
Open|SpeedShop is an open source multiplatform Linux performance tool targeted at performance analysis of applications running on both a single-node and on large-scale platforms.
Look for Bottlenecks with Open|SpeedShop
Open|SpeedShop is an open source multiplatform Linux performance tool targeted at performance analysis of applications running on both a single node and on large-scale IA64, IA32, EM64T, AMD64, IBM Power PC, Cray, and IBM Blue Gene platforms. Open|SpeedShop operates on existing application binaries, so there is no need to recompile the application being analyzed. Open|SpeedShop gathers several types of performance information, relates that information back to the application source code, and then displays the associated performance information to the user.
Open|SpeedShop is in use at a number of laboratories, universities, and corporations worldwide, helping software developers and users speed up applications and reduce time to solution. Open|SpeedShop supports performance analysis of sequential, MPI, openMP, and threaded applications and has been tested on several of the most common Linux distributions with the most commonly used MPI implementations, including SGI MPT, mpich2 variants, mvapich, mvapich2, and openmpi.
In this article, I will describe how to use Open|SpeedShop through step-by-step examples illustrating how to find a number of different performance bottlenecks. Additionally, I will describe the tool’s most common usage model (workflow) and provide several performance data viewing options.
Open|SpeedShop uses both statistical sampling and traditional tracing techniques to record performance information. The central concept in its workflow is an experiment. An experiment defines what type of performance information is being measured and the program being analyzed. Users select their experiment at the beginning of any performance analysis run depending on what kind of performance bottleneck they would like to investigate.
The main types of data gathered via sampling techniques – by periodically interrupting execution, recording location, then reporting statistical distribution across all reported locations – are program counter information (pcsamp; experiment names are in parentheses; for example, “pcsamp” is the name of the Program Counter Sampling experiment), call path information (usertime), and hardware counter information (hwc, hwctime, hwcsamp). Tracing techniques are used to gather Input/Output information (io, iot), MPI function-specific information (mpi, mpit, mpiotf), and Floating Point Exception information (fpe). (Tracing techniques involve gathering and storing individual application events – e.g., function invocations, MPI messages, I/O calls. Events are typically time stamped and provide detailed per event information.) Table 1 describes specific performance issues that each Open|SpeedShop experiment is designed to reveal.
Table 1: Summary of Experiments
| Experiment | Clues | Data Collected and Derived |
| pcsamp | High user CPU time. Gives good low-overhead overview of performance. | Actual CPU time at the source line, machine instruction, and function levels by sampling the program counter at 100 samples per second. |
| usertime | Slow program, nothing else known. May not be CPU-bound. | Inclusive and exclusive CPU time for each function by sampling the callstack at 35-sample-per-second intervals. Identifies paths through the program that are taking the most time. |
| hwc | High user CPU time | Counts at the source line, machine instruction, and function levels of various hardware events, including: clock cycles, graduated instructions, primary instruction cache misses, secondary instruction cache misses, primary data cache misses, secondary data cache misses, translation lookaside buffer (TLB) misses, and graduated floating-point instructions. A single hardware counter is read when a predefined count threshold is reached (overflows). |
| hwcsamp | High user CPU time | Similar to hwc experiment, except that periodic sampling is used instead of the overflow mechanism. Up to six (6) hardware counter events are read when a sample is taken. |
| hwctime | High user CPU time | Similar to hwc experiment, except that callstack sampling is used and call paths are available along with the event counts. |
| io | I/O-bound | Traces and times the following I/O system calls: read, readv, write, writev, open, close, dup, pipe, creat. The time reported is wall clock time. Call path information also is available. |
| iot | I/O-bound | Traces and times the following I/O system calls: read, readv, write, writev, open, close, dup, pipe, creat. The time reported is wall clock time. Output is a line of trace per I/O function call. Call path information also is available. |
| mpi | MPI performance is poor. | Times calls to various MPI routines. The time reported is wall clock time. Call path information also is available. |
| mpit | MPI performance is poor. | Traces and times MPI function calls. Output is optionally a line of trace per MPI function call. All calls are accounted for by wrapping, (i.e., no sampling). The time reported is wall clock time. Call path information also is available. |
| mpiotf | MPI performance is poor, and OTF files are preferred. | Traces and times MPI function calls and generates Open Trace Format (OTF) files using VampirTrace as the underlying gathering tool. |
| fpe | High system time. Presence of floating point operations | All floating-point exceptions, with the exception type and the callstack at the time of the exception. |
After collecting performance information, Open|SpeedShop displays it in detailed reports that allow the user to relate the performance information back to its application source code easily. This information is accessible through a comprehensive graphical user interface (GUI), from a command line interface (CLI), as well as from within Python scripts. Additionally, the toolset includes a series of analysis techniques, including outlier detection, load balance analysis, and cross-experiment comparisons. Open|SpeedShop’s functionality provides a comprehensive set of techniques that greatly aids analysis and understanding of parallel application performance.
Open|SpeedShop Program Counter Sampling Example
An Open|SpeedShop user must first set up a run-time environment. This is usually done by loading a module, Dotkit, or SoftEnv file that will set environment variables, including PATH and LD_LIBRARY_PATH, so that Open|SpeedShop tools and libraries can be accessed. A typical run-time environment initialization would include these items:
export OPENSS_PREFIX=/opt/OSS-201 export OPENSS_MPI_IMPLEMENTATION=openmpi export OPENSS_PLUGIN_PATH=$OPENSS_PREFIX/lib64/openspeedshop export OPENSS_RAWDATA_DIR=/opt/shared export LD_LIBRARY_PATH=$OPENSS_PREFIX/lib64:$LD_LIBRARY_PATH export PATH=$OPENSS_PREFIX/bin:$PATH
The Open|SpeedShop website describes the usage and meaning of these environment variables in detail (BuildAndInstallGuide).
The workflow model for running Open|SpeedShop on a desktop or cluster system entails a command to gather the data and create an Open|SpeedShop database file containing the performance information and application symbol information. The Open|SpeedShop GUI or the interactive CLI tool enable viewing the data contained in the database file. Each of the above-mentioned experiments has a corresponding convenience command – for example, osspcsamp for the pcsamp experiment, ossusertime for the usertime experiment, and so on. I use the application smg2000 – a Semicoarsening Multigrid Solver based on the hypre library and taken from the ASCI Purple benchmark suite – for examples in this article.
To run a program counter sampling experiment on the smg2000 application on 256 processors using openmpi or SLURM, you would use
module load openspeedshop-2.0.1 module load mvapich-1.1
(or other MPI implementation). If you run your application like this normally,
mpirun –np 256 smg2000 –n 65 65 65
or this,
srun -ppbatch -N 32 -n 256 ./smg2000 -n 90 90 90
then to run with Open|SpeedShop, one adds the convenience command and quotes around the command normally used to execute the application outside of Open|SpeedShop:
osspcsamp "mpirun –np 256 smg2000 –n 65 65 65" osspcsamp "srun -ppbatch -N 32 -n 256 ./smg2000 -n 90 90 90"
When executing the above commands, one sees output from Open|SpeedShop and from the application and then the default performance analysis report showing the functions in the application that took the most time. Additionally, an Open|SpeedShop database file is created. This SQLite database file contains the performance information for smg2000 and the debug symbol table information, including source line number information. That enables the file to be moved to any other platform/laptop that has Open|SpeedShop installed for viewing, if desired.
Here is the example output from a pcsamp experiment run from hyperion at Lawrence Livermore National Laboratory (LLNL) using SLURM:
osspcsamp "srun -ppbatch -N 32 -n 256 ./smg2000 -n 90 90 90" [openss]: pcsamp experiment using the pcsamp experiment default sampling rate: "100". [openss]: Using OPENSS_PREFIX installed in /home/jeg/chaos_4_x86_64_ib/opt/OSS-mrnet [openss]: Setting up offline raw data directory in /home/jeg/chaos_4_x86_64_ib/shared/offline-oss [openss]: Running offline pcsamp experiment using the command: "srun -ppbatch -N 32 -n 256 /home/jeg/chaos_4_x86_64_ib/opt/OSS-mrnet/bin/ossrun -c pcsamp ./smg2000 -n 90 90 90" Running with these driver parameters: (nx, ny, nz) = (90, 90, 90) (Px, Py, Pz) = (256, 1, 1) (bx, by, bz) = (1, 1, 1) (cx, cy, cz) = (1.000000, 1.000000, 1.000000) (n_pre, n_post) = (1, 1) dim = 3 solver ID = 0 ============================================= Struct Interface: ============================================= Struct Interface: wall clock time = 0.431376 seconds cpu clock time = 0.440000 seconds ============================================= Setup phase times: ============================================= SMG Setup: wall clock time = 5.291889 seconds cpu clock time = 5.300000 seconds ============================================= Solve phase times: ============================================= SMG Solve: wall clock time = 46.156027 seconds cpu clock time = 46.160000 seconds Iterations = 7 Final Relative Residual Norm = 3.535135e-07 [openss]: Converting raw data from /home/jeg/chaos_4_x86_64_ib/shared/offline-oss into temp file X.0.openss Processing raw data for smg2000 Processing processes and threads ... Processing performance data ... Processing functions and statements ... [openss]: Restoring and displaying default view for: /home/jeg/chaos_4_x86_64_ib/smg2000/test/smg2000-pcsamp.openss [openss]: The restored experiment identifier is: -x 1 Exclusive % of CPU Function (defining location) CPU time in Time seconds. 5735.470000 47.243309 hypre_SMGResidual (smg2000: smg_residual.c,152) 2874.310000 23.675813 hypre_CyclicReduction (smg2000: cyclic_reduction.c,757) 1293.670000 10.656015 smpi_net_lookup (libmpich.so.1.0: mpid_smpi.c,1370) 329.590000 2.714847 hypre_SemiInterp (smg2000: semi_interp.c,126) 276.170000 2.274824 hypre_SemiRestrict (smg2000: semi_restrict.c,125) 125.830000 1.036467 pthread_spin_lock (libpthread-2.5.so) 124.440000 1.025018 hypre_SMGAxpy (smg2000: smg_axpy.c,27) 87.770000 0.722965 __GI_memcpy (libc-2.5.so) 79.820000 0.657481 hypre_StructAxpy (smg2000: struct_axpy.c,25) 79.370000 0.653774 hypre_SMGSetStructVectorConstantValues (smg2000: smg.c,379) 63.160000 0.520252 __munmap (libc-2.5.so) 58.160000 0.479066 MPIR_UnPack_Hvector (libmpich.so.1.0: dmpipk.c,95) 58.100000 0.478572 hypre_StructVectorSetConstantValues (smg2000: struct_vector.c,537)
The default report, created when the osspcsamp command was executed, displays the functions in the smg2000 application that took the most time. A user can further examine the performance information with the CLI or GUI by opening the Open|SpeedShop database file created during the experiment. With the command
openss –f smg2000-pcsamp.openss
the GUI is raised and displays the program counter sampling experiment default view as shown in Figure 1. Note that the naming convention for Open|SpeedShop database files uses the .openss suffix.
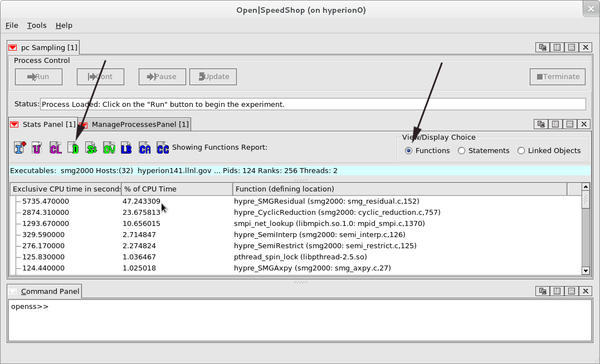 Figure 1: Default GUI program counter sampling view.
Figure 1: Default GUI program counter sampling view.
By choosing the Statements as the View/Display Choice on the right side of the GUI Stats Panel window and then clicking on the D icon, which represents the default view selection, one can view which statements in smg2000 took the most time (Figure 2). By double-clicking on a line of performance information in the Stats Panel, the Source Panel is raised and focuses on the line in the application source code that corresponds to the performance information. With this feature, one can quickly see where in the application source the performance issue shows up.
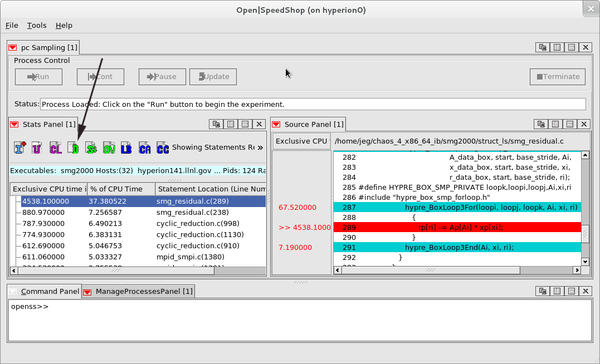 Figure 2: Statement view with Source Panel.
Figure 2: Statement view with Source Panel.
In the load balance view (Figure 3), one can look across all ranks included in the application execution at statement-level granularity. To generate this view, select Statements as the View/Display Choice and then click on the LB load balance icon. The information displayed is the minimum, maximum, and average exclusive time recorded for each statement in the program across all ranks, threads, or processes. In this case, a user sees rank information because this is an MPI application run. Additionally, this view displays rank number of the minimum and maximum values to help focus in on any possible outliers (a rank, thread, or process that is performing outside of the majority of the other ranks, threads, or processes). Use this view to determine whether there is imbalance or not. If the minimum and maximum values for key functions, statements, or libraries vary by a significant amount, then the application run is likely not well balanced.
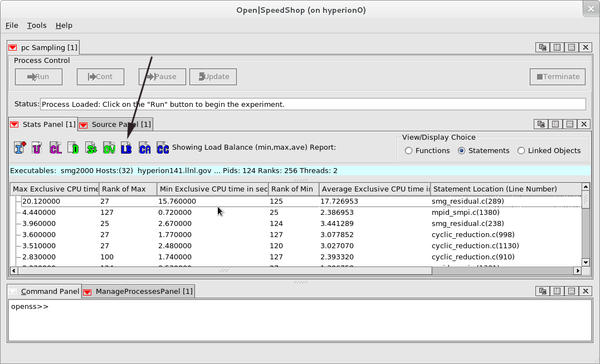 Figure 3: Program counter sampling load balance view.
Figure 3: Program counter sampling load balance view.
If imbalance is suspected, the comparative analysis CA icon can be selected to run a cluster analysis algorithm on the performance information. In general, the cluster analysis algorithm will group processes, threads, or ranks together into groups of like-performing entities, thus exposing the ranks, threads, or processes that are not performing the way the other groups are. Each group is displayed as a column in the comparative analysis view (Figure 4). This view depicts which ranks are in the outlier group(s) and examines their performance information individually or as a group with the other Open|SpeedShop views.
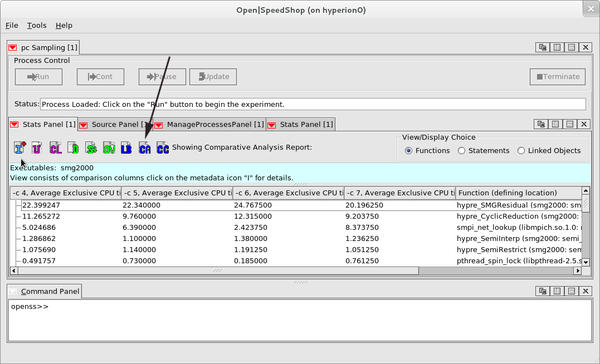 Figure 4: Program counter sampling comparative analysis view.
Figure 4: Program counter sampling comparative analysis view.
Open|SpeedShop Call Path Profiling Example
The previous example showed how Open|SpeedShop can identify performance issues using the lightweight program counter (pcsamp) experiment to obtain an overview of the performance of an application across all its ranks, threads, or processes. This is a good starting point, but program counter sampling does not give calling context. That is, it is missing information about time spent along call paths through the application and also the function caller–callee relationship information.
For understanding the call path behavior of an application, Open|SpeedShop provides the usertime experiment. With the performance information gathered during this experiment, one can see what the call paths are for the application. Additionally, one can see the time spent on each call path in the program and which call paths through the application are the most expensive. After running the ossusertime command,
ossusertime "srun -ppbatch -N 32 -n 256 ./smg2000 -n 90 90 90"
one can view the performance information. Here, I introduce an example of the CLI to show the default view for the usertime experiment. Using the command
openss –cli –f smg2000-usertime.openss
will open the Open|SpeedShop CLI and load in the performance data associated with the named database file, making it available to view.
openss –cli –f smg2000-usertime.openss > expview Exclusive Inclusive % of Function (defining location) CPU time in CPU time in Total seconds. seconds. Exclusive CPU Time 6178.171305 6334.428445 50.479734 hypre_SMGResidual (smg2000: smg_residual.c,152) 3089.885652 4308.514200 25.246404 hypre_CyclicReduction (smg2000: cyclic_reduction.c,757) 895.999982 1044.257122 7.320911 smpi_net_lookup (libmpich.so.1.0: mpid_smpi.c,1370) 353.999993 354.685707 2.892413 hypre_SemiInterp (smg2000: semi_interp.c,126) 295.285708 296.114280 2.412679 hypre_SemiRestrict (smg2000: semi_restrict.c,125) 137.999997 138.257140 1.127551 hypre_SMGAxpy (smg2000: smg_axpy.c,27) 101.057141 101.057141 0.825703 __munmap (libc-2.5.so) 90.514284 90.514284 0.739561 __GI_memcpy (libc-2.5.so) 88.714284 88.942855 0.724854 hypre_SMGSetStructVectorConstantValues (smg2000: smg.c,379) 86.999998 86.999998 0.710847 hypre_StructAxpy (smg2000: struct_axpy.c,25)
As a convenience, the Open|SpeedShop GUI provides a hot call path HC icon, which, when selected, will display the top five time-taking call paths through the application. Figure 5 is an example of information that is displayed; the first call path listed is the call path through smg2000 that took the most time. The same information is available in the CLI using the
expview –v calltrees,fullstack usertime5
command. This command tells the CLI to display the five top time-consuming unique call paths in the application. The fullstack option tells the CLI to display the entire individual call path, even if the display of that particular call path matched portions of another call path. Without the fullstack option, the call path display would compress the call path view.
All call paths can be examined in the GUI, if desired, by selecting the C+ icon.
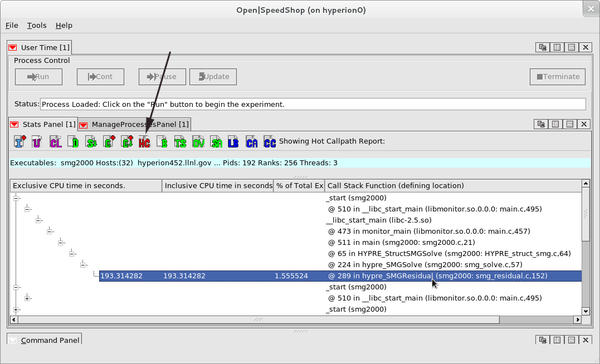 Figure 5: Call path (usertime) hot call paths view.
Figure 5: Call path (usertime) hot call paths view.
Open|SpeedShop Hardware Counter Examples
Hardware counters provide access to the low-level details of the machine-level information – such as cache misses, TLB misses, counts of floating-point and integer instruction operations, as well as many other interesting counts – by leveraging the open source, platform-independent Performance Application Programming Interface (PAPI) component. Through PAPI, Open|SpeedShop gives access to these machine-level details via three experiments:
- hwc (osshwc), which allows the user to specify one hardware counter event and then tracks all occurrences based on a threshold value and maps that information back to the source code statements where the hardware counter events occurred.
- hwctime (osshwctime), which provides the same information as the hwc experiment, but also provides function-level call path information, giving the calling context and events along call paths in the application being monitored.
- hwcsamp (osshwcsamp), which uses a timer-based sampling mechanism to periodically read up to six hardware counter values during the experiment execution. This experiment provides a good overview of how often the hardware counter events the user specified are occurring. Mapping where the events occurred is not as accurate as the hwc and hwctime experiments.
Invoking these experiments is similar to the experiments discussed earlier. Here, I show an hwc experiment that measures the number of level 1 cache misses in the smg2000 application. To gather the hardware counter information, I invoke the command:
osshwc "srun -ppbatch -N 32 -n 256 ./smg2000 -n 90 90 90" PAPI_L1_DCM
Then, using the Open|SpeedShop CLI, the performance information is displayed as the number of level 1 cache misses. (Running any of the hardware counter experiments with no arguments displays the PAPI hardware counter event names that can be used to specify the event that will be monitored.) In this example, I use the CLI command expview with the -v statements option, to view the statement-level information, and the hwc10 option, which limits the view to display only the top 10 statements. (Using the experiment name and a number tells Open|SpeedShop how many lines of output to display.)
openss -cli -f /home/jeg/chaos_4_x86_64_ib/smg2000/test/smg2000-hwc.openss openss>>[openss]: The restored experiment identifier is: -x 1 openss>>expview -v statements hwc10 Exclusive % of Total Statement Location (Line Number) PAPI_L1_DCM PAPI_L1_DCM Counts Counts 74060000000 35.039743 smg_residual.c(289) 18380000000 8.696064 cyclic_reduction.c(1130) 13620000000 6.443982 cyclic_reduction.c(998) 12040000000 5.696442 cyclic_reduction.c(910) 11640000000 5.507192 smg_residual.c(152) 9520000000 4.504164 smg_residual.c(238) 8740000000 4.135125 smg_residual.c(287) 7760000000 3.671461 cyclic_reduction.c(1061) 5060000000 2.394020 cyclic_reduction.c(853) 4860000000 2.299394 semi_restrict.c(262)
With this performance data, I can tell that line 289 in the file smg_residual.c has the most level 1 cache misses in the smg2000 application. Frequently, users will run more than one hwc, hwctime, or hwcsamp experiment and then use the information from multiple experiments to calculate ratios and other statistics to help understand the performance issues at the source lines that Open|SpeedShop points them to. For example, running another hwc experiment, this time using PAPI_L1_DCA (level 1 data cache accesses), would allow the calculation of the ratio of level 1 data cache misses to accesses, which could be used find source lines that are performing badly because of excessive cache misses.
Using the Open|SpeedShop Tracing Experiments
Besides sampling experiments, Open|SpeedShop also provides tracing experiments, which gather performance information about input/output (I/O) function usage, message passing interface (MPI) function usage, and floating-point exception (FPE) detection. As with all Open|SpeedShop experiments, the interface to gather and display this information is similar to that I have discussed previously. Only the convenience routine names change. For example, to gather I/O performance information for the sweep3d application, I use ossio (basic I/O information) or ossiot (basic I/O information and per I/O call function parameter and timing information). To show statistics available from the output of the ossiot experiment, I use the data that was gathered with this command:
ossiot "mpirun –np 2 ./sweep3d.mpi"
In Figure 6, I present an example of the event-by-event list view using the GUI, when the Event List EL icon is selected. A chronological list of all the Input/Output function calls, with the argument values and function-dependent return values, is displayed in this view.
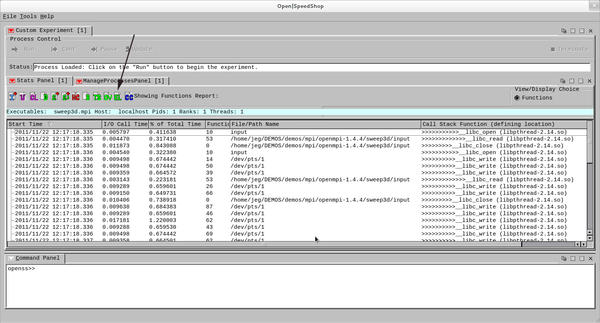 Figure 6: Input/output event list view.
Figure 6: Input/output event list view.
Using the CLI, this is the default view of the I/O experiment data:
openss –cli -f sweep3d.mpi-iot.openss
openss>>[openss]: The restored experiment identifier is: -x 1
openss>>expview
I/O Call % of Number Function (defining location)
Time(ms) Total of
Time Calls
1.368046 97.143385 36 __libc_write (libpthread-2.14.so)
0.022279 1.582006 2 __libc_close (libpthread-2.14.so)
0.010337 0.734019 2 __libc_open (libpthread-2.14.so)
0.007613 0.540590 2 __libc_read (libpthread-2.14.so)As with any of the experiments that span multiple processes, threads, or MPI ranks, Open|SpeedShop allows the user to focus on any individual process, thread, or MPI rank and allows the user to show the load balance across the experiment and do cluster analysis to find the outliers.
The second tracing experiment set is related to tracing MPI function calls. In general, these experiments record timing and parameter information related to each individual MPI call made in the application being analyzed. There are three specific MPI Open|SpeedShop experiments:
- mpi (ossmpi), intercepts each MPI function call, recording the number of calls to each function, the time spent in each call, and the call path information, which describes the call path to each of the MPI function calls.
- mpit (ossmpit), provides the same information as the mpi experiment, but also provides the parameter values for each MPI function call made in the application being monitored.
- mpiotf (ossmpiotf), uses VampirTrace under the hood and creates Open Trace Format (OTF) files, which can be displayed with other tools, most notably, Vampir (Vampir: Performance Optimization). The VampirTrace library allows MPI communication events of a parallel program to be recorded as a trace file.
A notable feature of the MPI experiments (and for the I/O experiments) is that it is unnecessary to gather data for all the MPI functions. ossmpi, ossmpit, and ossmpiotf accept a list of MPI functions as an argument following the MPI application command enclosed in quotes. Performance information will only be gathered for the MPI functions specified in the argument list. For example, using this command, Open|SpeedShop will only gather data for MPI_Send and MPI_Recv:
ossmpi "mpirun –np 4000 nbody" MPI_Send,MPI_Recv
This method could be useful because the gathering of tracing performance data creates large database files and slows viewing considerably. This also is true for the I/O experiments.
For the MPI example usage, the following command was run to create the mpi experiment database:
ossmpi "srun -ppbatch -N 64 -n 512 ./smg2000 -n 90 90 90"
The CLI can be used to examine the mpi experiment performance information. The expview command, with no arguments, always displays the default view of the performance information. That is the same information output to stdout when the convenience script (in this case ossmpi) is run. Following the output for the default view, note that the expview command, followed by the –f MPI_Waitall phrase, displays only the performance information for that particular function. This works for all the experiments, not just the MPI set of experiments. The last example command,
expview -vcalltrees,fullstack -f MPI_Waitall mpi1
instructs the CLI to display the top time-consuming unique call path involving the function MPI_Waitall. This technique might be useful when one is focusing on an individual MPI function because it eliminates excess call path displays.
openss -f smg2000-mpi-mvapich.openss
[openss]: The restored experiment identifier is: -x 1
[hyperion0] ~/chaos_4_x86_64_ib/smg2000/test: openss -cli -f smg2000-mpi-mvapich.openss
openss>>[openss]: The restored experiment identifier is: -x 1
openss>>expview
Maximum MPI Minimum MPI Average Number Function (defining location)
Call Call Time(ms) of
Time(ms) Time(ms) Calls
2055.186000 1249.155000 1629.353117 512 PMPI_Init (libmonitor.so.0.0.0: pmpi.c,103)
729.541000 0.000001 0.907746 4667648 MPI_Waitall (libmpich.so.1.0: waitall.c,57)
21.905000 17.245000 20.251752 512 PMPI_Finalize (libmonitor.so.0.0.0: pmpi.c,232)
11.017000 0.011000 0.766577 6144 MPI_Allreduce (libmpich.so.1.0: allreduce.c,59)
2.291000 0.024000 0.994482 512 MPI_Barrier (libmpich.so.1.0: barrier.c,56)
1.425000 0.000001 0.001452 5403936 MPI_Isend (libmpich.so.1.0: isend.c,58)
0.371000 0.214000 0.315465 512 MPI_Allgatherv (libmpich.so.1.0: allgatherv.c,73)
0.186000 0.052000 0.083457 512 MPI_Allgather (libmpich.so.1.0: allgather.c,70)
0.020000 0.000001 0.000737 5403936 MPI_Irecv (libmpich.so.1.0: irecv.c,48)
openss>>expview -f MPI_Waitall
Maximum Minimum Average Number Function (defining location)
MPI Call MPI Call Time(ms) of
Time(ms) Time(ms) Calls
729.541000 0.000001 0.907746 4667648 MPI_Waitall (libmpich.so.1.0: waitall.c,57)
openss>>expview -vcalltrees,fullstack -f MPI_Waitall mpi1
Exclusive MPI % of Number Call Stack Function (defining location)
Call Time(ms) Total of
Calls
_start (smg2000)
> @ 516 in __libc_start_main (libmonitor.so.0.0.0: main.c,495)
>>__libc_start_main (libc-2.5.so)
>>> @ 473 in monitor_main (libmonitor.so.0.0.0: main.c,457)
>>>> @ 513 in main (smg2000: smg2000.c,21)
>>>>> @ 69 in HYPRE_StructSMGSolve (smg2000: HYPRE_struct_smg.c,64)
>>>>>> @ 260 in hypre_SMGSolve (smg2000: smg_solve.c,57)
>>>>>>> @ 325 in hypre_SMGRelax (smg2000: smg_relax.c,228)
>>>>>>>> @ 168 in hypre_SMGSolve (smg2000: smg_solve.c,57)
>>>>>>>>> @ 318 in hypre_SMGRelax (smg2000: smg_relax.c,228)
>>>>>>>>>> @ 1084 in hypre_CyclicReduction (smg2000: cyclic_reduction.c,757)
>>>>>>>>>>> @ 405 in hypre_FinalizeIndtComputations (smg2000: computation.c,399)
>>>>>>>>>>>> @ 676 in hypre_FinalizeCommunication (smg2000: communication.c,662)
360555.748459 7.071258 87040 >>>>>>>>>>>>> @ 57 in MPI_Waitall (libmpich.so.1.0: waitall.c,57)A graphical view (Figure 7) of the load balance across the 512 ranks of the smg2000 application run, from the same database file used above, shows the minimum, maximum, and average values for the time spent inside the MPI functions that were called during this application’s execution. The rank numbers of the minimum and maximum values are also displayed. As with all experiments that have multiple processes, threads, or ranks, selecting the LB icon generates the load balance view.
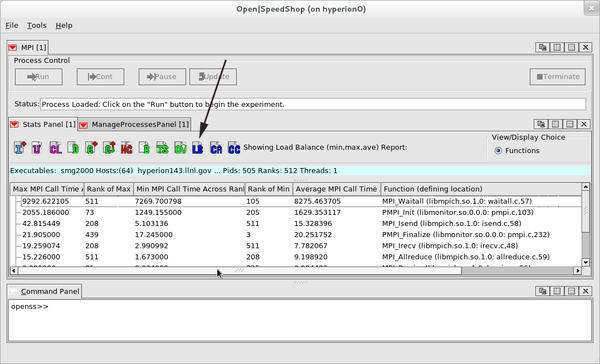 Figure 7: MPI experiment load balance view.
Figure 7: MPI experiment load balance view.
The last of the tracing experiments is the floating-point exception (fpe) tracing experiment. This experiment tracks which type of floating-point exception occurred and maps the exception back to the place in the application source where the exception occurred. Running this Open|SpeedShop convenience script
ossfpe "mpirun -np 2 ./smg2000 -n 10 10 10"
creates a database file that, when viewed, can map the floating-point exceptions back to the source lines where they occurred. Here, I use the CLI to illustrate one of the possible views:
openss -cli -f smg2000-fpe.openss openss>>[openss]: The restored experiment identifier is: -x 1 openss>>expview Exclusive Inclusive % of Function (defining location) Fpe Event Fpe Event Total Counts Counts Counts 12 12 50.000000 hypre_SMGRelaxSetup (smg2000: smg_relax.c,357) 12 24 50.000000 __libc_start_main (libmonitor.so.0.0.0) openss>>expview -vstatements Exclusive Inclusive % of Statement Location (Line Number) Fpe Event Fpe Event Total Counts Counts Counts 12 12 50.000000 smg_relax.c(408) 12 24 50.000000 main.c(516) openss>>expview -vtrace Fpe Event Exclusive Inclusive % of Call Stack Function (defining location) Time(d:h:m:s) Fpe Event Fpe Event Total Counts Counts Counts 0.128757 1 1 4.166667 >__libc_start_main (libmonitor.so.0.0.0) 0.128893 1 1 4.166667 >__libc_start_main (libmonitor.so.0.0.0) 0.145013 1 1 4.166667 >__libc_start_main (libmonitor.so.0.0.0) 0.152065 1 1 4.166667 >>>>>>>hypre_SMGRelaxSetup (smg2000: smg_relax.c,357) 0.152097 1 1 4.166667 >__libc_start_main (libmonitor.so.0.0.0) 0.152119 1 1 4.166667 >>>>>>>hypre_SMGRelaxSetup (smg2000: smg_relax.c,357) 0.184744 1 1 4.166667 >__libc_start_main (libmonitor.so.0.0.0) 0.184744 1 1 4.166667 >__libc_start_main (libmonitor.so.0.0.0) 0.184784 1 1 4.166667 >>>>>>>hypre_SMGRelaxSetup (smg2000: smg_relax.c,357) 0.184784 1 1 4.166667 >>>>>>>hypre_SMGRelaxSetup (smg2000: smg_relax.c,357)
Comparing Open|SpeedShop Experiment Data
Open|SpeedShop provides a convenience script named osscompare that allows up to eight database files to be compared at one time. The output of osscompare is a text-based side-by-side listing with a column representing a key metric from the performance information of each of the database files being compared. (The information entity that the experiment is gathering. These entities can be time values, occurrence counters, a call chain, or other entity that reflects in some way on the application’s performance and is gathered by a performance experiment.) For example, a program counter sampling experiment could be run on an unmodified application; the code then could be changed and another program counter experiment run. The two database files could be quickly compared to analyze what effect the modifications had. The syntax for such a scenario could be:
- osspcsamp "mpirun –np 256 ./my_appl"
- Make source changes
- osspcsamp "mpirun –np 256 ./my_appl"
- osscompare "my_appl-pcsamp.openss,my_appl-pcsamp-1.openss"
Here is an example of a comparison of two smg2000 pcsamp experiment database files:
osscompare "smg2000-pcsamp.openss,smg2000-pcsamp-1.openss" [openss]: Legend: -c 2 represents smg2000-pcsamp.openss [openss]: Legend: -c 4 represents smg2000-pcsamp-1.openss -c 2, Exclusive CPU -c 4, Exclusive CPU Function (defining location) time in seconds. time in seconds. 3.870000000 3.630000000 hypre_SMGResidual (smg2000: smg_residual.c,152) 2.610000000 2.860000000 hypre_CyclicReduction (smg2000: cyclic_reduction.c,757) 2.030000000 0.150000000 opal_progress (libopen-pal.so.0.0.0) 1.330000000 0.100000000 mca_btl_sm_component_progress (libmpi.so.0.0.2: topo_unity_component.c,0) 0.280000000 0.210000000 hypre_SemiInterp (smg2000: semi_interp.c,126) 0.280000000 0.040000000 mca_pml_ob1_progress (libmpi.so.0.0.2: topo_unity_component.c,0)
There are several alternative comparison options for the osscompare command. Please see the man page for osscompare for the details.
Building and Installing Open|SpeedShop
Open|SpeedShop is built from a source tarball that can be downloaded from SourceForge. This tarball contains the Open|SpeedShop source and the source of several other open source components that are an integral part of Open|SpeedShop. At the top level of the build directory is a bash script named install.sh. A few key environment variables need to be set: one to tell the script where to install (OPENSS_PREFIX) and others to specify MPI installations as desired. If you do not set the key environment variables and execute the script, the script stops and asks you to set them. The script also checks to see if the required system-level development packages are installed, outputs warning messages, and asks a user to update if needed. If all system-level development packages are installed and the install location environment variable (OPENSS_PREFIX) is set, the script will build and install the source tarballs Open|SpeedShop requires. It then will build and install Open|SpeedShop.
After the build and install is complete, the run-time environment must be loaded to execute the tool. Most sites use module, Dotkit, or SoftEnv files to set up the PATH, LD_LIBRARY_PATH, and Open|SpeedShop-specific environment variables. Examples of each type of file are on the Open|SpeedShop website under the Build Information section. Users who have access to any of the systems under the Available Installations section of the Open|SpeedShop website might be able to use Open|SpeedShop without building their own version. Clean Linux distributions that are not set up for software development require some system-level development packages to be installed. The list of packages required is provided in the Build Information section on the Open|SpeedShop website.
Static Application Support on Cray and Blue Gene Platforms
The workflow for using Open|SpeedShop on static applications on the Cray and Blue Gene platforms differs from that described in the sections above. This web page for the NERSC Cray Open|SpeedShop installation and usage explains those differences.
Conclusions and Additional Information Sources
In this article, I outlined potential uses of Open|SpeedShop to find performance issues in sequential and parallel applications running on Linux clusters, as well as the Cray and Blue Gene platforms. The scenarios shown in this article can be supplemented by viewing the recent Open|SpeedShop tutorials and presentations found on the Open|SpeedShop website. In particular, the SciDAC 2011 and SuperComputing 2011 tutorials have extensive example usage scenarios that could be helpful. Developers using a hybrid (MPI and OpenMP) programming model might find this Open|SpeedShop hybrid performance analysis tutorial useful.
There are a number of ways to receive help with building and using Open|SpeedShop. One option is the Open|SpeedShop Forum, where users can ask questions and view previous questions and answers. Another option is to send email to the alias oss-questions@openspeedshop.org. You also may email the author directly.
The latest release is version 2.0.1 and is available for download on SourceForge at this location. Documentation is available in the form of man pages when Open|SpeedShop is installed, a downloadable version of the Open|SpeedShop Quick Start Guide, and a number of user guide documents that can be found on the Open|SpeedShop Documentation web page.
The Author
Jim Galarowicz is a Senior Computer Scientist at the Krell Institute and a full-time developer of Open|SpeedShop.
Acknowledgments
I thank the Open|SpeedShop team: Donald Maghrak, full-time developer; William Hachfeld, David Whitney, and Dane Gardner, part-time developers; and John Ziebarth, project manager, all of the Krell Institute, as well as project partners Martin Schulz (Lawrence Livermore), Dave Montoya (Los Alamos National Laboratory), and Mahesh Rajan (Sandia). I also thank Bill Cannon and Tom O’Donnell of the Krell Institute for reviewing this article before publication.