HPC Compilers

If you compile software on an expensive supercomputer, its a good idea to select the languages and compilers with particular care. We report on tried-and-proved tools used on SuperMUC, a supercomputer at the Leibniz Supercomputing Center in Germany.
The vast majority of CPU cycles that HPC systems at the Leibniz Supercomputing Center (LRZ) run in the course of daily calculations involves binary code. The underlying source code is written and compiled in one of three classic HPC languages: Fortran, C++, or C.
Why these languages? Because they have been generating very efficient code for a long time. Figure 1 shows statistics for languages used on the SuperMUC system in the first half of 2017 (see the box titled “SuperMUC”). Column lengths in the figure are proportional to the number of CPU cycles assigned to the projects. Because many projects use a mixture of languages (only 32 percent of all cycles belong to projects that use only one language), these mixtures are represented as separate categories. Fortran is involved in about 72 percent of all allocated project resources, with 54 percent C++ and 41 percent C.
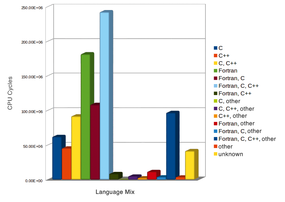
Figure 1: Programming language share in active projects run on SuperMUC in the first half of 2017.
SuperMUC
SuperMUC is a high-performance computer in the Leibniz Computing Center at the Bavarian Academy of Sciences and Humanities in Garching, near Munich, Germany. The computer, built by IBM at a cost of around EUR135 million, has 19 compute islands with approximately 8,200 cores each, and six newer islands with 14,300 cores each. It achieves a speed of around 6 petaFLOPS (10^15 floating point operations per second). In total, almost 500TB of main memory and nearly 20PB of external memory are available for data.
In addition to high computing power, SuperMUC also displays impressive energy efficiency: Its hot water cooling requires 25 percent less electricity than a system with refrigeration units. Water cooling saves another 10 percent compared with air cooling with fans.
At its inauguration in 2012, SuperMUC clocked in at around 3 PFLOPS and was once the fastest computer in Europe and the fourth fastest in the world. In the meantime, it is now in 40th place on the TOP500 list and has also been repeatedly overtaken in Germany alone (e.g., by a Cray XC40 at the High-Performance Computing Center, Stuttgart, and the IBM Blue Gene/Q at the Jülich Supercomputing Center).
Geoscientists, physicists, astronomers, mathematicians, biologists, engineers, and climate researchers from Germany and 24 other European countries, as well as Israel and Turkey, use SuperMUC to investigate and simulate a wide spectrum of projects, such as turbulent flow that leads to thermal fatigue fractures, special aircraft engine nozzles to reduce noise, seismic wave and fracture propagation during earthquakes, protein-protein interactions in HIV drug research, star and galaxy formation, and the mysterious dark universe.
The compilers used on SuperMUC for all three languages are from Intel, which bundled with other HPC software components, are available as the Parallel Studio Cluster Edition. The “other” category includes the GCC (GNU Compiler Collection) compilers, and the “unknown” category includes projects that use special, mostly commercial applications in which the language of implementation is not known.
All of these classic HPC languages are subject to a standardization process that ensures the integration of new language features at regular intervals. Table 1 provides an overview of the last three standard versions of all HPC languages and, if applicable, upcoming new editions.
Table 1: New Language Features
| Language | Year | Most Important Innovations |
| Fortran 95 | 1995 | Only minor corrections and additions to Fortran 90 |
| Fortran 2003 | 2004 | Object orientation, interoperability with C, parameterized data types |
| Fortran 2008 | 2010 | Parallel programming with Coarrays, submodule, DO CONCURRENT |
| Fortran 2015 | 2018 forecast | Extension of C interoperability, extension of the Coarray programming model |
| C++03 | 2003 | Only minor corrections to C++98 |
| C++11 | 2011 | Lambdas, type inference with auto, variadic templates, threading memory model, shared pointers |
| C++14 | 2015 | Generic lambdas, other minor enhancements to C++11 |
| C++17 | 2017 forecast | Structured bindings, use of auto in templates |
| C95 | 1995 | Minimal modifications to C90 |
| C99 | 1999 | New data types, improved compatibility with C++, restrict keyword, more core features for fields and indexing |
| C11 | 2011 | Multithreading support, alignment specification |
Programming Models and HPC Software
Most of the projects on the high-performance computers at the LRZ are based on code developed by scientists over many years. Program authors usually choose the appropriate programming language at the beginning of the development process in the design phase. The decision is often based on their previous knowledge or preferences. As a rule, the selection is rather conservative – on the one hand in terms of the language itself, and on the other hand with regard to the language features on which the programmers rely.
Language features that were only recently defined are only used in the production code when it is assured that they have been ported to other platforms and work there without error and as efficiently as possible. Such new language features (e.g., object orientation) tend to aim for an efficient programming methodology rather than for maximum performance, so it is important to use them wisely – and preferably not at all in data- or computation-intensive contexts.
The programming language is by no means the only factor on which the success of a project depends. Also essential is support for parallel programming models such as OpenMP (Open Multiprocessing, a directive-based model for parallelization with threads in a shared main memory) and MPI (Message Passing Interface, a library-based system for parallelization to distributed main memory, typically via a high-speed network connecting the nodes). Implementations of these models are available for all HPC languages.
Standard interfaces make frequently used functions available as libraries that are optimized for the target platform. For example, BLAS/LAPACK is the standard for linear algebra operations, and FFTW is the standard for Fourier transformations of all kinds. Corresponding libraries for data I/O (e.g., MPI-IO, HDF5, NetCDF) are usually available for all HPC languages.
The implementation of scalable C++ containers in Threading Building Blocks (TBB) has achieved an exceptional status. Initially it was driven by Intel, who later made it available on other platforms as part of an open source project.
Similarly, Fortran implements parallel functionality with Coarrays, an SPMD (single program, multiple data) model with one-way communication for appropriately annotated objects that is much easier to handle than MPI, potentially speeding up the development cycle for parallel applications. However, this is not available in the other HPC languages – or only in a limited form.
The Procurement Process
Because of high investment volumes, in Europe, parallel computers of the highest performance class have to be procured in accordance with legal regulations. The basis is a detailed specification of all requirements for the computing system. In addition to many other criteria, one requirement is that the manufacturer provide a compiler suite (mainline compiler) that is optimal for the architecture offered for all three classic HPC languages.
The manufacturer must describe the degree of standards conformity of the implementations and also provide information on future development of the compilers during the planned operating period. This information is compared among all offers and is also included in the qualitative evaluation of the respective offer.
The quantitative evaluation of the offers essentially relates to the achievable computing power of the system. Each provider must provide performance projections for their system for a set of benchmark programs specified in advance. These benchmarks are either synthetic and measure specific system aspects (e.g., main memory or network bandwidths), or they are real applications based on programs running on the current legacy operating system that are scaled up for the problem sizes to be expected in the future (e.g., by appropriately increasing the size of the data sets to be processed).
As a rule, the mainline compilers offered are used to compile the computation programs; therefore, all classic HPC languages are represented in the benchmark suite. The manufacturer can optimize the execution speed by appropriate selection of implementation-specific compiler options and compiler directives (pragmas). As a rule, such options also include hardware-specific optimizations, as described below.
Although the selection of the compiler plays a key role from the provider’s point of view, in comparisons among manufacturers, benchmark performance is the primary focus of the evaluation. Language implementations and support for language features only represent a small correction factor. However, the procurement specification always requires a minimum of standard support for both the HPC languages and the accompanying programming models. In most cases, the feature set grows between system generations.
Consequences of a System Change
A bid process that reveals the need to switch to a new system architecture often carries considerable consequences. The relevant standards for HPC languages, programming models, and libraries guarantee that the code base can be ported to a new platform. However, the ability to achieve the same or better performance is far from obvious. With every system change in the past, then, scientists had to check their program code for performance weaknesses and – possibly with the support of the data center – optimize again.
For years, the introduction of newer architectures has shown that the performance portability problem has become increasingly worse. Regardless of whether you consider a switch to many-core (Intel Xeon Phi) systems or those that use GPU acceleration, in switching, you will often lose more than an order of magnitude of your computing power, rather than a fraction as in the past, if the memory access patterns or memory requirements of the application are not precisely tailored to the sweet spot of the new architecture.
For example, discontinuously stored field elements in memory cannot be vectorized on current Intel processors, which can result in a power loss factor of up to 32 when using current SIMD (Single Instruction, Multiple Data Processing) units. Similarly, users whose working data sets do not completely fit into the relatively small local main memory of an accelerator card can suffer painful performance losses that often result in performance-reducing offload data transfers. Programmers are then forced to change previously effective data layouts, which can be a very time-consuming process for large applications.
Additionally, programmers typically have to use newer language features (e.g., the directives for asynchronous offloading of data from the host processor to an accelerator card or SIMD directives for vectorization defined in OpenMP 4.5) to create a GPU-enabled or vectorized application on many-core processors. Efficiently implementing these OpenMP concepts (or alternative models such as OpenACC) in the selected compiler suite is necessary for successful optimization.
With the high complexity of programming models, it may well be necessary, depending on the application profile, to consider a compiler alternative. Depending on the platform, the LRZ offers one or two such alternatives on its HPC systems.
The Authors
Dr. Carla Guillen works as a research assistant at the LRZ in the application support group and mainly deals with performance monitoring and energy optimization of high-performance computing applications. In this context, she programs system-wide tools with C++ to monitor the highest scaling computers at the LRZ.
Dr. Reinhold Bader completed his studies in physics and mathematics at the Ludwig Maximilian University in Munich in 1998 with a dissertation on theoretical solid-state physics. Since 1999, he has been a research assistant at the LRZ in HPC user support, HPC systems procurement, prototype benchmarking, and configuration and change management. At present, he is group leader for the HPC services at LRZ. As a German Institute for Standardization (DIN) delegate to the ISO/IEC JTC1/SC22/WG5 standards committee, he is involved in the further development of the international standard for the Fortran programming language.