
Effectively monitoring your cluster can be one of the keys to understanding how the hardware and software are interacting. In many cases, this means examining the performance of a single node.
Monitor Your Nodes with collectl
Once you have a cluster operating, typically the next thing you want to do is monitor the cluster. For example, are all the compute nodes operating correctly? Is the network and storage operating correctly, as well as other components?
A second task that many people find themselves performing on cluster nodes is diagnosing or debugging problems. These problems can be related to software or hardware or an interaction of both. One of the most popular tools for this is called sar. Although sar has been around for a long time and is fairly well known to Linux administrators, it is lacking in some areas. In particular, it lacks the ability to monitor common HPC systems such as InfiniBand and Lustre. Plus, it lacks some of the tools for post-processing data. These two features are fairly important to HPC, so it would be nice to have a tool that could do what sar does – as well as monitor the HPC-specific systems that are important – and easily allow post-processing of the data. One tool that can do this is collectl.
Introduction to collectl
Collectl is a Perl code set that grabs as much detail as possible from the /proc filesystem. Although a number of tools do this, collectl has some capabilities that sar does not have. A collection of supporting tools can also help collectl gather and post-process data.
Collectl is easy to install if Perl is already installed on your system. In the HPC world, this means Perl must be installed on all the compute nodes you want to monitor. You can download the noarch RPM from the collectl website, or you can grab the source tar file – it’s up to you (Note: “noarch” means the RPM is not dependent on a specific architecture, such as 32-bit x86 or 64-bit x86). It’s very easy to install either with the RPM or from source. The collectl utilities are just as easy to install with a similar noarch RPM or from source. Be sure to watch for the RPM dependencies, particularly the tool called ColPlot, because it uses Apache (web server) and gnuplot to plot the results.
To start, I’ll assume you have collectl installed. It’s very easy to see whether it is working by running a simple command:
[laytonjb@localhost COLLECTL]$ collectl waiting for 1 second sample... #<--------CPU--------><----------Disks-----------><----------Network----------> #cpu sys inter ctxsw KBRead Reads KBWrit Writes KBIn PktIn KBOut PktOut 3 1 1421 2168 0 0 41000 90 0 2 0 0 3 2 1509 2198 64 2 49712 109 0 2 0 0 3 2 1403 2192 0 0 37928 84 0 1 0 0 3 1 1405 2170 0 0 52272 114 0 0 0 0 1 0 1267 2125 0 0 6152 14 0 0 0 0 2 1 1371 2104 0 0 42024 92 0 0 0 0 8 6 2173 2574 0 0 216276 474 0 7 1 14
If you are seeing output from collectl, then it is working correctly. To stop running collectl, just use ^c (Ctrl+C). When this particular example was created, I was running an IOzone test, which is why you are seeing lots of write data (the column labeled KBWrit).
collectl Measurements
At this point, you have collectl running, so you should start thinking about two things: (1) What can collectl measure? (2) What do I want to measure? The first question is fairly straightforward and just takes time, effort, and some reading. The second question is much more important, but I’ll delay answering that question for a bit. In the meantime, I’ll look at what collectl can measure.
If you try to understand collectl in one go, you will likely feel overwhelmed because it has a very large number of options. The easiest way to think about it is to remember that it measures different aspects of the system in two ways: in “brief” mode and in “detailed” mode. Brief mode is really a summary of the particular aspects being measured. For example, if you have a system with more than one core, then measuring the CPU usage in brief mode means you get an aggregate view of CPU usage for all CPUs in the system. The same is true for measuring disk performance, network performance, and so on.
In addition to brief mode, detailed mode allows you to dig into the details of the individual parts that make up the brief measurement. In the case of measuring CPU usage in detailed mode, collectl captures usage for all CPUs individually and presents this to the user – this is also true for disks, networks, and so on.
Collectl allows you to do both brief and detailed measurements at the same time (a very handy feature). Table 1 lists the brief categories that can be measured.
Table 1: Aspects Measured in “brief” Mode
| Option | Description |
|---|---|
| b | Buddy information (memory fragmentation) |
| c | CPU information |
| d | Disk |
| f | NFS information |
| i | inode information |
| j | Interrupts |
| l | Lustre |
| m | Memory |
| n | Networks |
| s | Sockets |
| t | TCP |
| x | Interconnect |
| y | Slabs |
Notice how all of the options for brief mode are lowercase. Table 2 lists the aspects that can be measured in detailed mode.
Table 2: Aspects Measured in “detailed” Mode
| Option | Description |
|---|---|
| C | CPU |
| D | Disk |
| E | Environmentals via ipmitool |
| F | NFS data |
| J | Interrupts |
| M | Memory node data (including numa) |
| N | Networks |
| T | Sixty-five TCP counters (only in plot format) |
| X | Interconnect |
| Y | Slabs |
| Z | Processes |
Notice how all of the options for detailed mode are uppercase.
By default, collectl uses the options cdn – CPU, disk, network – in brief mode. To specify the system options you are to measure, you use the -s option. Additionally, you can add and subtract options with the -s option. For example, you could use -s+YZ, which measures the detail cdn and adds the detailed slab option (Y) and the detailed processes (Z).
A great number of other options that go along with collectl determine how the data is collected and how often (possibly important), but understanding what is being measured with the brief and detailed options is very important.
One very important thing not to forget is that collectl collects statistics on the basis of sub-systems. Each sub-system has a number of variables that are measured. Mark Seger, the developer of collectl, has grouped these variables into sub-systems in an effort to make it easier for people to use collectl.
What Are You Measuring?
The most difficult aspect of monitoring is encapsulated in the question: What should I be measuring? This question does not have one right answer – it all depends on what you are trying to learn; what problems, if any, are you trying to solve; and, perhaps most importantly, the intended function of the node.
For example, what would you measure on a compute node? The primary function of a compute node is to compute, so perhaps watching disk performance isn’t that useful unless your nodes do a great deal of local I/O. But measuring CPU and memory usage are very important, maybe even at the detailed level. If the cluster is running MPI codes, then perhaps measuring the interconnect (x for brief mode and X for detailed mode) is important. This could also include Lustre if you are using it in your cluster, as well as InfiniBand. Something else to consider is measuring environmentals, such as temperatures, fan information, and power usage, which are especially good if you have an overheating node or a node you think is throttling down because of heat.
If you have an NFS server, you might want to monitor it with collectl and the f option for brief information or the F option for detailed information. If you are using NFS on the compute nodes and think that NFS is fairly important to the function of the nodes, you can easily monitor it with the use of these options because they capture NFS client statistics.
The point is that collectl can measure a great number of things, but you need to decide what you want to measure depending on the function of a particular node. Although this is conceptually easy to do, it is notoriously difficult to implement in practice because many people just give up and monitor everything, which creates a great deal of possibly unnecessary data that can put a strain on storage or I/O across the network.
collectl in Practice
Now that you know what collectl can measure and what you should think about when deploying it on a cluster, I’ll look at some quick examples of using collect on a single node so you can get a feel for how it works and how you can use it.
The tests were run on my home test system:
- Scientific Linux 6.2
- 2.6.32-220.4.1.el6.x86_64 kernel
- GigaByte MAA78GM-US2H motherboard
- AAMD Phenom II X4 920 CPU (quad core)
- 8GB of memory (DDR2-800)
- The operating system and boot drive are on an IBM DTLA-307020 (20GB drive at Ultra ATA/100)
- /home is on a Seagate ST1360827AS
- A 64GB Intel X-25E SSD, courtesy of Intel is mounted as /dev/sdd
- ext4 filesystem with the default options
- Open MPI v1.5.4
- NAS Parallel Benchmarks 3.3.1-MPI
- GNU compilers with SL6.2 (4.4.5)
- collectl v3.6.1 (installed optional compression packages)
- IOzone
I used collectl in daemon mode and modified one line in /etc/collectl.conf by adding a little to the default statistics monitored. The line in /etc/collectl.conf is:
DaemonCommands = -f /var/log/collectl -r00:00,7 -m -F60 -s+YZCD --iosize
These options allow me to monitor CPU, disk, and network in brief mode, and slab, processes, and disk in detailed mode. Plus, I added the ability to monitor iosizes.
Then I ran the NAS Parallel Benchmarks and IOzone one at a time with some time between tests so I had good gaps in the data and knew the times when code actually ran. The following list contains the approximate times I ran the code:
- lu.B.4: 13:56–13:50
- lu.C.4: 14:07–14:23
- bt.B.4: 14:45–14:48
- bt.C.4: 14:54–15:05
- ft.B.4: 15:13–15:15
- IOzone (sequential read and write): 15:36–15:45
The first five tests are specific benchmarks in the NAS Parallel Benchmark suite. The last test is an IOzone. The specific IOzone command used is:
./IOzone -i 0 -i 1 -s 16G -r 16M > output_16M.txt
This IOzone command line is a simple sequential read and sequential write test using 16MB record sizes to a file that is 16GB in size (twice the physical memory).
Once the testing was complete, I grabbed the raw collectl data file and copied it into a directory for post-processing (the file is named localhost-20120310-133840.raw.gz). The data was processed with collectl to create plot files for the various subsystems such as CPU, disk, and so on. The exact command is:
% collectl -p localhost-20120310-133840.raw.gz -P -f ./PLOTFILES -ocz
The -p option tells collectl to “play back” the data or, literally, to run the data back through collectl, and it takes as an argument the name of the raw file. The -P option tells collectl to create plot files. The -f option tells collectl to use a specific directory in which to place the output (I created a subdirectory called PLOTFILES, where I stored the plot files). The option -ocz tells collectl to open the plot files in create mode, which means it will overwrite existing files with the same name. The -z option tells collectl not to compress the plot files (I wanted to look at the files). To give you an idea of what plot files look like, here is the top part of the CPU plot file (I’ve tried to make this easier to read with a few carriage returns).
################################### RECORDED ################################### # Collectl: V3.6.1-4 HiRes: 1 Options: -D Subsys: bcdfijmnstYZCD # DaemonOpts: -f /var/log/collectl -r00:00,7 -m -F60 -s+YZCD --iosize ################################################################################ # Collectl: V3.6.1-4 HiRes: 1 Options: -p localhost-20120310-133840.raw.gz -P -f ./PLOT -ocz # Host: localhost DaemonOpts: # Distro: Scientific Linux release 6.2 (Carbon) Platform: GA-MA78GM-US2H # Date: 20120310-133840 Secs: 1331404720 TZ: -0500 # SubSys: bcdfijmnstYZCD Options: cz Interval: 10:60 NumCPUs: 4 NumBud: 3 Flags: ix # Filters: NfsFilt: EnvFilt: # HZ: 100 Arch: x86_64-linux-thread-multi PageSize: 4096 # Cpu: AuthenticAMD Speed(MHz): 2812.629 Cores: 4 Siblings: 4 Nodes: 1 # Kernel: 2.6.32-220.4.1.el6.x86_64 Memory: 7540044 Swap: # NumDisks: 2 DiskNames: sdb sda # NumNets: 2 NetNames: lo: eth0:100 # NumSlabs: 201 Version: 2.1 # SCSI: DA:1:00:00:00 DA:2:00:00:00 CD:4:00:00:00 ################################################################################ #Date Time [DSK:sdb]Name [DSK:sdb]Reads [DSK:sdb]RMerge [DSK:sdb]RKBytes [DSK:sdb]Writes [DSK:sdb]WMerge [DSK:sdb]WKBytes [DSK:sdb]Request [DSK:sdb]QueLen [DSK:sdb]Wait [DSK:sdb]SvcTim [DSK:sdb]Util [DSK:sda]Name [DSK:sda]Reads [DSK:sda]RMerge [DSK:sda]RKBytes [DSK:sda]Writes [DSK:sda]WMerge [DSK:sda]WKBytes [DSK:sda]Request [DSK:sda]QueLen \[DSK:sda]Wait [DSK:sda]SvcTim [DSK:sda]Util 20120310 13:39:10 sdb 0 0 0 2 4 24 12 0 12 2 0 sda 0 0 0 0 0 0 0 0 0 0 0 20120310 13:39:20 sdb 0 0 0 1 3 17 12 0 27 8 1 sda 0 0 0 0 0 0 0 0 0 0 0 20120310 13:39:30 sdb 0 0 0 0 0 0 0 0 0 0 0 sda 0 0 0 0 0 0 0 0 0 0 0 20120310 13:39:40 sdb 0 0 0 0 0 0 0 0 0 0 0 sda 0 0 0 0 0 0 0 0 0 0 0 20120310 13:39:50 sdb 4 0 97 1 2 11 21 0 5 5 2 sda 0 0 0 0 0 0 0 0 0 0 0 20120310 13:40:00 sdb 83 91 3518 2 4 23 42 1 7 6 54 sda 0 0 0 0 0 0 0 0 0 0 0 20120310 13:40:10 sdb 136 93 6483 2 8 40 47 2 17 7 90 sda 0 0 0 0 0 0 0 0 0 0 0 20120310 13:40:20 sdb 60 69 2200 2 11 52 36 2 30 6 37 sda 0 0 0 0 0 0 0 0 0 0 0 20120310 13:40:30 sdb 2 0 16 7 37 175 21 1 59 6 5 sda 0 0 0 0 0 0 0 0 0 0 0
Notice that the file is remarkably easy to read (and therefore to write simple utilities to parse the data).
Once the files were processed, I wanted to plot them. This where I used one of the collectl-utilities named ColPlot.
Colplot
Colplot is a simple web-based program that takes some predefined plots, uses gnuplot to create the plots, and then presents them to you in a web page. The tool is pretty easy to use and allows you to look at the plot files quickly to zero in on the time spans of interest.
Installing collectl-utilities is very straightforward. You can use the noarch RPM from the collectl-utilities URL, or you can install it easily from source. Before you install it, be sure you have Apache installed, as well as gnuplot. Because ColPlot is web based, you need a web server; hence, the need for Apache. If you install from the noarch RPM, I still recommend you grab the source TAR file, uncompress it, and untar it. In the directory, you will see a file named INSTALL-colplot. Be sure to read this file, but remember that parts of the file are geared toward HP’s tool set, so you just need to be aware of where things are installed on your system. If you installed from the noarch RPM, most everything should be installed in the right places.
After you have installed collectl-utilities – but before restarting Apache – take a look at the file /etc/colplot-apache.conf, which contains all of the defaults for ColPlot. In particular, it defines where you should put the plot files for ColPlot to read (by default, it is /usr/share/collectl/plotfiles).
Once you have everything set, just open a webpage to the URL: 127.0.0.1/colplot. Notice that I used my localhost 127.0.0.1 – you can use the host address of your system instead, but you have to be able to resolve the system name. If everything works correctly, you should see something like Figure 1 on the web page.
 Figure 1: Colplot Start Screen
Figure 1: Colplot Start Screen
Now you can click on some of the options and create some plots!
Back to Examples
Now I’ll go back to examining the results from running a NAS Parallel Benchmark case and IOzone, but now I’m going to use ColPlot to examine the results.
The first thing I did was examine the results for the lu.C.4 run (lu benchmark, class C, four processors). Figure 2 shows a screen capture of the resulting web page from ColPlot, with which I plotted the CPU statistics in both brief and detailed mode.
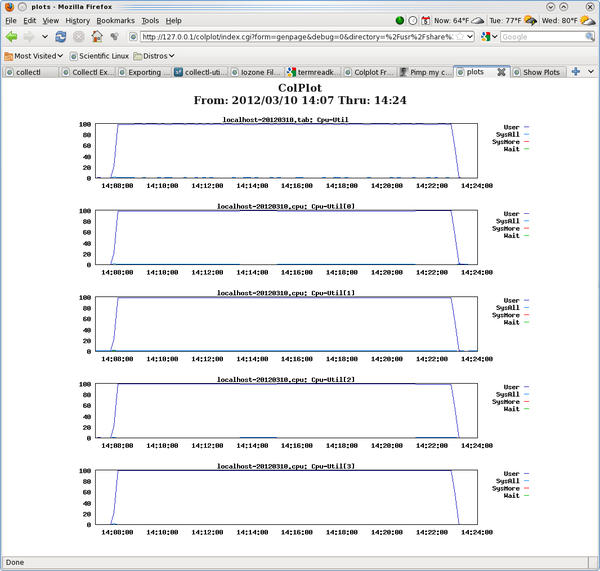 Figure 2: Colplot screen capture for plotting CPU statistics in brief and detailed mode for the lu.C.4 test.
Figure 2: Colplot screen capture for plotting CPU statistics in brief and detailed mode for the lu.C.4 test.
Note that I adjusted the time on the ColPlot definition screen, so I could zero in on the data in Figure 2.
In this particular example there isn’t a great deal to see: You can see that all four CPUs (0 to 3) are at 100% utilization during the run because the “user” time is at 100%. One would expect this with the lu benchmark because it’s so computationally intensive and was run on four cores. But this example is really just intended to show you how you can use collectl to grab the statistics and plot them fairly quickly.
The second test I examined was the IOzone test because I wanted to see how collectl grabbed both brief and detailed data for the disks. Note that during the IOzone test, only one device was being used by IOzone, but it was being used heavily. Figure 3 plots the brief and detailed views of the disk subsystem as collected by collectl.
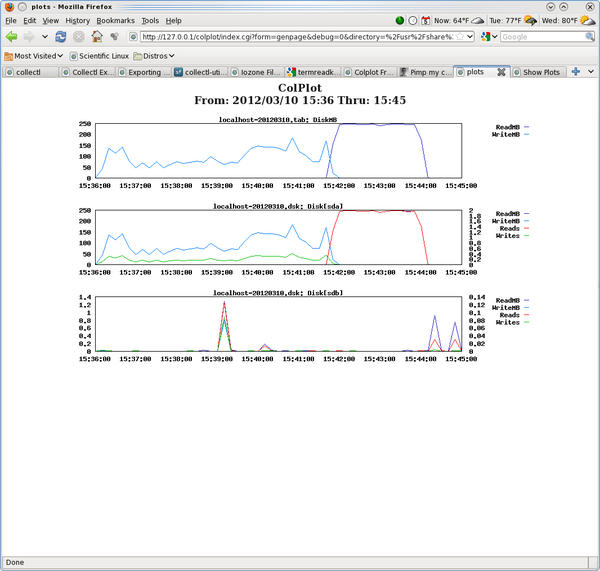 Figure 3: Colplot screen capture for the disk subsystem performance while running IOzone.
Figure 3: Colplot screen capture for the disk subsystem performance while running IOzone.
Again, for this plot, I zeroed in on the time frame over which the test ran. I then chose to plot both the brief disk view and the detailed disk view.
Because the system contains two disks, sda and sdb, ColPlot plots statistics for both disks in the detailed view. But if you take a look at the y-axis of both plots, you will see that sda is doing an order of magnitude more I/O than sdb because IOzone is using sda, whereas sdb is the system disk.
In the second plot down, you can see when IOzone is doing the write testing: The blue line shows the write throughput (in MBps), and the green line is the number of write function calls. Then, you can see the read testing by the red line, which is the number of read function calls. The read throughput (MBps) is actually behind the red line, so it’s difficult to see.
Summary
Gathering statistics on compute nodes can be painful, particularly if you are debugging. Although you can use sar, many times it lacks the features you want or need. Plus, it doesn’t always have the utilities to manipulate data, so you end up having to write your own.
Collectl makes the task of gathering node statistics a bit easier by grabbing lots of information from the /proc filesystem, and it has a range of capabilities for examining the resulting data. An additional set of utilities can help, including ColPlot for plotting data.
This article is intended to be a gentle introduction on how to get started with collectl, a very powerful tool with a huge number of options that helps ease the burden of gathering statistics. If you have found sar lacking, particularly for HPC systems, take a look at collectl. Start by using it to watch your own desktop while running various jobs. Then, examine the other options in collectl and its associated tools to monitor the system aspects in which you are interested. However, don’t forget the most important point: Think about the purpose of the node you are monitoring and what you want to monitor.