
The world is swimming in data, and the pool is getting deeper at an alarming rate. At some point you will have to migrate data from one set of storage devices to another. Although it sounds easy, is it? We take a look at some tools that can help.
Moving Your Data – It’s Not Always Pleasant
I’m sure that almost everyone reading this article has, at some time in their life, moved from one place to another. This involves packing all of your possessions, putting them in some sort of truck, driving them to the new location, unloading them, and ultimately unpacking everything. I’ve done it several times in my life and, to me, it’s neither fun nor pleasant. One of my friends loathes moving so much that he has threatened just to sell or give away everything and buy new things for his new home. Honestly, I’m not far from his opinion, but at the same time, it’s always interesting to see what you have accumulated over the years and, perhaps more interestingly, why you have kept it.
I think the same thing is true for data storage. At some point you’re going to need to move the data from your existing storage solution to a new one, for any number of reasons. Perhaps your current storage solutions will get old and fall out of warranty. Perhaps you need additional capacity and can’t expand your current storage. Regardless, at some point, you’re going to have to migrate your data from one storage solution to another. Of course, another option is just to erase (burn) all of the data on your existing storage solution.
Approach
I recently went to the Lustre User Group conference (2013), and I was impressed with a presentation by Marc Stearman from Lawrence Livermore National Laboratory. The title of his talk was “Sequoia Data Migration Experiences.” Sequoia is a large petascale system with 55PB of storage running Lustre on top of ZFS and reaching about 850GBps. Marc talked about moving data from their older systems to Sequoia and some of the issues they faced (it wasn’t easy). His talk inspired me to examine tools that can be used to migrate data.
Among the many ways to migrate data are a block-based approach, in which you copy a set of blocks using something like a snapshot, or even a Copy-on-Write (COW) filesystem that writes the data to a new storage solution. These approaches need to be planned very carefully because you’re using a set of blocks rather than individual files; however, they can simplify the process, particularly in preserving metadata, although it is dependent on the hardware for the old and new storage.
The other approach, and the one that I will use in this article, is file based. In this approach, files are migrated with the use of a variety of tools and techniques. File-based migration is more prevalent because it’s easier to track what is migrated. On the other hand, it can be more difficult because you handle each file individually.
I talked to a number of people at various HPC centers about data migration, and I found two general approaches to migrating data via files. The first approach is fairly simple – make the users do it. The second option is to do it for the users.
With the first option you let the users decide what data is important enough to be migrated. You have to give them good, tested tools, but the point is that the users will move data that they deem important. The general rule of thumb is that users will keep all of their data forever, but one site in particular told me that they have found users don’t necessarily migrate all of their data. (Sending the Google vernacular: "+1" to their users.) However, I’m not always this optimistic, partly because I still have files from 1991 on my system and files from the late 1980s on floppy disks (once a pack rat, always a pack rat).
With the second approach – doing the migration for the users – migrating data takes a bit more planning and even a bit of hardware. The first thing you need to understand is the “state” of the data on your current storage. How much of it is changing and which user directories are being used actively? You should also examine the data files for permissions, ownership, time stamps, and xattr (extended attributes). To make your life easier, you can also mount the older data as read-only so you can copy it over without fear of it changing (Stearman ran into this problem).
Ultimately what you want is a list of files (full path) that can be migrated safely, along with the attributes that need to be preserved. Be sure to run some tests before migrating the data, so you don’t lose any attributes or even any data.
Data migration can succeed under many possible hardware configurations; Figure 1 shows a somewhat generic configuration.
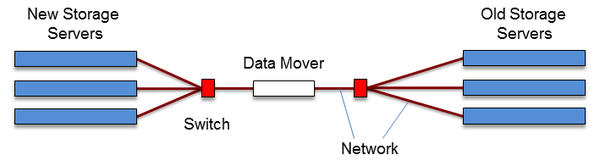 Figure 1: Generic data migration layout.
Figure 1: Generic data migration layout.
On the right is the old old storage configuration, which has one or more data servers connected to a switch (red box). The new storage is on the left, with one or more new data servers connected to a switch. In between the two switches is a single data mover. The function of the data mover is to be the conduit between the old and new storage solutions and effectively “move data.” You can have as many of these as you want or need.
The simplest way to move data is to make the data mover a client of the old storage system and a client of the new storage system, although this might not be possible because of conflicting software requirements; however, you can always use a TCP/IP network and a server to NFS-export the storage to the data mover. Then, you just copy the data between mountpoints. For example:
[laytonjb@mover1 ~]$ cp -a --preserve=all -r /old_storage/data /new_storage/data
Be warned that if you use NFS, you will lose all xattr information because no NFS protocol can transfer it. In this case, you might have to use something else (see below).
This simple example has many variations. For example, you could skip the data mover and just NFS-export the storage from an old storage data server and mount it on a data server on the new storage, but I think you get the basic concept that somehow you have to be able to move data from one storage system to the other.
Software Options
A number of tools can be used to migrate data, ranging from common tools, to those that are a bit rough around the edges, to tools that might not be able to transfer file attributes. Some are easier to use than others, but all of them potentially can be used to migrate data, depending on your requirements.
To begin, I’ll examine the first, and probably most obvious, tool that comes to mind: cp.
1. cp
In the simple layout in Figure 1, the most obvious way to migrate data is simply to use the data mover to mount both storage solutions. Then, you just use cp between the mountpoints, as demonstrated in the cp command above. It’s all pretty straightforward, but you need to notice a few things.
As I mentioned earlier, if either one of the storage solutions is NFS-mounted on the data mover, you will lose all of your xattr data. There is a way around this problem, but it’s not easy and involves scripting. The script reads the xattr data from the file on the old storage and stores it in some sort of file or database. The cp command then copies the file from the old storage to the new storage. On the new storage, you need to “replay” the xattr data from the file or database for the file, and you have effectively copied the xattr. If you take this approach, be sure to test the script before applying it to user data.
Also notice that I used the -a option with the cp command. This option stands for “archive,” and it will do the following:
- Copy symbolic links as symbolic links
- Preserve all of the attributes (mode, ownership, timestamps, links, context, xattr) because I used the --preserve=all option. If you don’t use this option, it will default to mode, ownership, and timestamps only.
- Recursively copy all files and directories in subtrees. I also specified this option with the -r option, but the archive option, -a, also invokes the recursive copy option as well. I use this option because it preserves all of the attributes, including SELinux ones (if you haven’t guessed, I’m using Linux for my examples).
If you use cp, you should realize that it is a single-threaded application. Consequently, it is not likely to saturate the network, which would be a waste of resources and take a very long time. If you have a nice data-mover server, you more than likely have multiple cores that aren’t really doing anything, so why not take advantage of them?
The easiest way to take advantage of the number of cores is to run multiple cp commands at the same time, either on specific files or specific subtrees (start at the lowest branch and work upward to root). This isn’t too difficult to script if you have a list of files that need to be migrated: just start a cp command on the data mover for each core. Because you’re a good HPC admin, you also know to use the numactl command to pin the process to the core, so you don’t start thrashing processes all over the place. Just write the script so that when a cp command is issued on a particular core, it grabs the next file that needs to be migrated (just split the list of files across the cores).
A second way to take advantage of the extra cores is to use a distributed file copy tool.
2. dcp
You’re an HPC person and you’re used to the power of many cores and many nodes, so why not use these cores to copy data? There is a project to do just this: dcp is a simple code that uses MPI and a library called libcircle to copy a file. This sounds exactly like what an HPC admin would do, right?
DCP uses a certain block size when doing the copy. For larger files, you actually have to change the block size in the dcp.h file and rebuild the code, but you could easily build the code with several different block sizes and name the executable something different (e.g., dcp_1KB, dcp_10KB, dcp_1MB, dcp_10MB, dcp_1GB). Then, in a script, you check the size of the file and use a version of DCP that allows you to split the file into a fair number of chunks.
For example, don’t use a 1MB version of DCP to copy a 1MB file. If you do, then only one process will be copying the file. Instead, divide the file size by the number of MPI processes and then divide that by the number 10 or larger (number of blocks transferred by each process). This should get you some reasonable performance. Also, note that by using dcp you don’t have to use parallel cp streams. The scripting can just be serial.
On the plus side, dcp is MPI based, so you can take advantage of IB networks for more performance. On the down side, dcp doesn’t transfer all attributes. In the documentation it says that it preserves the ownership, permissions, and timestamps. However, in Marc Stearman’s talk, he noted that these attributes are not yet implemented. However, dcp might be something to test to see if it meets your needs. You also might contribute something to the project, perhaps adding file attributes.
3. tar
Another tool you might not have thought too much about is tar. Although it’s not a data copy tool in itself, you can use it to gather up lots of small files into a single (.tar) file, copy it to the new storage system, and then untar the file once there. This can make data migration much easier, but you still have to pay attention to the details (see the “Recommendations” section below).
If you want to preserve all of the file attributes when using tar, you have to pay attention to which option(s) you are using. The options you may want to consider are shown in Table 1. Many of the options can be used with tar. I highly recommend you experiment with them to make sure that they do everything you want, especially options that affect xattr data. One note of caution: If you run the tar command on the old storage, be sure you have enough space to hold the .tar file. I also recommend you don’t run tar on the entire contents of the old storage because you could run out of space.
Table 1: tar Options
| Option | Description |
| -c | Create the tar file (starts writing at beginning of file). |
| -f [filename] | Specify the tar file name. |
| -v | Give verbose output that shows the files being processed. |
| -p | Preserve the file permission information (used when the files are extracted from the tar file). |
| --xattrs | Save the user/root xattrs to the archive. |
| --gzip: | Use gzip in the stream to compress the tar file. |
| --bzip2 | Use bzip2 to compress the archive (tar file). |
| --lzma | Use lzma to compress the archive (tar file). |
| --sparse | Handle sparse files efficiently (use if you have sparse files that are to go into the tar file). |
| --no-overwrite-dir | Preserve metadata of existing directories. Note that the default is to overwrite the directory metadata. |
| --selinux | Preserve the SELinux context to the archive (tar file). |
| --preserve | Extract information about the file permissions (the default for superuser). |
| --same-owner | Try extracting files with the same ownership as exists in the archive (default for superuser). |
| --acls | Save the ACLs to the archive. |
If you have tar working the way you expect, then you can just simply copy the .tar file from the old storage to the new storage using cp or something similar. Also, you can make tar part of a script in which youtar a smaller part of the overall directory tree, copy it to the new storage, untar it, and then checksum the new files. Then you can repeat the process. Note that this is a serial process and might not give you the performance you want, although you can do multipletar commands at the same time in a script.
However, this process may not be everything expected. Please read the “Recommendations” section for some ideas about how to use tar.
4. Mutil
An additional idea that some people have pursued is to multithread cp. This can be done by patching the standard Linux tools (GNU coreutils), and the Mutil project does exactly that – it modifies cp and md5sum to be multithreaded. In the words of the Mutil authors, it is intended to be used for local copies. This fits with the model in Figure 1, in which a data mover has both filesystems mounted so any data copying between mountpoints is essentially a local copy.
The current version of Mutil, version 1.76.6, is built against coreutils version 7.6. However, more recent Linux distributions, such as RHEL 6.x, use a newer version of coreutils, so it might not be easy to use an older version of coreutils on the data mover.
5. Rsync
One tool I haven’t talked about yet is rsync. It is something of the do-all, dance-all tool for synchronizing files, so in many cases, people reach for it automatically for data migration As with tar, rsync possesses a myriad of options (Table 2).
Table 2: rsync Options
| Option | Description |
| -l | Copy symlinks as symlinks. |
| -d | Transfer directories without recursion. |
| -D | Preserve device files (superuser only). |
| -g | Preserve groups. |
| -o | Preserve owner. |
| -t | Preserve modification times. |
| -v | Verbose (it’s always a good idea to use this option). |
| -p | Preserve permissions. |
| -X | Preserve xattrs. |
| -H | Preserve hard links. |
| -E | Preserve executability. |
| -A | Preserve ACLs. |
| -r | Recursive. |
| -a | Archive mode (same as -r, -l, -p, -t, -g, -o, and -D, but not -H, -A, and -X). |
| -S | Handle sparse files efficiently. |
| -x | Compress file data during transfer. |
| --compress-level=NUM | Explicitly set compression level. |
| -h | Output human-readable numbers. |
| --inplace | Update destination files in-place. |
Many of these options carry implications, so it is a good idea to experiment a bit before proceeding with any data migration. Be sure to pay attention to the attributes and how they are rsync’d to the new storage.
Earlier in the article, I mentioned Marc Stearman’s paper from LUG 2013, and he had some good observations about using rsync to migrate data from one storage system to another. He and his team found rsync to be very “chatty” as well as very metadata intensive (recall that they are migrating data from one storage solution to another, so it’s not synching files between two locations).
In their migration, they also found that when rsync migrates files, it first checks to see whether the file exists on the destination filesystem by opening it (a metadata operation). Then, it creates a temporary file, copies the data, and moves the temporary file into the correct location of the destination file. All of these steps are very metadata intensive. The --inplace option skips the temporary file step and writes the data to the file in the correct location on the destination storage. Depending on the number of files to be migrated, this can reduce the time because it reduces the effect on metadata operations.
Note that with rsync, you don’t necessarily need a data mover in between the old storage and the new storage. You just need at least one data server associated with the old storage and at least one data server associated with the new storage that are networked and able to “see” each other; then you can use rsync to copy the data to the new storage. Depending on the storage systems, it might be a good idea for the storage servers to be storage clients and not part of the storage solution. An example of this is Lustre, where you want the data servers to be a Lustre client rather than an OSS (Object Storage Server) server.
As far as I can tell, rsync has no formal parallel version, but lots of people want something like this (Google Summer of Code, anyone?). I have found a few articles that might help you use rsync in a parallel manner:
6. BitTorrent
BitTorrent is not just a tool for downloading illegal copies of digital media. It is in fact a peer-to-peer sharing protocol with some associated tools that use multiple data streams to copy a single file. By using multiple streams, it can maximize the network bandwidth, even if they are relatively slow individually. Also, it supports parallel hashing, wherein the integrity of each piece can be verified independently and the file checked once it arrives to make sure it is correct.
What makes BitTorrent attractive is the ability to download files from multiple sources at the same time. This avoids the single-stream performance limit of tools like cp or rsync and is why it is so popular for uploading and downloading files from home systems that have really low network performance. The single-stream performance is fairly low, but there are so many participating systems that, in aggregate, the performance could be quite good.
If you want to copy a file from the old data storage to the new data storage using BitTorrent, you first have to create a torrent descriptor file that you use on the new data storage server(s). The data server(s) on the old storage act as a seed. The new data servers, acting as “peers,” can then download the file by connecting to the seed server(s) and downloading it. You just need a network connection between the seed servers and the peers. You can also scale the performance by adding more servers (seeds and peers) attached to the old storage, as well as more BitTorrent clients. With a centralized filesystem, scaling the file server portion of the exchange shouldn’t be a problem because each node has access to the data (centralized filesystem).
A file for downloading is split into pieces, and each piece can be downloaded from a different BitTorrent server (seed or peer). The pieces are hashed so that if the files are corrupted, it can be detected. The pieces are not downloaded in some sequential order but a somewhat random order, with the BitTorrent client requesting and assembling the pieces.
On the software side, you need a BitTorrent server on each of the seed nodes (old data servers) and a BitTorrent client on each of the peer servers and pure client servers. Servers and clients are available for many operating systems and many distributions. Figure 2 shows a very simple BitTorrent layout for data migration.
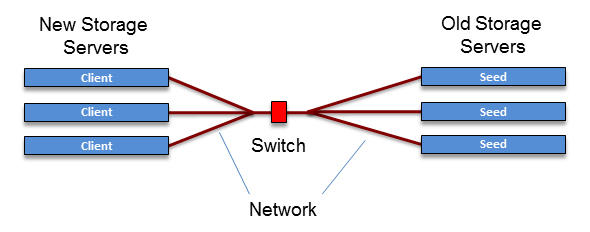 Figure 2: BitTorrent Layout
Figure 2: BitTorrent Layout
In this layout, I’ve chosen to go a slightly different route and make each data server on the old storage a seed server, so it will be serving a particular file and no other server will provide for it by creating the correct torrent files. On the new storage are BitTorrent clients that request the files. All of the files that need to be migrated from the old storage are given to the new storage servers. It’s fairly easy to split the file list between the clients so that you don’t waste time recopying the files.
There are many ways to create a BitTorrent network to migrate files. I have not tested using any, so I don’t know if it can also copy over file attributes, but to be honest, I don’t believe it can. If this is true, then you will need a way to recreate all of the attributes on the transferred files.
Very recently it was announced that BitTorrent had begun alpha testing a new “sync” tool. BitTorrent Sync allows you to keep files between various servers in sync. The new tool also offers one-way sync, which could help in data migration. Keep an eye out for BitTorrent Sync because it could be a huge benefit to data migration.
7. bbcp
Other tools floating around can handle multistream data transfers. One of them, bbcp, can transfer files between servers using multiple streams and do recursive data transfers as well. As with other tools, bbcp has several options, and the main page describes them in a fair amount of detail. A web page at Cal Tech also describes bbcp in more detail and includes some network tuning parameters to improve performance.
Bbcp has the ability to compress data during transfer (--compress), do a recursive transfer (--recursive), and preserve some metadata (--preserve). However, the bbcp main page mentions that the --preserve option only preserves the source file’s mode, group name, access time, and modification time. If your data has xattr metadata associated with it, you will lose that data if bbcp is used. However, you can always write a script to go back and add the xattr information.
One limitation of bbcp is that it can’t migrate directories by themselves. Additionally, I have not tried bbcp, so I can’t say too much about how to set it up and use it, but it sounds promising if your data files have no xattr information.
8. bbFTP
Although bbFTP sounds like it’s related to BBCP, it’s really not. BBCP was developed at SLAC, and bbFTP was developed at IN2P3. It is something like FTP, but it uses its own transfer protocol optimized for large files (greater than 2GB). Like BBCP, it works with multiple streams and has compression and some security features. One version is even firewall and NAT friendly.
However, bbFTP does not appear to have a way to retain file attributes, including ownership, mode, timestamps, and xattrs. It is just a simple FTP tool designed for high file transfer rates over FTP (and that’s not a bad thing – it just might not be the best option for data migration).
9. GridFTP
Probably the most popular FTP toolkit for transferring data files between hosts is GridFTP, which is part of the Globus Toolkit and is designed for transferring data over a WAN. Recall that Globus Toolkit is designed for Computing Grids, which can comprise systems at distances from one another. GridFTP was designed to be a standard way to move data across grids.
GridFTP has some unique features that work well for moving data:
- Security – Uses GSI to provide security and authentication.
- Parallel and striped transfer – Improves performance by using multiple simultaneous TCP streams to transfer data.
- Partial file transfer – Allows resumption of interrupted downloads, unlike normal FTP.
- Fault tolerance and restart – Allows interrupted data flows to be restarted, even automatically.
- Automatic TCP optimization – Adjusts the network window and buffer sizes to improve performance, reliability, or both.
Using GridFTP can be challenging because you have to use a number of pieces of Globus on both the old storage and the new storage. However, a version of GridFTP, GridFTP-Lite, replaces GSI with SSH. This makes things a little easier because the security features might not be needed for data migration outside the data center, just within.
I have not tested GridFTP, so I’m not sure how well it would work for data migration. One concern I have is that if migration of attributes is important, including ownership, timestamps, and xattrs, then GridFTP might not be the best tool.
10. Aspera
Up to this point, I’ve focused on open source tools for data migration, but I believe one commercial tool is worthy of mention. Aspera has some very powerful software that many people have talked about using to transfer data. They use an algorithm called fasp to transfer data over TCP networks. I’ve talked to people who have said they can transfer data faster than wire speeds, probably because of data compression. Overall, these people are very impressed with Aspera’s performance.
Aspera offers synchronization with their tools. According to their website, they can “preserve file attributes such as permissions, access times, ownership, etc.” I don’t know if this means xattrs as well, but at least they can deal with POSIX attributes.
Recommendations
I’ve covered a number of tools and added comments about how the tools might be used to migrate data from an old storage solution to a new one. However, the most important thing is not necessarily the tool(s), but the planning and execution of the migration. I think it’s worthwhile to review some of the steps you should consider when migrating data.
The first, extremely important step – and I cannot emphasize this enough – is that you need to understand your data; that is, you need to understand the state of your data.
- How many files?
- What is the average number of files per user?
- How old is the oldest file based on the three timestamps (atime, mtime, ctime)?
- What is the average file age?
- How many files are added every day?
- How many files are deleted every day?
- How much capacity is added every day?
- How big is the largest file?
- What is the size of the smallest file?
- Which users have the most data and the largest number of files?
- Which user is creating the most data?
- What is the deepest subtree?
- How many levels does it have?
- How many users are on the system?
- Do files have xattrs or other associated attributes?
- How many directories are there?
- Do directories have associated xattrs?
Answering these questions, or being able to answer them, will make your life infinitely easier as you plan for data migration.
Once you have this information, you can then develop a plan for migrating data. In general, I would start with user data that hasn’t changed in a while but still needs to be migrated. You need to understand how the data is distributed through a user’s directory tree. Is most of the data near the bottom (it usually is), or is the data distributed throughout the tree? Understanding this allows you to plan for how to migrate the data.
For example, if most of the data is at the bottom of the tree, you will want to think about how to migrate the directory structure first and then use tar to capture the data at the lowest levels. The reason is because tar doesn’t understand directory structures, so if you untar it at the wrong level, you will have problems. Plus, you need to migrate the directories; otherwise, you can lose permissions, timestamps, links, owners, and xattr data. Don’t think you can just re-create the data structure on the new storage.
As part of this process, you will also likely need a list of files and directories in the user’s account. It’s just a simple list of the fully qualified name for the file. This list will be very important because many of the tools I have discussed can be fed a file name for data migration, and a list of files will allow you to parallelize the operations, improving throughput and reducing migration time.
Once you have identified the user with the least active data, you can then work through the list of users until you arrive to the most active users in terms of data manipulation. For each user, you need to go through the same steps you did with the least active user. Be sure to understand their tree structure and create a list of all files.
At this point you should have a pretty good time sequence for migrating the data, starting with the user with the least active data and progressing to the most active user; plus, you should have lists of files for each user that needs to be migrated. Now, you still need to determine just how to do the transfer, and you need to understand which tool(s) to use for the data migration to get the most throughput between the storage solutions and reduce migration time. This step could mean writing scripts, but it definitely means lots of testing.
To perhaps help you in your testing, I have two fundamental recommendations at this point: (1) Transfer the directories first, including any directory attributes; (2) create a dummy account and put in some dummy data for testing.
The first step is somewhat counterintuitive, but Stearman talked about it in his talk. By migrating the directory structure over first, you can migrate files further down the directory, without having to transfer everything at once. As I mentioned earlier, some of the tools don’t understand directory trees very well. For example, what if you created a tar file for the path /home/jones/project1/data1/case1 that is recursive. If you then copy over the tar file to the new storage and untar it in /home/jones, the data will be in the wrong place. To prevent this from happening, it greatly behooves you to migrate the directory structure over first. Just be sure to capture all the attributes for the directories.
My second recommendation, testing everything on a dummy account, seems obvious, but it gives you more feedback on the tools and processes than simply trying a single file. Also, don’t forget to test all of your procedures. Although this might seem obvious, sometimes the little things bite the worst.
Once you have tested with the dummy account, I would then test with a user that doesn’t have much data or hasn’t been using their account too much, and I would start migrating other user data and increase the rate of the transfer until the maximum throughput is hit.
Another observation that is tremendously obvious but easily forgotten is don’t allow users to modify data while it is migrating or once it has been migrated. Although this seems obvious, in practice, it can be a struggle. You might disable that person’s account during the migration or simply ask them to refrain from using the system. Once the data is migrated, you can then point them to that data and not the old location (you could simply rename their root directory, but be careful because this changes the file attributes on their root directory).
Regardless of the tool(s) you use, be sure to checksum the file before and after you migrate it to make sure they are the same, and you haven’t lost any data as a result. Even if the tool does the checksum check for you, I recommend doing it yourself. Only when you are satisfied that the checksums match should you mark the file as migrated or erase or otherwise modify the file on the old storage. I also recommend using something a little more sophisticated than md5sum. I personally like to use the SHA-2 series of checksums because there is less chance of a false positive. (I realize the chances aren’t very great with an md5sum, but I just feel better using SHA-2. But this is a personal preference.) Some of the tools use md5sum for their own file checksum checks.
My last suggestion is to check, check, check. You want to make sure the data on the new storage matches the data on the old server. It’s easy to write a simple script that walks the directories and gathers this information. Run the script on the old storage and the new storage and compare them. If they don’t match, you need to go back and fix it. This includes file checksums as well.
Summary
Storage is growing so fast that it’s like looking at your daughter when she’s five years old, blinking, and suddenly she’s 15. You need to keep your eye on the ball if you hope to manage everything. I’m not just talking about large systems, but medium-sized systems, small systems, workstations, and even your home systems.
At some point during this growth spurt, you will have to think about migrating your data from an old storage solution to a new one, but copying the data over isn’t as easy as it sounds. You would like to preserve the attributes of the data during the migration, including xattrs (extended attributes), and losing information such as file ownership or timestamps can cause havoc with projects. Plus, you have to pay attention to the same things for directories; they are just as important as the files themselves (remember that everything is a file in Linux).
In this article, I wanted to present some possible tools for helping with data migration, and I covered just a few of them. However, I also wanted to take a few paragraphs to emphasize that you need to plan your data migration if you want to succeed.
One thing I learned in writing this article is that there is no one tool that seems to do everything you want. You end up having to use several tools to achieve everything in an efficient manner. Plus, these tools are fairly generic, which is good because they can be used in many situations. At the same time, they might not take advantage of the hardware. A simple example is that all of these tools but one are TCP based, yet InfiniBand offers much greater bandwidth that can’t be fully utilized for data migration. You can definitely use IP over InfiniBand, and you will get greater bandwidth than not using it, but you still won’t be utilizing the entire capability of the network.
Anyone up for a project?