
Diving deeper into OpenMP loop directives for parallel code.
In the Loop
In the first article in this series, the focus was on creating teams and groups of threads and parallelizing a loop across them with OpenMP directives. Just two directives got you started porting your serial code to OpenMP. In this article, I’m going to go a little deeper into those two directives and talking more about teams and loops, including some options (called “clauses”) for the parallel loop directive. Other parallel loop clauses lend more flexibility, including help scheduling work for the threads in the team.
Revisiting Loops
The parallel directive creates a team of threads that defines a region of code to be parallelized; then, with OpenMP directives, you can split a do/for loop across the team. This construct is key for OpenMP parallelism, and a few directive clauses can be exploited to provide additional control and possibly additional performance.
Data and Control Parallelism
A quick review of the do/for OpenMP directive brings up some points that should be clarified. The use of directives to take serial regions of code and make them parallel, along with all of the cores (there are ways to restrict the number of cores), is the way to improve performance.
In Figure 1, the threads in the team that operate on the data are shown in green and are being used for “data parallelism.” However, you don’t have to use every thread in the team; instead, you can take one or more threads and use them to perform different functions. These special threads generally can be thought of as “control parallelism.” A simple example is using one thread for performing I/O while other threads are used for computation. These control threads are shown as blue, red, and yellow boxes in Figure 1. The combination of data and control parallelism results in a great deal of flexibility in porting your application to OpenMP.
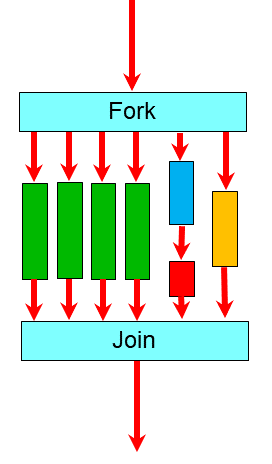 Figure 1: Data and control parallelism in OpenMP.
Figure 1: Data and control parallelism in OpenMP.
The one or two control threads allow you to overlap computation with I/O or other control-like functions, improving the overall parallelism of your application. Given that processors can have up to 64 cores, using one or two to allow your code to scale better is a great trade-off.
Although I won’t specifically discuss how to use data parallelism and control parallelism at the same time, as you port your code to OpenMP, look for opportunities where you might use a thread or two for a control function that would allow the remaining cores to be used for computation. Once you have your code ported to parallelize your loops, you can come back and revisit the use of control threads.
Teams and Loops
To improve the performance of your code, you want to parallelize loops as much as possible (i.e., split the work in the loop across as many threads as possible). With a single loop in the code, you can use a combination of directives (e.g., !$omp parallel do or #pragma omp parallel for) to parallelize the loops. The example in Listing 1 shows sets of loops one after the other, and Listing 2 shows how to parallelize each loop with the !$omp parallel do or #pragma omp parallel for directive.
Listing 1: Sets of Loops
| Fortran | C |
|---|---|
do i=1,n ... end do do j=1,m ... end do do k=1,n*m ... end do |
for (i=0; i < n; i++)
{
...
}
for (j=0; j < m; j++)
{
...
}
for (k=0; k < n*m; k++)
{
...
}
|
Listing 2: Parallelized Sets of Loops
| Fortran | C |
|---|---|
!$omp parallel do do i=1,n ... end do !$omp end parallel do !$omp parallel do do j=1,m ... end do !$omp end parallel do !$omp parallel do do k=1,n*m ... end do !$omp end parallel do |
#pragma omp parallel for
for (i=0; i < n; i++)
{
...
}
#pragma omp parallel for
for (j=0; j < m; j++)
{
...
}
#pragma omp parallel for
for (k=0; k < n*m; k++)
{
...
}
|
Between each loop directive, a team of threads is created (forked), and the data is copied to each thread. After computation, the threads are synchronized and destroyed (joined). This process has to be done for each loop, adding computational time that is not parallelizable and reducing performance and scalability. Ideally, you want to spend the minimum amount of time in fork and join operations as possible. For example, the code in Listing 3 illustrates how to reduce a series of loops into a single fork/join structure.
Listing 3: Single Fork and Join
| Fortran | C |
|---|---|
!$omp parallel !$omp for do i=1,n ... end do !$omp end do !$omp do do j=1,m ... end do !$omp end do !$omp do do k=1,n*m ... end do !$omp end do !$omp end parallel |
#pragma omp parallel
{
#pragma omp for
for (i=0; i < n; i++)
{
...
}
#pragma omp for
for (j=0; j < m; j++)
{
...
}
#pragma omp for
for (k=0; k < n*m; k++)
{
...
}
}
|
Here, the parallel and do directives are separated from each other (they don’t have to be together), which allows a single fork/join operation to encompass all of the loops, creating just one team creation step (fork) and one team synchronization and thread destruction step (join). Fewer fork/joins reduce run time and improves scalability.
Clauses with Reductions
When creating a team, you have several clauses (options) available for debugging or data control when the omp parallel directive is used. The form of the clauses for Fortran and C, respectively, are,
!$omp parallel <clauses> #pragma omp parallel <clauses>
where <clauses> can be any one (or more) of the following:
- copyin(<list>) allows all of the threads to access the master thread values in (<list>).
- copyprivate(<list>) specifies that one or more of the variables in (<list>) should be shared among all threads.
- default(shared|none) allows you to specify the default behavior in the parallel region. If you specify shared, then any variable in a parallel region will be treated as if it were specified with the shared clause. The option none means that any variables used in a parallel region that aren’t specified with private, share, reduction, firstprivate, or lastprivate will cause a compiler error.
- firstprivate(<list>) says each thread should have its own copy of the variable(s) specified in (<list>). In actuality, it gets a unique memory address in which to store values for that variable while it's used in the parallel region. When the region ends, the memory is released and the variables no longer exist.
- if (scalar_logical_expression), if true, evaluates the region in parallel; otherwise, a single thread is used.
- lastprivate causes the last value of a specified variable to be used after the parallel region.
- nowait overrides the barrier that is implicit in a directive, including the implicit join at the end of a parallel region.
- num_threads allows you to specify the number of threads in the team.
- ordered is required if a parallel do or parallel for statement uses an ordered directive in the loop.
- private(<list>) tells the compiler that each thread should have its own instance of a variable. You can specify a <list>of variables that are to be private.
- reduction(operator:<list>) is an important clause for scientific code specifying that one or more variables private to each thread can be used for a reduction operation at the end of a parallel region. Classic operators, including addition (+), subtraction (-), maximum (max), minimum (min), and multiplication (*), are available. Other operations (e.g., logical operators) also can be used.
- schedule(<type>[,<size>]) applies to work schedules for the parallel do or parallel for loop directives.
- shared(<list>) allows you to specify that one of more variables in <list> are to be shared among all of the threads.
As you can see, a number of clauses give you a great deal of freedom. Rather than focus on all of them, I will only discuss a few that I've found useful and a few that can be confusing.
default
The default clause is probably one of the best debugging clauses, because it allows you to specify the behavior of unscoped (undefined) variables in a parallel region. In particular, default(none) requires you to define every single variable in the parallel region as private or shared. If you introduce a new variable in the parallel region and don’t define it, the compiler will give you an error, requiring you to define it in a directive clause. Compare this is with the implicit none command in Fortran.
firstprivate and lastprivate
Although I really don’t use these two clauses in my coding, they can be confusing, so I’ll talk about them a bit. Be definition, firstprivate means that each thread should have its own instance of a variable (memory location) and should be initialized with a value right before the parallel region.
In practice, firstprivate means that each thread will start with a variable that has the same value (rather than starting as 0). The variable can be changed by each thread as needed. During the join process after the parallel region, the variable on the master thread returns to its value before the parallel region.
The lastprivate clause means that threads during the fork phase get the same value, which can be changed in the parallel region. During the join phase, the master thread sets the value of the variable to whichever thread executes the final iteration (think of a do/for loop) or the last section (I haven’t discussed sections thus far in OpenMP).
The firstprivate and lastprivate clauses are best illustrated with an example, which I base on code by Michael Lindon (Listing 4). If you run the code as written with the private() clause, you’ll see the output in Listing 5.
Listing 4: private() Example
| Fortran | C |
|---|---|
program main
use omp
integer :: i
integer :: x
x = 44
!$omp parallel for private(x)
do i=1,10
x = i
write("Thread number: ", omp_get_thread_num()," x: ",x)
end do
write(*,*) "x is ",x
end program main
|
#include
#include
#include
int main(void){
int i;
int x;
x=44;
#pragma omp parallel for private(x)
for (i = 0; i <= 10; i++) {
x = i;
printf("Thread number: %d x: %d\n", omp_get_thread_num(), x);
}
printf("x is %d\n", x);
}
|
Listing 5: private()Output
Thread number: 0 x: 0 Thread number: 0 x: 1 Thread number: 0 x: 2 Thread number: 3 x: 9 Thread number: 3 x: 10 Thread number: 1 x: 3 Thread number: 1 x: 4 Thread number: 1 x: 5 Thread number: 2 x: 6 Thread number: 2 x: 7 Thread number: 2 x: 8 x is 44
Notice that the value of x varies for the threads, but the final value after the parallel region is still 44. The final value was not changed by the threads because it is a private variable for each thread.
Next, I’ll switch private() to firstprivate() (Listing 6). Recall that firstprivate specifies that each thread should have its version of the variable (independent from all others) initialized before the start of the parallel region. After the parallel region, the variable is returned to its original value, 44.
Listing 6: firstprivate() Output
Thread number: 2 x: 6 Thread number: 2 x: 7 Thread number: 2 x: 8 Thread number: 1 x: 3 Thread number: 1 x: 4 Thread number: 1 x: 5 Thread number: 0 x: 0 Thread number: 0 x: 1 Thread number: 0 x: 2 Thread number: 3 x: 9 Thread number: 3 x: 10 x is 44
Finally, I’ll switch firstprivate to lastprivate (Listing 7). The value of x after the parallel region (join) is the last iteration – in this case, 10.
Listing 7: lastprivate() Output
Thread number: 0 x: 0 Thread number: 0 x: 1 Thread number: 0 x: 2 Thread number: 3 x: 9 Thread number: 3 x: 10 Thread number: 2 x: 6 Thread number: 2 x: 7 Thread number: 2 x: 8 Thread number: 1 x: 3 Thread number: 1 x: 4 Thread number: 1 x: 5 x is 10
Be careful as you use shared, firstprivate, and lastprivate in your code. As illustrated in this example, you canget results you might not expect.
nowait
One important topic in parallelism is synchronization. As threads compute separately, they might at some time need to share information or all reach the same point before proceeding. Synchronization gives you control over how the threads run their assigned work, focusing on performance and correctness by telling the threads to process in a certain order.
OpenMP always has an implicit barrier when a parallel region ends (the join), which provides synchronization because all threads finish at the same time. The nowait clause allows you to cancel this implicit barrier effectively and can be particularly effective if one parallel loop is followed by several more and the threads don’t depend on each other. However, you have to be very careful about how the threads share data, or you can get wrong answers.
For example, assume a thread has finished a loop that has been defined with the nowait clause. The thread doesn't stop at the end of the parallel do/for and is destroyed at the end of the parallel loop. If that thread had any data that was needed by the other threads (e.g., for I/O), the data is not available, and you will get incorrect answers. Generally, this is called a “race condition.”
However, if you are absolutely sure you won't get a race condition, nowait allows the threads to run as fast as they can. An example taken from Microsoft documentation (Listing 8) illustrates how to do this. The output from the Fortran version of the code compiled with GCC is shown in Listing 9.
Listing 8: nowait Example
| Fortran | C |
|---|---|
program test5 integer :: a(5), b(5), c(5) integer :: i integer :: SIZE SIZE = 5 do i=1,SIZE a(i) = i-1 enddo call test(a, b, c, SIZE) do i=1, SIZE write(*,*) a(i),' ',b(i),' ',c(i) enddo end program test5 subroutine test(a, b, c, SIZE) integer :: SIZE integer :: a(SIZE), b(SIZE), c(SIZE) integer :: i !$omp parallel !$omp do nowait do i=1,SIZE b(i) = a(i)*a(i) enddo !$omp do nowait do i=1,SIZE c(i) = a(i)/2 enddo !$omp end parallel return end subroutine test |
// omp_nowait.cpp
// compile with: /openmp /c
#include <stdio.h>
#define SIZE 5
void test(int *a, int *b, int *c, int size)
{
int i;
#pragma omp parallel
{
#pragma omp for nowait
for (i = 0; i < size; i++)
b[i] = a[i] * a[i];
#pragma omp for nowait
for (i = 0; i < size; i++)
c[i] = a[i]/2;
}
}
int main( )
{
int a[SIZE], b[SIZE], c[SIZE];
int i;
for (i=0; i<SIZE; i++)
a[i] = i;
test(a,b,c, SIZE);
for (i=0; i<SIZE; i++)
printf_s("%d, %d, %d\n", a[i], b[i], c[i]);
}
|
Listing 9: nowait Output
0 0 0 1 1 0 2 4 1 3 9 1 4 16 2
All commutations in the code use integers. The first column is the number, the second column is the square of the number, and the third column is half of the number. The results are correct, but be very sure to check the code. Because the arrays have no data dependencies, there is no chance of a race condition in the parallel region.
Be absolutely sure nowait does not cause a race condition. Run your code without it and then try running your code with it. If you get different answers, nowait has highlighted a race condition. You should remove the nowait clause and either try to find the race condition or just don’t use it.
reduction
A common operation in high-performance computing is a reduction, which generally is a loop that takes an array and reduces it to a single number. A simple example is searching for the maximum value in an array (i.e., max()). The OpenMP standard includes a reduction() clause for use in do/for loops to parallelize the reduction.
The general form of the clause is:
reduction(operator:list)
The operator can be arithmetic (e.g., +, -, *, max, min) or logical operators in C and Fortran. A simple example (Listing 10) computes the average of an array. In the reduction() clause, the variable avg is automatically declared private and initialized to zero (although in the example, I explicitly initialize it to 0.0). The sum of the array is computed in avg and then divided by the number of elements in the array to compute the average outside the parallel loop.
Listing 10: reduction() Operation
| Fortran | C |
|---|---|
program test6 use omp_lib integer :: N = 1000 real, allocatable :: x(:) real :: avg_base, avg integer :: i allocate(x(N)) do i=1,N x(i) = real(i)*sin(real(i)) enddo avg_base = 0.0 avg = 0.0 do i =1,N avg_base = avg_base + x(i) enddo write(*,*) 'avg_base = ',(avg_base/N) !$omp parallel private(id) !$omp do reduction(+:avg) do i=1,N avg = avg + x(i) enddo !$omp end do !$omp end parallel write(*,*) 'avg = ',(avg/N) end program test6 |
#include
#include
#include
#include
#define N 1000
int main( )
{
float x[N];
int i;
float avg_base, avg;
for (i = 0; i < N; i++)
{
x[i] = i * sin(i);
}
avg_base = 0.0;
avg = 0.0;
for (i = 0; i < N; i++)
{
avg_base = avg_base + x[i];
}
avg_base =avg_base / N;
printf("avg_base = %f\n",avg_base);
#pragma omp parallel private(i)
{
#pragma omp for reduction(+:avg)
for (i = 0; i < N; i++)
{
avg = avg + x[i];
}
}
avg = avg / N;
printf("avg is %f\n", avg);
}
|
This simple example illustrates how to define a reduction in a parallel region. Look for loops that produce a single number or just a small number of results. These regions could be targets for the use of a reduction() clause.