OpenACC Directives for Data Movement

The OpenACC data directive and its associated clauses allow you to control the movement of data between the host CPU and the accelerator GPU.
OpenACC was designed with accelerators in mind, with the host CPU and the accelerator device each having their own memory. In my previous article, I showed how to use OpenACC loop directives to off-load regions of code from a host CPU to multicore CPUs or an attached accelerator device (e.g., GPU) for parallelizing your code. In this article, the accelerator is presumed to be a GPU, but it doesn’t have to be.
OpenACC Memory Layout
CPU memory is almost always greater than GPU memory, although the GPU memory has much more memory bandwidth than the host memory. Separating these two memory pools is an I/O bus, commonly a PCIe bus. Any data transferred between the CPU and GPU goes over the PCIe bus, which is relatively slow compared with memory bandwidth. Most importantly, neither the CPU or the GPU can do any computation until all the data is in memory.
OpenACC accommodates the accelerator being a multicore CPU. For this case, the host memory and the accelerator memory are the same (shared memory), so there is no need to manage memory because it’s already in the same pool.
For the case where the accelerator has its own memory, data needs to be migrated between the CPU and the GPU (accelerator) memory. In the case of a multicore processor, the accelerator is the same as the host and the accelerator memory is the same as the host memory.
CUDA-Managed Memory
In general, OpenACC is designed for a host and an accelerator device, each with different memories, which means the user has to manage moving data to and from the accelerator, as shown in Figure 1. To make things easier, OpenACC compilers have adopted the Unified Memory approach. Fundamentally, this means that a pointer can be dereferenced from either the CPU or the GPU. In non-CS-speak, this means that the accelerator memory and the host memory appear as one pool of memory to the application.
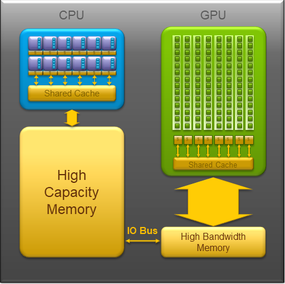
Figure 1:OpenACC memory view (from OpenACC.org).
With unified memory, you do not need to worry about specific data movement and can code assuming that the data will be on the accelerator when needed. In the background, the compiler handles the data movement between the host and the GPU, which is generically referred to as CUDA Unified Memory.
When unified memory is used in an application, the compiler makes the decisions about when and how to move data from the host to the accelerator and back. It retires pages of data from the accelerator memory to the host memory according to usage. However, it may be useful for the data to stay on the accelerator because it will be used in subsequent parts of the code that is running on the accelerator. Although OpenACC-compliant compilers improve the automatic data movement of unified memory with every new version, the compilers are unlikely to know as much about the code as the programmer. Therefore, OpenACC has directives for data movement.
Note that for the case of the “accelerator” being additional cores on the CPU, the memory is already unified (i.e., there is only one pool of memory). Therefore, you can just use unified memory and not worry about data movement.
Introduction to Data Clauses
OpenACC has a data directive that tells the compiler to create code that performs specific data movements and provides hints about data usage. Table 1 shows the data directive as it is used in C and Fortran.
Table 1: The data Directive
| Fortran | C |
!$acc data |
#pragma acc data |
The directive is acc data. The five clauses I look at in this article that can combine with the data directive are:
- copy
- copyin
- copyout
- create
- present
Their names describe their obvious functions. The specific data clause combined with the acc data directive constitutes the start of a data region (Table 2). In C, the beginning and end of the data region is marked with {curly braces}. In Fortran, the data region begins with the data directive and has another directive to specify the end of the data region. In subsequent sections, I briefly discuss each of the clauses.
Table 2: Data Regions
| Fortran | C |
!$acc data (clause) .. !$acc end data |
#pragma acc data (clause)
{
...
}
|
copy
The first data clause, copy, copies data to and from the host and accelerator. When entering the data region, the application allocates accelerator memory and then copies data from the host to the GPU. When exiting the data region, the data from the accelerator is copied back to the host. Table 3 shows a simple example of using the copy clause.
Table 3: The copy Clause
| Fortran | C |
!$acc data copy(a) !$acc parallel loop do i=1,n a(i) = 0.0 enddo !$acc data end |
#pragma acc data copy(a)
{
#pragma acc parallel loop
{
for (int i=0; i < n; i++)
{
a[i] = 0.0
}
}
}
|
The entire array a is copied from the host to the accelerator with the acc data copy directive. The loop then is run on the accelerator by the acc parallel loop directive. After the loop is finished, the array a is copied from the accelerator back to the host courtesy of the acc end data directive for Fortran or the closing curly brace for C. OpenACC allows you to combine directives into a single line, so you could write the previous code as shown in Table 4.
Table 4: Combining Directives
| Fortran | C |
!$acc parallel loop copy(a) do i=1,n a(i) = 0.0 enddo |
#pragma acc parallel loop copy(a)
{
for (int i=0; i < n; i++)
{
a[i] = 0.0
}
}
|
In Fortran, you no longer have to use an end data directive. The copy data clause ends where the parallel loop directive ends, which is implicit after the loop. In the case of C, combining directives on one line means you don’t need to use additional curly braces to define the data region, saving some typing and coding.
copyin
The next data clause, copyin, allocates memory on the accelerator and copies data from the host to the accelerator when entering the data region indicated by the directive (Table 5); however, it does not copy the data back to the host on exiting the data region. This directive is typically used when you want to copy data to the device, but you don't need the data to be copied back out because it hasn’t changed. Classically, this is used for “input” data to the OpenACC region.
It is important to note that the data moved by the copyin clause is left in the GPU memory. No definition in the OpenACC specification says what happens to that data when the data region is exited. You could explicitly delete this memory in a data directive with the delete clause (not covered in this article), or you could just leave it.
Table 5: The copyin Clause
| Fortran | C |
!$acc parallel loop copy(a) copyin(b) do i=1,n a(i) = b(i) enddo |
#pragma acc parallel loop copy(a) copyin(b)
{
for (int i=0; i < n; i++)
{
a[i] = b[i]
}
}
|
Because array b is not needed after it is moved into the accelerated region, the parallel loop copyin directive just copies into the parallel region, but not out. For this example, I use the copyin directive for array b and the copy directive for array a.
Although I could have used the copy clause for b, because I don't need it afterward, I can save some data movement and make the overall code a little faster and a little more scalable. (Lots of small performance gains equal big performance gains.)
copyout
The third data clause, copyout, allocates memory on the accelerator when entering the accelerated region but only copies data from the accelerator to the host when exiting the OpenACC data region (Table 6). No data is copied from the host to the accelerator. This directive is classically used only to return data from a directive region to the host; that is, it is just “output” from an accelerated region.
Table 6: The copyout Clause
| Fortran | C |
!$acc parallel loop copyin(a, b)
copyout(c)
do i=1,n
c(i) = a(i) * b(i)
enddo
|
#pragma acc parallel loop copyin(a, b)
copyout(c)
{
for (int i=0; i < n; i++)
{
c[i] = a[i] * b[i]
}
}
|
A subtlety to note for this example is that you can put multiple variables in a single data movement clause (the five discussed in this article). This example uses copyin(a, b) to copy both arrays into the accelerated region. You don't have to put all variables into a single directive, but it sometimes helps to save space and typing, thus reducing errors. Just be careful that you either end each data region with the acc end data directive in Fortran or a closed curly brace in C.
create
The fourth data clause, create, allocates memory on the accelerator when the accelerated region is entered and deallocates the memory when the accelerated region is exited (Table 7). No data is copied to or from the host and the accelerator. Because the data is local to the accelerator, you can think of it as temporary.
Table 7: The create Clause
| Fortran | C |
!$acc parallel loop copyin(a, b, e)
create(c) copyout(d)
do i=1,n
c(i) = a(i) * b(i)
enddo
do j=(n/2),n
d(j) = c(j) - e(j)
end do
|
#pragma acc parallel loop copyin(a, b, e)
create(c) copyout(d)
{
for (int i=0; i < n; i++)
{
c[i] = a[i] * b[i]
}
for (int j=(n/2)+1; j < n; j++)
{
d[j] = c[j] - e[j]
}
}
|
For this example, the arrays a, b, and e are copied into the accelerated region but are not used after that, so the copyin clause is used. Array d is copied from the accelerated region to the host after computations are finished, but it is not copied into the accelerated region. Therefore a copyout clause is used.
Array c is only used in the accelerated region. It is allocated when entering the accelerated region and deallocated when leaving the accelerator region. It is not copied to or from either the host or the accelerator; therefore, the create clause is used.
This example is very, very simple. Although you could write it with one loop so you wouldn’t have to create a local array on the accelerator, this example just illustrates how you could do so.
present
To help the compiler produce better code, the present clause in a data directive makes the compiler check whether the data is on device (Table 8). If it isn't, the execution will abort.
Table 8: The present Clause
| Fortran | C |
!$acc data copyin(a, b) copy(c)
!$acc parallel loop
do i=1,n
c(i) = a(i) * b(i)
enddo
...
!$acc parallel loop copyin(e)
present(a) copyout(f)
do j=1,n
f(i) = 2.0*e(j) +
(1.0/4.0)*(a(j)*4.14)
end
!$acc end data
|
#pragma acc data copyin(a, b) copy(c) {
#pragma acc parallel loop {
for (int i=0; i < n; i++)
{
c[i] = a[i] * b[i]
}
}
...
#pragma acc parallel loop copyin(e)
present(a) copyout(f) {
for (int j=0; j < n; j++)
{
f[i] = 2.0*e[j] + (1.0/4.00*(a[j]*4.14)
}
}
}
|
In this simple code, the data region is defined around the two parallel loop directives. The data directive copies the a and b data into the accelerator memory but doesn't expect it to be copied back to the host when exiting the data region. It also copies c into the accelerator memory, where it is probably operated on in some way; then, the data is copied back to the host when exiting the data region.
After the parallel region, perhaps some code is executed on the host (e.g., some I/O), during which it is assumed that arrays a and b are not changed. After the sequential region, a second parallel region is encountered, in which array e is copied into the device memory (the copyin clause), and f is created on the device and copied out when exiting the region (the create clause). However, you don’t need to copy a into the device memory because it’s already there, courtesy of the present clause: The present(a) clause tells the compiler to look for a in the device memory.
Array Shaping
In the examples so far, the entire array has been used in the OpenACC data directive and clauses. The OpenACC standard allows you to use just portions of arrays in the data clauses, referred to as “array shaping,” in which you tell the compiler the size of the arrays so it can generate the best possible code (Table 9).
Table 9: Array Shaping
| Fortran | C |
!$pragma acc data copyin(a(1:size)),
copyout(b(s/4:3*s/4))
|
#pragma acc data copyin(a[0:size-1]),
copyout(b[s/4:3*s/4])
|
You can use reasonably complex expressions to determine the portion and size of the array to use. In this way, you give the compiler more information to create better accelerator code.
Array shaping can also be used for arrays starting with different indices (e.g., 1 for C or 0 for Fortran). For entire arrays, you can decide whether to define the bounds or not. Purely for code documentation – for those who might touch the code in the future – it is probably a good idea to include the array bounds.
Derived Data Types
Derived data types that the user creates can also be used with OpenACC data directives. These derived types, whether in C, C++, or Fortran, can contain multiple “levels” of pointers to other data (e.g., pointers to pointers) – often referred to as nested data structures. OpenACC, by default, copies only the highest level of the data structure to the device. The rest of the data structure remains on the host.
Compilers can have a difficult time following pointers down a derived type (a struct in C/C++), especially when copying data from the host to the device and back again. Ultimately, the lower levels of the derived type stay on the host. Fundamentally, any allocated data below the first level in the derived type won’t be copied over to the accelerator device.
This concept can be illustrated with a simple example from an OpenACC blog post. To begin, assume you have the simple data structure or derived type shown in Table 10.
Table 10: A Simple Derived Type
| Fortran | C |
type mytype integer :: x(2) end type mytype type (mytype) A(2) !$acc data copy (A(:2)) |
struct {
int x[2]; // size 2
} *A // size 2
#pragma acc data copy(A[0:2])
|
When array A is copied back and forth, the the entire array is copied because the the compiler knows exactly how it is laid out by the fixed array sizes.
If you modify the code as shown in Table 11, the data type now includes a pointer to an another array, x, that is a pointer (down one level). When array A is copied to the device (the accelerator), only the “upper” part of the array is copied. The parts pointed to by x are not copied, but stay on the host.
Table 11: A Nested Dynamic Data Structure
| Fortran | C |
type mytype integer, allocatable :: x end type mytype type (mytype) A(2) !$acc data copy (A(:2)) |
struct {
int *x;
} *A // size 2
#pragma acc data copy(A[0:2])
|
Before OpenACC 2.6, you had to copy all of the nested data to the device and change all of the references to use the pointers on the device (something of a pain). With OpenACC 2.6, you can now copy the lower levels of the array and they will be connected (the specification calls it “attached”) in the data structure on the device (Table 12).
Table 12: Attached Nested Data
| Fortran | C |
type mytype integer, allocatable :: x end type mytype type (mytype) A(2) !$acc data copy (A(:2)) !$acc data copy(A%x(1:2)) |
struct {
int *x;
} *A // size 2
#pragma acc data copy(A[0:2])
#pragma acc data copy(A.x[0:2])
|
OpenACC generally refers to this operation as a “manual deep copy.” You have to copy all of the levels of the array and the derived type to the device. Be sure you check the version of OpenACC your compiler is using, because only OpenACC 2.6 can use a manual deep copy. In previous versions, you still have to set the pointers on the device manually.
Summary
The powerful OpenACC data directive allows you to control the movement of data in an application, with the purpose of improving performance. In this article, I looked at five data directive “clauses” – copy, copyin, copyout, create, and present – that give you great control over moving data between the host and the accelerator and give the compiler some hints as to what is going on in the code so it can generate better data movement (and, therefore, better performance).
With the two OpenACC directives discussed so far – parallel loop and data (along with its clauses) – you have the basics for getting started writing code using OpenACC.
Tags:
![]() directives ,
directives , ![]() OpenACC ,
OpenACC , ![]() parallel programming
parallel programming