
HDF5 is a data model, library, and file format used primarily for scientific computing to store and manage data.
Hierarchical Data Storage for HPC
I/O can be a very important part of any application. All applications need to read data and write data at some point with the possibility of huge amounts of both. Therefore, applications can use a very significant portion of the total time it takes to run. I/O becomes even more critical for Big Data or machine learning applications that use a great deal of data.
In a previous article I discussed options for improving I/O performance, focusing on using parallel I/O. One of those options is to use a high-level library that performs the I/O, which can take the pain away from writing code to perform parallel I/O. A great example of this is HDF5. In this article, I want to introduce HDF5 and focuson the concepts and its strengths for performing I/O.
What is HDF5?
HDF5 (Hierarchical Data Format version 5) is a freely available file format standard and a set of tools for storing large amounts of data in an organized fashion. Files written in the HDF5 format are portable across operating systems and hardware (little endian and big endian). HDF5 is a self-describing format (e.g., like XML). It uses a filesystem-like data format (directories and files) that is very familiar to anyone who has used a modern operating system – thus, the "hierarchical" portion of the name.
An example of how you could structure data within an HDF5 file is shown in an HDF5 tutorial, which shows how to use HDFView to view a hyperspectral remote sensing data HDF5 file. Figure 1 shows a screenshot of the HDFViewer. Notice how the temperature data is under a hierarchy of directories. At the bottom of the viewer, when you click on a data value (the temperature), the metadata associated with that data is displayed (it is cut off in the figure).
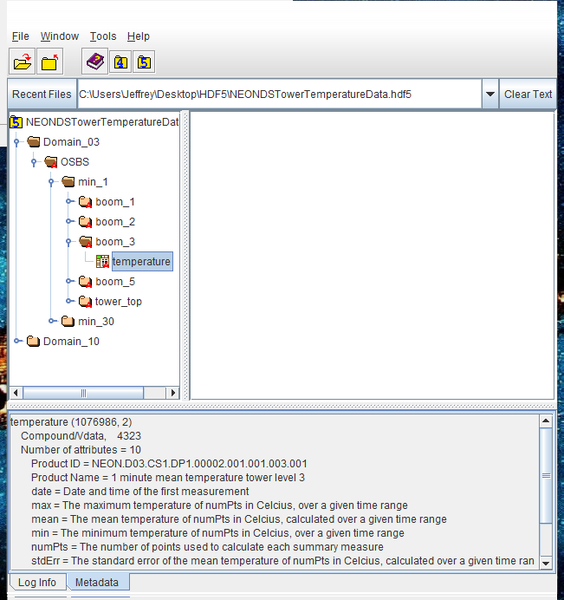 Figure 1: Example of the HDF5 data hierarchy.
Figure 1: Example of the HDF5 data hierarchy.
A very large number of tools and libraries use HDF5 in your favorite language. For example, C, C++, Fortran, and Java are officially supported with the HDF5 tools, but some third-party bindings (i.e. outside the official distribution) are also available, including Python, Matlab, Octave, Scilab, Mathematica, R, Julia, Perl, Lua, Node.js, Erlang, Haskell, and others.
In addition to numeric data, you can store binary or text data, including images and PDFs. The HDF5 format can also accommodate data in row-major (C/C++, Mathematica) or column-major (Fortran, MATLAB, Octave, Scilab, R, Julia, NumPy) order. The libraries from the HDF5 group are capable of compressing data within the file and even “chunking” the data into sub-blocks for storage. Chunking can result in faster access times for subsets of the data. Moreover, you can create lots of metadata to associate with data inside an HDF5 file.
HDF5 data can also be accessed like a database. For example, you can do random access within the file as a database would, and you don’t have to read the entire file to access the data you want (unlike XML).
Of course, one of the interesting things that HDF5 can do is parallel I/O. You might have to build the HDF5 libraries since they will require an MPI library with MPI-IO support. MPI-IO is a low-level interface for carrying out parallel I/O. It gives you a great deal of flexibility but also requires a fair amount of coding. Parallel HDF5 is built on top of MPI-IO to remove most of the pain of doing parallel I/O.
Storing Data in HDF5
HDF5 itself consists of
- a file format for storing HDF data,
- a data model for organizing and accessing HDF5 data, and
- the software – libraries, language interfaces, and tools.
The first part, the file format, is defined and published by the HDF Group. The data model for HDF is fairly straightforward. Fundamentally, an HDF5 file is a container that holds data objects. Currently there are eight objects that either store data or help organize it. These are,
- Dataset
- Group
- Attribute
- File
- Link
- Datatype
- Dataspace
- Property List
Of these objects, datasets (multidimensional arrays of homogeneous type), and groups (container structures that can hold datasets and other groups) hold data. The others are used for data organization.
Groups and Datasets
Groups are a key to organizing data with an HDF5 file. HDF5 groups are very similar to directories in a filesystem. Just like directories, you can organize data hierarchicallyso that it makes understanding the data layout much easier. With attributes (metadata) you can make groups even more useful than directories by adding explanations.
HDF5 datasets are very similar to files in a filesystem. Datasets hold the data in the form of multidimensional arrays of data elements. Data can be almost anything, such as images, tables, graphics, or documents. As with groups, they also have metadata.
Every HDF5 file contains a “root” group. This group can contain other groups or datasets (files) or can be linked to other dataset objects in other portions of the HDF5 file. This is something like the root directory in a filesystem. In HDF5, the root group is referred to as “/”. If you write /foo then foo is a member of the root group (it could be another group or a dataset or a link to other files). This looks something like a “path” to a file or directory in a filesystem.
Figure 2show a diagram of a theoretical layout of an HDF5 file. The root group (/) has three subgroups: A, B, and C. The group /A/temp points to an object (a dataset) that is different from what /C/temp points to (a different dataset). But also notice that datasets can be shared (kind of like a symbolic link in filesystems). In Figure 2, /A/k and /B/m point to the same object (a dataset).
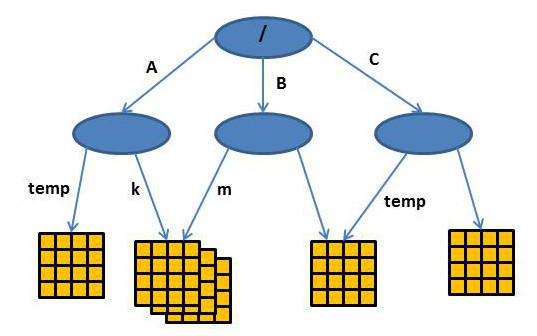 Figure 2: Theoretical HDF5 layout.
Figure 2: Theoretical HDF5 layout.
Groups and datasets are the two most fundamental object types in HDF5. If you can remember them and use them, then you can start writing and reading HDF5 files in your applications.
Dataset Details
A dataset object consists of the data values and metadata that describes it. A dataset has two fundamental parts to it: a header and a data array. A header contains information about the data array portion of the dataset and the metadata information that describes it. Typical header information includes:
- name of the object,
- dimensionality,
- number type,
- information about how the data is stored on disk, and
- other information that HDF5 can use to speed up data access or improve data integrity.
The header has four essential classes of information: name, datatype, dataspace, and storage layout.
A name in HDF5 is just a set of ASCII characters, but you should use a name that is meaningful to the dataset.
A datatype in HDF5 describes the individual data elements in a dataset and comprises two categories or types: atomic and compound. It can get quite complicated defining datatypes, so the subsequent discussion will focus on a few datatypes to explain the basics.
The atomic datatype includes integers, floating-point numbers, and strings. Each datatype has a set of properties. For example the Interger datatype properties are size, order (endianness), and sign (signed/unsigned). The Float datatype properties are size, location of the exponent and mantissa, and location of the sign bit.
Some predefined datatypes can be used for the typical data you might encounter. Listing 1 is a simple example using YAML to show how a dataset might be defined. The datatype is defined as H5T_STD_I32BE, which is a predefined HDF5 datatype (portable 32-bit, big endian). The STD part of the definition points to architectures that contain semi-standard datatypes. The I indicates a signed integer, 32 is the number of bits representing the datatype, and BE indicates that the data is stored in big-endian format.