Distributed Linear Algebra with Mahout

The Apache Mahout distributed linear algebra framework delivers new tools and methods for performing data analysis, building machine learning data pipelines, and implementing machine learning models in production.
The ideal scenarios for using Apache Mahout are in teams with the flexibility to adapt as their needs change over time. Mahout can easily swap back-end compute engines (e.g., batch or micro-batch systems such as Apache Spark) or streaming systems (e.g., Apache Flink). Additionally, Mahout is able to perform compute on multiple software and hardware systems, ranging from the Java Virtual Machine (JVM), to whatever multicore CPU is available, to on-board GPU for high-volume parallel computation.
Typical users of Mahout are advanced data engineers and data scientists who have experience writing transformations and models in other languages but who are looking for an approach that does not require they rewrite their work, depending on the system they use from month to month or year to year. Moreover, mathematics-oriented software engineers will enjoy the simplified Samsara domain-specific language (DSL), which provides a stripped-down syntax that feels natural to people accustomed to writing with math notation, avoiding the usual "syntax bloat" that most machine learning libraries require.
Apache Mahout – What Is It?
Apache Mahout is a library designed to make composing and maintaining distributed linear algebra algorithms easy. First, it creates an abstraction layer on the underlying engine (the open source version of Mahout uses Apache Spark as an engine), and the abstraction layer implements basic linear algebra functions on datasets in the engine (e.g., by defining a distributed matrix, matrix multiplication, multiplication with self transposed, and other functions). Second, it uses Samsara DSL in Scala, which allows users to define algorithms with an R-like syntax that makes it much easier to write, and later read, complex mathematical formulas.
Mahout has a rich history and was one of the (if not the) original machine learning libraries for big data. Originally designed to aid in machine learning tasks on data in Apache Hadoop clusters, it underwent a major refactoring around 2014-2015 that resulted in its current form. One challenge this restructuring creates is the abundance of information in circulation that refers to the “old” Hadoop-based Mahout.
Machine learning sometimes refers to a set of techniques for numerically solving problems that are too large for standard statistical approaches. Mahout gives you tools to solve those problems with tested statistical approaches. Mahout can be applied to any "big data" platform (e.g., any platform on which users are running distributed data sets) and can pay dividends if your company has critical algorithms of concern for refactoring into machine learning approaches.
Distributed Linear Algebra
Linear algebra, otherwise known as matrix math, is a rich and established field of theoretical and applied mathematics that has found applications across multiple spheres of computer science and software engineering, including visual simulations, audio analysis, and predictive analytics. In some cases it can be arithmetic-heavy, with methods built up in iterative or bulk activity, and at scale these computations can become either overly cumbersome or complicated to program on distributed systems.
Fortunately, Apache Mahout abstracts away many of the complexities and pitfalls of distributed linear algebra, leaving a tidy library for working with distributed linear algebra as though it were simply normal linear algebra.
For example, in Figure 1, the original matrix A and its transpose AT are sliced into independent and corresponding rows and columns, which then can be sent across to a compute engine to perform small chunks of arithmetic. The results are then compiled together for a single output.
Figure 1: A conceptual illustration of the way Mahout approaches matrix multiplication of matrix A with its own transform.
In mathematics, complex procedures are normally the product of many simpler procedures. Mahout takes advantage of this by introducing an engine abstraction layer, in which someone who is an expert in the underlying engine will implement performant ways to do basic operations like multiplying two matrices, multiplying a matrix times itself transposed, and other operations.
Figure 2 shows the application layers at the top, with multiple engines transparently managing the distribution of computation for the user. The advantage of this approach is that the end user, the person implementing the algorithms, doesn’t have to know all of the peculiarities of a specific engine. In fact, the person writing the algorithms doesn’t even need to know what the underlying engine is.
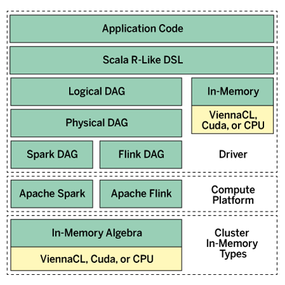
Figure 2: Architectural diagram of an engine abstraction layer.
Samsara: The Scala DSL
The end user interfaces with Samsara Scala DSL, which makes it much more pleasant and natural for mathematicians and the writers of algorithms to implement mathematics with the help of an interesting Scala feature that allows users to change syntax and language rules for a particular use case. For example, the computation below, which is used in Mahout's distributed stochastic principal component analysis (dsPCA), when written with mathematics notation here,
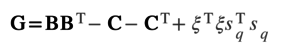
is written with Samsara as shown in the first line of Listing 1. The lines that follow are more examples of typical statements exercising Samsara syntax. You can find more information about Samsara online.
Listing 1: Samsara Syntax Examples
val G = B %*% B.t - C - C.t + (xi dot xi) * (s_q cross s_q) // Dense vectors: val denseVec1: Vector = (1.0, 1.1, 1.2) val denseVec2 = dvec(1, 0, 1, 1, 1, 2) // Sparse vectors: val sparseVec1: Vector = (5 -> 1.0) :: (10 -> 2.0) :: Nil val sparseVec1 = svec((5 -> 1.0) :: (10 -> 2.0) :: Nil) // Dense matrices: val A = dense((1, 2, 3), (3, 4, 5)) // Sparse matrices: val A = sparse( (1, 3) :: Nil, (0, 2) :: (1, 2.5) :: Nil ) // Diagonal matrix with constant diagonal elements: diag(3.5, 10) // Diagonal matrix with main diagonal backed by a vector: diagv((1, 2, 3, 4, 5)) // Identity matrix: eye(10) // Plus/minus: a + b a - b a + 5.0 a - 5.0 // Hadamard (elementwise) product: a * b a * 0.5 // Operations with assignment: a += b a -= b a += 5.0 a -= 5.0 a *= b a *= 5 // Dot product: a dot b // Cross product: a cross b // Matrix multiply: a %*% b // Optimized right and left multiply with a diagonal matrix: diag(5, 5) :%*% b A %*%: diag(5, 5) // Second norm, of a vector or matrix: a.norm // Transpose: val Mt = M.t // Cholesky decomposition val ch = chol(M) // SVD val (U, V, s) = svd(M) // In-core SSVD val (U, V, s) = ssvd(A, k = 50, p = 15, q = 1) // EigenDecomposition val (V, d) = eigen(M) // QR decomposition val (Q, R) = qr(M)
Engine Agnosticism (and Why It Matters)
Engine agnosticism is important to many organizations, many of whom don’t even realize it. In just the 2000s clusters have moved from Hadoop to Spark, and from Spark to Kubernetes. Teams and organizations often find themselves in an uncomfortable position of being pinned to outmoded technology, rather than bringing in costly consultants to port business-critical algorithms and methods from an old system to a new.
The Mahout project lived through the migration from Hadoop to Spark and incorporated the lessons learned into its very fabric, making it simple to port algorithms from any arbitrary platform to any other (Figures 3 and 4).
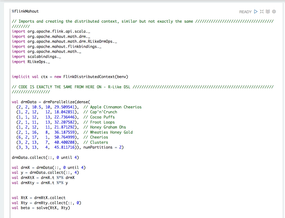
Figure 3: Matrix math with the Apache Flink engine.
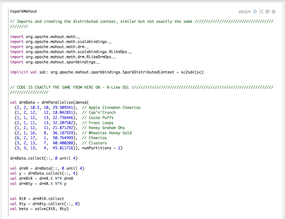
Figure 4: Matrix math with the Apache Spark engine.
Note that the code after the import statements requires no changes. Therefore, a team that uses one back-end engine is able to migrate code onto another engine, without having to change the code performing the mathematical operations and avoiding the more error-prone part of porting code from one platform to another.
Mahout Use Cases
Mahout is for organizations who have statistical methods to run on distributed datasets but want to minimize their exposure to the technical debt that arises from writing algorithms against a specific engine that may or may not have a successful future. Mahout allows organizations to switch their systems of record while having a minimal effect on their data outputs.
Mahout also lets users add linear algebra concepts to data stores that have either weak or nonexistent implementations for linear algebra concepts, such as Apache Spark. (Spark’s linear algebra works fine in single-node deployments but has issues scaling to larger distributed data sets.)
Mahout in the Wild
A major used car marketplace in North America used the Mahout codebase when creating their car recommendation system. This recommendation engine is based on Mahout’s Correlated Cross-Occurrence (CCO) analysis. The CCO algorithm is very similar to the more popular co-occurence (CO) algorithm, but it also incorporates other attributes of the user into its recommendations; in more technical parlance, it is multimodal.
Mahout has been used in many situations where customer privacy and intellectual property concerns keep them from being published, but many researchers and practitioners have built recommenders, similarity engines, and other predictive models at scale with the use of its tools.
A paper written by T. Grant illustrates another Mahout use case. During the outset of the COVID pandemic, CT scans were shown to be as good as, or in some cases superior to, RT-PCR tests. A major issue however was the high dose of radiation they delivered. With Mahout, Grant showed how “noisier,” “low-dose” CT scans could be quickly and easily de-noised, with about five lines of Mahout code.
Getting Started With Mahout
Mahout can be added to your project by adding it as an Apache Maven dependency, by running a prebuilt Docker image, or by downloading a binary or a source build from the project website. To get involved with the project as a user or contributor, subscribe to user@mahout.apache.org and dev@mahout.apache.org mailing lists (instructions online). For some alternative methods for installing and using the software, including a prebuilt Docker image, see the slide presentation at SlideShare.
Tags:
![]() Apache ,
Apache , ![]() linear algebra ,
linear algebra , ![]() Mahout
Mahout