« Previous 1 2 3 Next »
Sharding and scale-out for databases
Shards
Encryption and More
ShardingSphere does not exhibit any weaknesses in any other functional area. The project claims that it is significantly faster than comparable competitor solutions, which the developers have proven with benchmarks [2]. The ShardingSphere team outlined how it achieved near-native performance of the underlying databases on the basis of its solution. ShardingSphere's performance overhead is minimal.
Even with ShardingSphere-Proxy, which according to the developers is significantly slower than the JDBC option, the performance overhead is now 25 percent less (Figure 3). This performance may well be considered a special feature: The Vitess developers, for example, state that performance can drop by up to 50 percent compared to a native MySQL database with their software. However, this is partly to do with the issue of replication, which the article will go into in detail later.
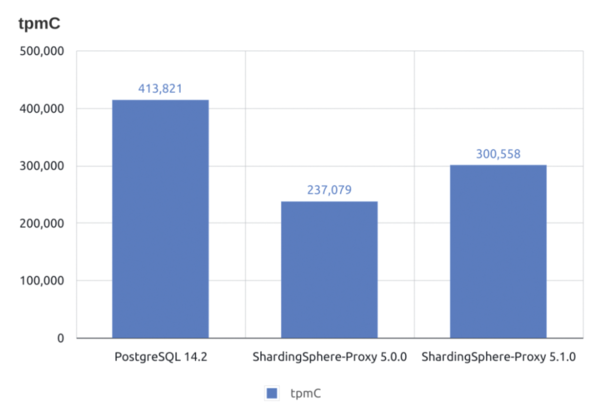 Figure 3: Even with ShardingSphere-Proxy, the slower of the two variants, the performance overhead for PostgreSQL is still well under 25 percent (tpmC = number of transactions that can be fully processed per minute). © ShardingSphere
Figure 3: Even with ShardingSphere-Proxy, the slower of the two variants, the performance overhead for PostgreSQL is still well under 25 percent (tpmC = number of transactions that can be fully processed per minute). © ShardingSphere
ShardingSphere contains an encryption layer that can be dynamically activated as a plugin. It encrypts the data in transit. If you need encryption at rest, you have to take care of this yourself with one of the solutions available for MySQL or PostgreSQL, according to the terse note from the developers.
No Replication
If you only want to create a distributed database, ShardingSphere leaves out a central aspect that comparable solutions handle: replication. Databases usually take care of this feature when scaling horizontally: It is a requirement that the market quite simply imposes on cloud-native and cloud-ready applications. Adding a high-availability layer is obvious when implementing sharding, because then, from a database point of view, it is possible to copy a shard to multiple back ends so that any one of them can step in if another fails.
At this point, the description sounds more trivial than its technical implementation. After all, if you replicate a database, you need to offer guarantees such as atomicity, consistency, isolation, and durability (ACID). Moreover, replication is not very popular precisely because compliance with consistency guarantees usually forces synchronous replication, which in turn consumes performance. It is quite possible that the people at ShardingSphere would be unable to maintain their otherwise fantastic performance values if replication were activated.
The answer to the replication issue is a bit surprising, because ShardingSphere has decided without further ado to ignore the issue almost completely. Instead, the documentation succinctly states that you will want to implement replication at the level of the database back end. Although this solution gives you high-availability (HA) functionality, ShardingSphere is not responsible for compliance. At the end of the day, you end up building countless HA clusters from MySQL or PostgreSQL pairs and then feeding these to ShardingSphere as back ends. However, if you have ever manually tried to make MySQL highly available, you will inevitably have dealt with tools such as Pacemaker or distributed replicated block devices (DRBDs). Pacemaker in particular is not only extremely complex to use but also is definitely not highly available.
The ShardingSphere developers understand that their user story has a hole in it in terms of redundancy. A lot of information online offers guidance about what a valid HA setup can look like with ShardingSphere. However, some guides refer to plugins for ShardingSphere that no longer exist or that rely on hosted solutions, such as database as a service (DBaaS) from AWS to offload the management of the database instances to the provider.
Of course, this is only a valid user story in environments where suitable as-a-service offerings exist at all, which is precisely what private cloud environments, such as those based on OpenStack, often do not offer. The fact that ShardingSphere today has a granular integration with Kubernetes and that all ShardingSphere services can be run as a Kubernetes service does not help, because integration for the underlying application is virtually nonexistent.
The Proxy introduces another peculiarity in the ShardingSphere context: In the documentation, the developers regularly refer to a cluster mode, but you should not be misled by this reference. Cluster mode in ShardingSphere is simply an operating mode that groups the various database instances in the background. Most administrators probably associate the term "cluster" with high availability, but it is completely missing in ShardingSphere.
Eye Candy
Not to be left unmentioned at this point is the ShardingSphere user interface (UI), which reveals almost in passing elementary weaknesses of the product documentation and the developer community of ShardingSphere.
On paper, the ShardingSphere UI is a Vue.js-based graphical interface for the database distributor (Figure 4). On the one hand, it enables administrative tasks such as setting the ShardingSphere configuration parameters. On the other hand, it is intended to help you understand the structure of the data currently stored in ShardingSphere, to identify the distribution and to analyze the back ends currently in use.
 Figure 4: The ShardingSphere UI is intended to make it far easier to understand the stored data and cluster functionality, but it is noticeably under-documented. © ShardingSphere
Figure 4: The ShardingSphere UI is intended to make it far easier to understand the stored data and cluster functionality, but it is noticeably under-documented. © ShardingSphere
It's a pity that the ShardingSphere documentation for the UI says virtually nothing, and although the Git repository contains the code, it only offers a few lines of advice for the install. The rest is left to you to figure out on your own. This task is nontrivial, especially with respect to connecting the UI to a running ShardingSphere instance or cluster. If you don't have any experience with the solution, in the worst case you won't understand the configuration syntax and will spend hours experimenting.
Fatally, the UI documentation is not the only missing part. Time and time again you come across passages in the documentation that you can only understand if you have already worked with the JDBC or gained previous experience with the Proxy. Despite several quickstart guides, life is anything but easy for ShardingSphere newcomers, because the guides are often only links to GitHub directories with sample code, distributed over a multitude of files. How you get from bare metal to a running ShardingSphere instance is not revealed by these documents.
« Previous 1 2 3 Next »
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
Scale-out with PostgreSQL
 The world of scale-out is stateless; unfortunately, databases are not. YugabyteDB solves this dilemma for PostgreSQL.
The world of scale-out is stateless; unfortunately, databases are not. YugabyteDB solves this dilemma for PostgreSQL. -
Distributed MySQL with Vitess
 Vitess relies on various techniques to scale MySQL horizontally, while looking like the popular database from the outside. But does it deliver what its authors promise?
Vitess relies on various techniques to scale MySQL horizontally, while looking like the popular database from the outside. But does it deliver what its authors promise? - Better Crash Recovery with Journaling in MongoDB
-
Databases in the Google Cloud
 The Google Cloud Platform offers a wide range of different databases for various purposes.
The Google Cloud Platform offers a wide range of different databases for various purposes. -
PostgreSQL Replication Update
 High availability, replication, and scaling are everyday necessities in the database world. What features does PostgreSQL offer in this context, and how good are they?
High availability, replication, and scaling are everyday necessities in the database world. What features does PostgreSQL offer in this context, and how good are they?
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
