
AMD’s ROCm platform brings new freedom and portability to the GPU space.
Exploring AMD’s Ambitious ROCm Initiative
This article was updated on November 18, 2019.
Three years ago, AMD released the innovative ROCm hardware-accelerated, parallel-computing environment [1] [2]. Since then, the company has continued to refine its bold vision for an open source, multiplatform, high-performance computing (HPC) environment. Over the past three years, ROCm developers have contributed many new features and components to the ROCm open software platform.
ROCm is a universal platform for GPU-accelerated computing. A modular design lets any hardware vendor build drivers that support the ROCm stack [3]. ROCm also integrates multiple programming languages and makes it easy to add support for other languages. ROCm even provides tools for porting vendor-specific CUDA code into a vendor-neutral ROCm format, which makes the massive body of source code written for CUDA available to AMD hardware and other hardware environments.
What is ROCm, and why is it poised to shake up the whole HPC industry? The best way to get familiar is to look inside.
Big Picture
General programming languages like C++ were developed before the birth of GPU-based parallel computing, and the standard forms of the language do not have the features necessary to capitalize on all the benefits of today’s high-performance computers. In the past, GPU vendors developed their own dialects and drivers to activate GPU-based optimizations for their own hardware. The result was a tangle of proprietary specs and incompatible languages. The absence of a unifying, open source platform cost untold hours of development time and left coders with few options. Code was written for a single hardware platform, and it required an enormous investment of time and expense to make the code ready for a different environment. This vendor lock-in caused inefficient programming practices and limited the organization’s ability to seek a long-term, cost-efficient solution.
The ROCm developers knew the HPC industry needed a universal solution that would end the problem of proprietary specs and incompatible languages, so they built ROCm as a universal open platform that allows the developer to write the code once and compile it for multiple environments. ROCm supports a number of programming languages and is flexible enough to interface with different GPU-based hardware environments (Figure 1).
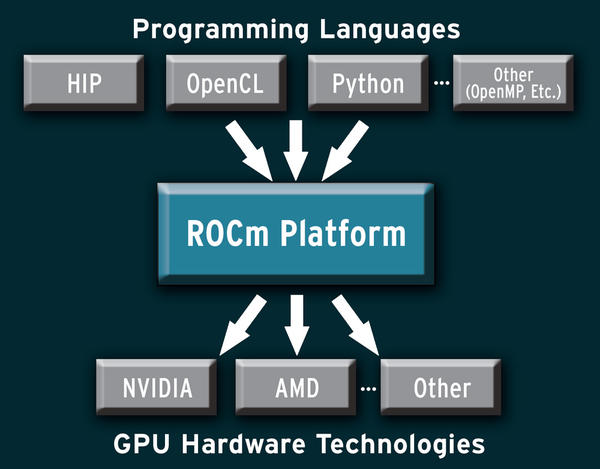 Figure 1: ROCm is designed as a universal platform, supporting multiple languages and GPU technologies.
Figure 1: ROCm is designed as a universal platform, supporting multiple languages and GPU technologies.
At the center of the ROCm environment is a technology known as Heterogeneous-Compute Interface for Portability (HIP) [4]. HIP lets you create code that is ready to compile for either the AMD or CUDA/NVIDIA GPU environment.
AMD maintains a special version of the open source Clang compiler for preparing and compiling HIP code. The HIP/Clang compiler is available for free download at GitHub. The Clang developers are currently working on porting the HIP extensions upstream to the mainline Clang compiler. Once this upstream effort is complete, a separate HIP/Clang compiler won’t be necessary, and HIP will simply be a compiler option within the standard Clang environment.
What About CUDA?
CUDA is an example of a proprietary language designed to work with only one hardware vendor. HIP and the ROCm environment eliminate the need for single-vendor languages like CUDA. However, the ROCm developers are well aware that lots of CUDA code is already out there in the world, so ROCm provides an easy path for porting CUDA code to the vendor-neutral HIP format automatically. Once the code is converted to HIP, you can compile it for AMD hardware using the HIP/Clang compiler. As shown in Figure 2, a CUDA header is all that is needed to prepare the HIP code for the NVIDIA tool chain and the NVCC compiler.
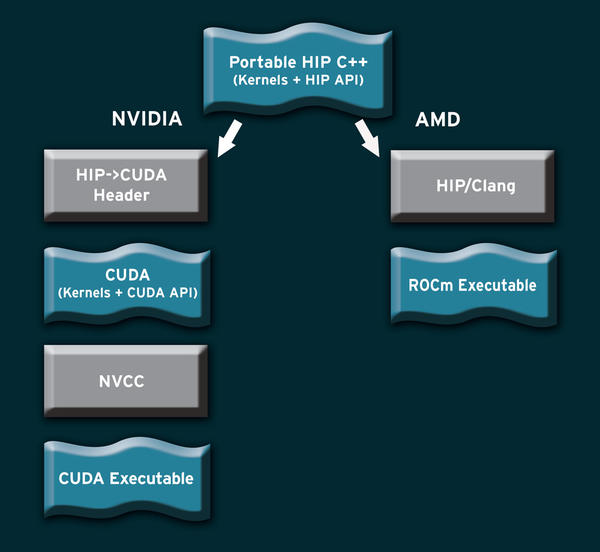 Figure 2: ROCm’s HIP format lets the vendor write the code once and compile it for different hardware environments.
Figure 2: ROCm’s HIP format lets the vendor write the code once and compile it for different hardware environments.
ROCm provides two different alternatives for converting CUDA code to HIP format:
• hipify-perl – a Perl script that you can run on the source code to convert a CUDA program to equivalent HIP code.
• hipify-clang – a preprocessor included with the HIP/Clang compiler that performs the conversion automatically as a standalone preprocessing stage of the compiler process.
The best option for your project will depend upon the details. The Perl script is often easier to use, especially for smaller jobs. The preprocessor gives more extensive hints and error messages and is therefore better suited for large and complex projects.
As a proof of concept, the ROCm team ported the whole Caffe machine-learning framework (with around 55,000 lines of code) from CUDA to HIP: 99.6 percent of the code went unmodified or was automatically converted, and the remaining 0.4 percent took less than a week of developer time to tie up loose ends. The preprocessor can often perform the conversion without any cleanup, for some programs; however, the script provides greater flexibility.
The power to integrate previously written CUDA code with the all-open ROCm makes ROCm a truly universal platform. Near-automatic conversion options eliminate time barriers for CUDA shops looking for a more flexible and a less restrictive solution.