”The record following key = must remain unchanged; otherwise, other applications would be unable to communicate with Ceph if they configure the Ceph key statically. Finally, you need to tell Ceph about the change by adding the new key to the internal Ceph keyring:
ceph --id admin -k /etc/ceph/keyring.admin auth add client.test \
-i /etc/ceph/keyring.testNow the test user has access authorization for both the test pool and the test2 pool.
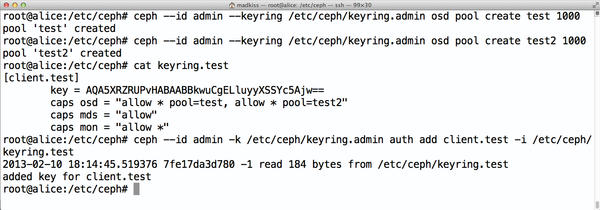 Figure 2: To change a user’s authorizations retroactively, you need to modify the keyring files in /etc/ceph.
Figure 2: To change a user’s authorizations retroactively, you need to modify the keyring files in /etc/ceph.
Ceph as a Substitute for Traditional Block Storage
After so much rights theory, I’ll move on to something practical. Although many people who look into the subject of Ceph are quite excited by the technical solution, they often lack an idea of how Ceph can be used in concrete terms in everyday life. It is quite possible, though – for example, if you run a virtualization cluster and continually have problems expanding its capacity. Despite all the words of warning you might hear, Ceph is not just useful as a storage monster within a cloud setup; it will also provide reliable service in smaller environments that use classic virtualization based on KVM.
Ceph and Libvirt
Because the developers of the libvirt virtualization environment get on very well with the Ceph developers, extensive Ceph integration is already available in libvirt. Instead of a normal block device, you can specify an RBD image as the backing device for a VM managed by libvirt; in the background, libvirt then directly accesses the Ceph cluster. The advantage is obvious: In this kind of setup, each VM can be run on each node of a virtualization cluster, provided access to the Ceph cluster is possible. If CephX is switched off, modifications to the libvirt VM definitions are minimal. For example, if a VM in a classic virtualization setup accesses a normal block device in the background, the corresponding entry in the file – in this example it is called ubuntu-amd64-alice.xml – would look like Listing 1.
Listing 1: VM Storage as a Block Device
<disk type=’block’ device=’disk’> <driver name=’qemu’ type=’raw’ cache=’none’/> <source dev=’/dev/drbd/by-res/vm-ubuntu-amd64-alice’/> <target dev=’vda’ bus=’virtio’/> <address type=’pci’ domain=’0x0000’ bus=’0x00’ slot=’0x05’function=’0x0’/> </disk>
This kind of VM can easily move to a Ceph cluster. Pertinent examples recommend placing VMs within Ceph in a separate pool (called libvirt in this example). If the pool was created as demonstrated by the example above, the data would migrate from the “old” block device to the new RBD image. The new pool needs an RBD image of the desired size. The command
qemu-img create -f rbd rbd:libvirt/ubuntu-amd64-alice 100G
creates it with a size of 100GB. (Caution: For the command to work, /etc/ceph/ceph.conf must accurately reflect the current topology of the Ceph cluster and contain details of where the key for client.admin resides, if the cluster uses CephX). After this, all the VM data are migrated. For this step, however, the virtual machine must be turned off so that its data is immutable during the migration:
qemu-img convert -f raw -O rbd /dev/drbd/by-res/vm-ubuntu-amd64-alice rbd:libvirt/ubuntu-amd64-alice
Depending on the speed of the local block storage, this could take a few minutes. When finished, libvirt still needs to learn to use RBD now instead of the old block devices, which means modifying the previous entry so that it ultimately looks like Listing 2.
Listing 2: VM Storage as RBD
<disk type=’network’ device=’disk’>
<driver name=’qemu’ type=’raw’ cache=’writeback’/>
<source protocol=’rbd’ name=’libvirt/ubuntu-amd64-alice’>
<host name=’192.168.133.111’ port=’6789’/>
<host name=’192.168.133.112’ port=’6789’/>
<host name=’192.168.133.113’ port=’6789’/>
</source>
<target dev=’vda’ bus=’virtio’/>
<address type=’pci’ domain=’0x0000’ bus=’0x00’ slot=’0x05’ function=’0x0’/>
</disk>Note that, in the example shown, the IP addresses must be replaced with the actual IP addresses of the available MON servers. Incidentally, it makes sense to load the file in an editor, via virsh edit ubuntu-amd64-alice, because libvirt will then automatically parse the file and immediately apply the changes.
The above example also uses the RBD cache feature to provide additional performance within the VM via write-back mode. By following the steps described here, the VM can be booted as usual; differences compared with a “non-RBD VM” are non-existent. Anyone who runs this kind of setup with Pacemaker can then remove the block device from the Pacemaker configuration.
Libvirt with CephX
Somewhat more complicated is a design using Libvirt and RBD if the cluster uses CephX. In this case, libvirt must also log in to Ceph as a regular client to gain access to the data. Libvirt 0.9.12 or later can handle CephX, but the setup is not very intuitive. The following example is based on the assumption that a user named libvirt exists in Ceph and that the matching keyring exists in /etc/ceph/keyring.libvirt. Libvirt internally stores passwords with UUID designations, which means first issuing uuidgen at the command line to generate a UUID; in this example, it is 46d801da-7f82-4fa4-92cd-a19e6999d2e6.
First, create a file called ceph.xml with this content:
<secret ephemeral=”no” private=”no”>
<uuid>46d801da-7f82-4fa4-92cd-a19e6999d2e6</uuid>
<usage type=”ceph”>
<name>client.libvirt secret</name>
</usage>
</secret>Follow this with:
virsh secret-define ceph.xml
Ceph then creates a password entry in /etc/libvirt/secrets (Figure 3). What’s missing is the actual key that libvirt needs for this password. The appropriate command is:
virsh secret-set-value 46d801da-7f82-4fa4-92cd-a19e6999d2e6 `ceph-authtool \ --name client.libvirt --print-key /etc/ceph/keyring.libvirt`
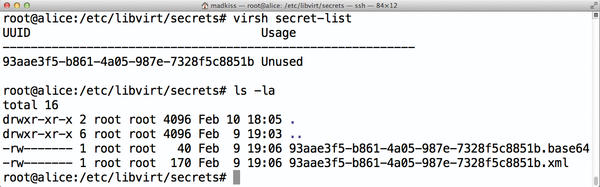 Figure 3: Libvirt pursues a somewhat quirky strategy for Ceph passwords and stores them in /etc/libvirt/secrets.
Figure 3: Libvirt pursues a somewhat quirky strategy for Ceph passwords and stores them in /etc/libvirt/secrets.
The command uses ceph-authtool to read the the correct key for the user client.libvirt and associates it with the UUID created in libvirt’s internal password database. The VM XML configuration still needs to be extended to use a key for access to Ceph. Instead of the command used in the previous example, run
virsh edit ubuntu-amd64-alice
to modify the VM, as shown in Listing 3. After doing so, the libvirt and RBD team works perfectly with CephX.
Listing 3: XML Configuration for the VM
<disk type=’network’ device=’disk’>
<driver name=’qemu’ type=’raw’ cache=’writeback’/>
<auth username=’libvirt’>
<secret type=’ceph’ usage=’client.libvirt secret’/>
</auth>
<source protocol=’rbd’ name=’libvirt/ubuntu-amd64-alice’>
<host name=’192.168.133.111’ port=’6789’/>
<host name=’192.168.133.112’ port=’6789’/>
<host name=’192.168.133.113’ port=’6789’/>
</source>
<target dev=’vda’ bus=’virtio’/>
<address type=’pci’ domain=’0x0000’ bus=’0x00’ slot=’0x05’ function=’0x0’/>
</disk>The Case of the SSDs
Anyone who is into storage will, sooner or later, face the question of how to eke out more performance from the existing hardware. Although a typical Ceph cluster out of the box already performs much better than classic block storage, because Ceph parallelizes write and read operations, there are some Ceph tweaks you can try. Admins report external proof-of-concept installations in which the individual nodes are connected via a bonded 10Gb network, and data transfer rates of 2Gbps are the order of the day. However, even with a legacy Gigabit network, you can still increase Ceph’s performence. A recommendation repeatedly found on the web is to store the OSD journals on SSDs.
I’ll take a little excursion into the internal workings of Ceph to find out. Each OSD has its own journal – a kind of upstream cache – where the data for the OSDs are first deposited. Ceph deems a client-side write operation complete when the data to be written has reached the journals of the number of OSDs envisioned in the replication settings. This setup makes one more thing clear: The faster the journal writes are completed, the faster the storage cluster is. By default, OSDs store their journals themselves, but the configuration settings also let you enable external journals (Figure 4). It’s only logical, then, to put the journals on fast SSDs – or is it?
A snag results from the typical hardware for Ceph storage nodes. Often these are servers with 12 slots for disks that house two SSDs and 10 normal SATA drives. The SSDs house the system itself and the OSD journals. Three nodes of this type result in a Ceph cluster. If one of the three nodes fails, Ceph is left with no option but to distribute the contents of a total of 10 OSDs across the remaining OSD. This causes a fair amount of random I/O, which even the SSD drives are not capable of handling. Because the system (and that also means the Ceph MON servers) also runs on the SSDs, timeouts occur on the latter, causing them to drop the connection to the other remaining MON. The cluster loses its quorum and declares itself to be inoperable – the storage system no longer works.
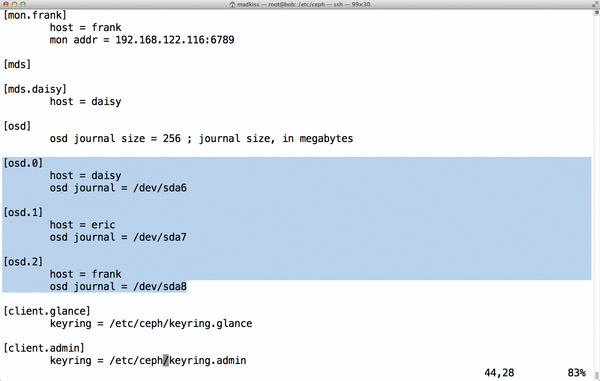 Figure 4: For each OSD, you can also specify a separate block device for the journal – normally a partition on an SSD. Some caution is required to prevent OSD failures paralyzing the MONs.
Figure 4: For each OSD, you can also specify a separate block device for the journal – normally a partition on an SSD. Some caution is required to prevent OSD failures paralyzing the MONs.
This effect can be worked around in several ways. On the one hand, it is generally a good idea to operate MON servers on machines that are not OSDs themselves. This ensures that the MONs go on working independently of the amount of I/O on the OSD servers. Another practical solution is limiting the maximum number of OSDs per host. The effect described here disappears almost entirely if you only need to distribute the content of six OSDs across the remaining cluster nodes. Ultimately, in scenarios of this kind, it makes sense to restrict the use of the SSDs to the system and allow the OSDs to store their journals themselves. It might sound odd, but in a setup like the one described here, SSDs can, in the worst case, do more harm than good. One thing is thus certain: The hardware of a Ceph setup must be planned carefully.
New in Bobtail
The developers released Ceph 0.56, code-named “Bobtail,” in January 2013, promising the user vastly improved performance. In terms of the configuration file, there are some CephX-related changes: whereas in Ceph 0.47 you needed to enable CephX with a single line in the configuration file,
auth supported = cephx
Bobtail now uses three entries:
auth cluster required = cephx auth service required = cephx auth client required = cephx
First benchmarks show that the new version offers superior performance in many ways compared with its predecessor. However, individual users have posted reports on various lists of more problems with RBD and Ceph 0.56. Now that both the Ceph filesystem and the RBD module are part of the Linux kernel and follow the kernel development cycle, the Ceph developers always recommend a kernel update in case of problems, especially since many Ceph and RBD patches have found their way into Linux 3.2. If you want to use Ceph in a production environment, you should thus get used to the idea of regular kernel updates, at least for the time being. In the next installment, I'll talk about Ceph maintenance.
Ceph vs. Gluster
A memorable event took place at the end of January at Linux.conf.au 2013 in Canberra, Australia. On stage, Sage Weil, as the Ceph Mastermind, and John Mark Walker, as the Gluster Community Lead, held a lively debate for almost one hour on the relative advantages and disadvantages of the two approaches. It goes without saying that the discussion was not always deadly serious. Nevertheless, both sides convincingly explained their positions. If you are interested in learning more about distributed storage, you will not want to miss the video of the Linx.conf.au event.
The Author
Martin Gerhard Loschwitz works as a Principal Consultant at hastexo on high-availability solutions. In his spare time, he maintains the Linux cluster stack for Debian GNU/Linux.