Database Tuning
In version 9.3, the PostgreSQL community once again introduces several important new features in a major release. The work of many developers worldwide, this release went through a rigorous review process (Commitfest) that ensures the quality of the source code. Typically, Commitfests see up to 100 patches; because of the sheer volume, the feature freeze deadline was regularly postponed. To compensate, the list of new features is impressive. In this article, I present the most important ones.
Parallel Dump
A feature long requested by users and developers is the ability to perform a simultaneous database dump using multiple threads or processes. PostgreSQL uses a multiprocess architecture, which means it does not use threads (not even on platforms such as Windows, which actually prefers them). To dump multiple objects in parallel with pg_dump , the program must therefore open multiple database connections. However, because pg_dump guarantees the consistency of a dump, even for concurrent transactions, the database connections that belong to pg_dump now need to be synchronized. This was what made developing this feature tricky.
The infrastructure implemented to handle this process is called “snapshot cloning,” which makes it possible for mutual synchronization of several transactions to the same state, although they use separate database connections. If you were to back up tables in parallel, and if these pg_dump transactions were not synchronized, data consistency between the tables could not be guaranteed. In this case, it would be possible for the concurrent processes to store new data in one of the tables during backup. Enter snapshot synchronization.
Basically, a transaction must first be started and can then be synchronized. All other transactions then import the snapshot generated in the process. The transaction then synchronizes this with its “parent transaction.” Both have the same view of the database state. Figure 1 illustrates the sequence.
First, a transaction is started. This must have a REPEATABLE READ or SERIALIZABLE degree of isolation; READ COMMITTED is not possible, because the snapshot changes after each command at this isolation level and is thus not permanent for the transaction.
With the use of the pg_export_snapshot() function, a snapshot can be exported in any transaction. The return value is a datum of the TEXT type with the snapshot identifier. This identifier can be imported into another transaction with the SET TRANSACTION SNAPSHOT command.
It should be noted that this must be the first command in the other transaction or must precede each SELECT , INSERT , UPDATE , or DELETE command. Furthermore, a transaction that you want to import with a SERIALIZABLE isolation level cannot import a transaction from a lesser isolation level. Once the snapshot has been imported, as in Figure 1, both transactions see the same database state. The records added to the bar table up front are no longer visible because the imported snapshot had not seen them when it was created.
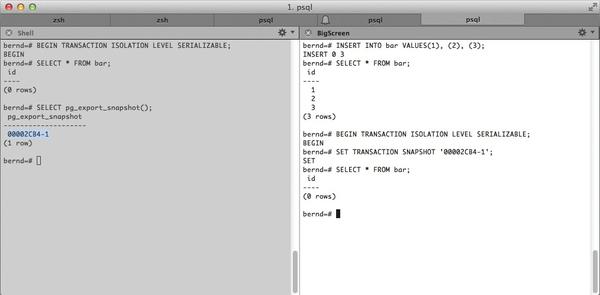 Figure 1: The second transaction (right) references a previously created snapshot; it thus sees the same data.
Figure 1: The second transaction (right) references a previously created snapshot; it thus sees the same data.
The pg_dump utility implements precisely this infrastructure to synchronize multiple dump processes. Parallel dump only works for the new directory output format. The pg_dump call for several synchronized dump processes uses the new parallel dump command-line parameter, -j :
pg_dump -j 4 -Fd -f /srv/backups/db/
The important thing to note is the output format specified by the -Fd command-line parameter (d = directory). The -f option specifies the output directory; it must not exist.
The pg_dump command in major new versions of PostgreSQL has always been backward-compatible with older versions to allow migrations. Parallel dump (-j ) is no exception and can be used, for example, in version 9.2 of PostgreSQL. In this case, pg_dump cannot provide synchronized snapshots; thus, no changes should be permitted to the databases for the duration of the dump to avoid inconsistencies. Alternatively, synchronized snapshots can be disabled explicitly using a command-line parameter (--no-synchronized-snapshots ) so that dumps can be created with multiple pg_dump processes in older versions.
Writable FDWs
PostgreSQL 9.1 already had a partial implementation of SQL/MED standards in place, which enabled the integration of external data sources in the form of a foreign table. This was previously only possible for read access, but in PostgreSQL 9.3, the API has been extended to include writes to these foreign tables.
External data sources are defined in such a way that they appear to the user to be local PostgreSQL tables. When queried, the records are converted at run time by means of a Foreign Data Wrapper (FDW) and displayed as a database row in the result set, in line with the table definition. A large number of FDWs for other database systems are already set up in PostgreSQL, including:
- Oracle
- MySQL
- Informix
- ODBC
- JDBC
- NoSQL sources: CouchDB, Redis, and MongoDB.
The FDW for PostgreSQL itself was introduced to the contrib branch of the database server in version 9.3; thus, tables from external PostgreSQL databases can be integrated. Furthermore, a PostgreSQL FDW already supports Data Modifying Language (DML) write queries with INSERT , DELETE , and UPDATE .
The various distributions usually provide these additional modules in the form of a postgresql-contrib package. If everything is installed properly, the PostgreSQL FDW can simply be enabled as an extension (Figure 2). The \dx command in psql returns all the currently installed extensions for a database.
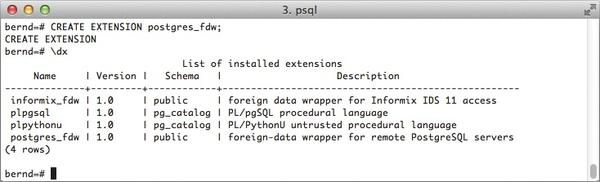 Figure 2: Adding a PostgreSQL FDW as a database extension.
Figure 2: Adding a PostgreSQL FDW as a database extension.
You don’t have to install an FDW on the remote database server, but you must ensure that the local database is granted access to the database you want, using pg_hba.conf . You can also stipulate popular PostgreSQL keywords for the database connection (e.g., host , dbname , port , etc.). However, user , password , failback_ application_name , and client_encoding are prohibited; the last two are set automatically by the FDW.
To use a PostgreSQL FDW to access a remote database server, you need to configure a matching data source with the CREATE SERVER command. The example I use here accesses a remote PostgreSQL server, archives.mynet.internal . First, however, the FDW must be loaded into the local database using CREATE EXTENSION :
CREATE EXTENSION postgres_fdw;
The data source for the remote database server can then be defined as in:
CREATE SERVER pg_archive_server FOREIGN DATA WRAPPER postgres_fdw OPTIONS(dbname 'archive', host 'archives.mynet.internal', port '5432');
To create a foreign table, you need to tell the data source which user can log in to the remote PostgreSQL instance and with what combination of role name and password. To do so, you need a user mapping. The CREATE USER MAPPING command takes care of this. The access credentials used here differ between individual FDWs; for PostgreSQL, the username is mandatory and the password can be optionally provided. The latter is imperative for a mapping for a user without superuser privileges. The CURRENT_USER keyword is automatically replaced by the role currently being used in the local database session.
CREATE USER MAPPING FOR CURRENT_USER SERVER pg_archive_server OPTIONS(user 'bernd', password 'bernd');
After creating a data source and a mapping for the access credentials for each data source, you can then create a foreign table. The local definition should correspond to the schema of the remote data source to the extent possible. In Listing 1, the local database is given a foreign table that stores email in an archive.
Listing 1: Foreign Table
01 CREATE FOREIGN TABLE mail( 02 id bigint not null, 03 label_id bigint, 04 mail_from text not null, 05 mail_to text not null, 06 msg text not null, 07 subject text not null, 08 msg_id text not null, 09 date timestamp) 10 SERVER pg_archive_server
This corresponds exactly to the definition on the archive server, but naturally without the keywords SERVER and OPTIONS , which are not required there. Now, the local database can easily use the archive table in local queries:
SELECT COUNT(*) FROM mail WHERE mail_from LIKE 'Tom Lane%'; count ------- 6238 (1 row)
When first run, the FDW is responsible for building an appropriate mapping for the user and setting up the target server database connection. This database connection is also cached for reuse for each user mapping in the local database session.
The PostgreSQL FDW not only supports read operations but also writes DML. If transactions or save points are used in the local database, the PostgreSQL FDW also links these with transactions or savepoints in the remote database. This means that a ROLLBACK of the local databases also rolls back any changes to a remote PostgreSQL data source.
New Features with Streaming Replication
Introduced in version 9.0, built-in replication using the streaming replication method has seen steady improvements from one major version to the next. PostgreSQL 9.3 also remains true to this tradition and improves the handling of streaming replication in the event of a primary server failover or recovery.
If the primary server is restored by means of an online backup or failed over to another standby streaming replication, the affected PostgreSQL instance changes the timeline, which the database server’s transaction log adheres to.
Besides the possibility of promoting a PostgreSQL Hot Standby server to a full PostgreSQL instance using the trigger_file parameter, PostgreSQL also provides the option of doing this by running the pg_ctl promote command.
In version 9.3, you also have the option of making the standby a full, writable instance without waiting for a checkpoint. You need the -m fast command-line option for this, which can save you a longer wait before the instance is available for writing.
More Memory
Up to and including PostgreSQL 9.2, it was impossible to use more than 2GB effectively for the maintenance_work_mem or work_mem settings to sort data in RAM because of a limitation hard-coded into the database. This restriction is very significant, especially for DDL commands that use these parameters. For example, the CREATE INDEX command now effectively benefits from a high setting in maintenance_work_mem if very large indexes need to be generated. Sorting to build the index can then ideally be handled completely by Quicksort in the database server’s RAM, without having to resort to the storage system.
Legacy systems have always set this option to a high value (even if it was never actually used), but the value needs to be checked during migration; otherwise, there is a risk that the system will suddenly making correspondingly high memory allocations to reflect the setting.
Indexable Regular Expressions
Previous versions of PostgreSQL were able to index regular expressions using expression indexes. However, this only worked for static regular expressions, and if more words had to be indexed, it quickly became ineffective because of the number of required indexes. In version 9.3, PostgreSQL now has the ability to accelerate dynamic regular expressions using a special index.
The pg_trgm contrib module was extended in PostgreSQL 9.3 so that it can respond to arbitrary regular expressions via an index. Because it is also in the contrib branch of the database, you must install it retroactively using CREATE EXTENSION . Listing 2 shows an example with the mail table that creates an index and compares the execution schedules with and without an index. The differences in costs and execution times with and without the index show a significant boost to the query speed.
Listing 2: Create Extension
01 CREATE EXTENSION pg_trgm; 02 CREATE INDEX ON mail USING gin(msg gin_trgm_ops); 03 04 EXPLAIN ANALYZE SELECT * FROM mail WHERE msg ~ '(updatable|views)'; 05 QUERY PLAN 06 ---------------------------------------------------------------------------------------------------- 07 Bitmap Heap Scan on mail (cost=128.03..143.74 rows=4 width=961) (actual 08 time=35.454..175.184 rows=672 loops=1) 09 Recheck Cond: (msg ~ '(updatable|views)'::text) 10 Rows Removed by Index Recheck: 978 11 -> Bitmap Index Scan on mail_msg_idx (cost=0.00..128.03 rows=4 width=0) 12 (actual time=34.925..34.925 rows=1650 loops=1) 13 Index Cond: (msg ~ '(updatable|views)'::text) 14 Total runtime: 175.403 ms 15 (6 rows) 16 17 EXPLAIN ANALYZE SELECT * FROM mail WHERE msg ~ '(updatable|views)'; 18 QUERY PLAN 19 ---------------------------------------------------------------------------------------------------- 20 Seq Scan on mail (cost=0.00..5628.25 rows=4 width=961) (actual 21 time=2.401..1519.809 rows=672 loops=1) 22 Filter: (msg ~ '(updatable|views)'::text) 23 Rows Removed by Filter: 40148 24 Total runtime: 1.519.991 ms 25 (4 rows)
LATERAL Statement
Version 9.3 of PostgreSQL now supports LATERAL as defined in the SQL standard. This keyword allows the developer to use sub-selects to reference other columns or values of the join operation from within joins.
A simple example will illustrate this: In general, it has so far not been possible in PostgreSQL to use the result of a join partner as a function argument in a function.
However, PostgreSQL 9.3, as Listing 3 shows, provides a simplified example of a set-returning function (SRF).
Listing 3: Set-Returning Function
01 CREATE OR REPLACE FUNCTION get_book_by_authorid(IN integer) 02 RETURNS SETOF text 03 STRICT 04 LANGUAGE SQL 05 WP 06 $$ 07 SELECT b.title FROM book b WHERE author_id = $1; 08 $$; 09 10 book =# SELECT * FROM author a, get_book_by_authorid(a.id); 11 ERROR: function expression in FROM cannot refer to other relations of same 12 query level 13 LINE 1: SELECT * FROM author a, get_book_by_authorid(a.id); 14 15 SELECT * FROM author a, LATERAL get_book_by_authorid(a.id); 16 17 id | name | get_book_by_authorid 18 ----+------------------+-------------------------------------- 19 1 | Bernd Helmle | PostgreSQL Administration 20 2 | Andreas Eschbach | One Trillion Dollars 21 3 | Mario Puzo | The Godfather 22 4 | Peter Eisentraut | PostgreSQL Administration 23 4 | Peter Eisentraut | PostgreSQL - The Official Guide 24 (5 rows)
LATERAL is particularly interesting for join partners such as sub-selects. The same rules apply: Previous link partners can be referenced directly with LATERAL in the sub-select definition. The LATERAL keyword is mandatory here, as shown in Listing 4.
Listing 4: LATERAL
01 SELECT 02 a.id, a.name, t.title 03 FROM author a, 04 (SELECT author_id, title FROM book b WHERE b.author_id = a.id AND b.title LIKE '%PostgreSQL%') AS t; 05 ERROR: invalid reference to FROM-clause entry for table "a" 06 LINE 1: ...CT author_id, title FROM book b WHERE b.author_id = a.id) AS t... 07 ^ 08 HINT: There is an entry for table "a", but it cannot be referenced from this part of the query. 09 </box> 10 11 # But LATERAL makes this join correct: 12 13 <box> 14 SELECT 15 a.id, a.name, t.title 16 FROM author a, 17 LATERAL (SELECT author_id, title FROM book b WHERE b.author_id = a.id AND b.title LIKE '%PostgreSQL%') AS t; 18 id | name | title 19 ----+------------------+-------------------------------------- 20 1 | Bernd Helmle | PostgreSQL Administration 21 4 | Peter Eisentraut | PostgreSQL Administration 22 4 | Peter Eisentraut | PostgreSQL - The Official Guide 23 (3 rows)
For complex subqueries within joins, this is a significant improvement; however, it should not lead programmers always to formulate join subqueries in this way. The previous example can easily be rewritten as a conventional JOIN .
COPY FREEZE
When a large amount of data is loaded into an archive table, the approach used before PostgreSQL 9.3 was to perform a subsequent VACUUM FREEZE on the relation if the records were guaranteed not to change later on.This approach had the advantage that you could possibly save a VACUUM FREEZE in production operations later on, possibly under a heavy transaction load. In any case, it removes the need for a computationally expensive additional scan of the entire table later on, which is a huge timesaver, especially for large data sets.
In PostgreSQL 9.3, you now have the option of doing this immediately while loading the data into a table in a single pass. The COPY command now has a FREEZE parameter.
To work correctly, a COPY with FREEZE requires some conditions be fulfilled. For example, the target table must be created in the same transaction or subtransaction that issues the COPY command. Also, no CURSOR can be open for the table. The following simple example
BEGIN; CREATE TABLE t3(LIKE t2); COPY archive_tbl FROM '/Users/bernd/tmp/archive.dat' FREEZE CSV; COMMIT;
shows the use of COPY FREEZE with a CSV file.
Event Trigger
Users frequently requested triggers when performing certain DDL commands. Triggers can be used to track changes to the database itself – for example, with replication systems (e.g., Slony-I) that rely on being notified of changed objects.
An event trigger is produced using the CREATE TRIGGER EVENT command, which uses the same syntax as CREATE TRIGGER ; that is, the trigger function must be defined in advance. Listing 5 shows an example that denies all ALTER TABLE commands in a database with an error.
Listing 5: Event Trigger
01 CREATE OR REPLACE FUNCTION public.deny_alter_table()
02 RETURNS event_trigger
03 LANGUAGE plpgsql
04 AS $function$
05 BEGIN
06
07 RAISE EXCEPTION '% is disabled', TG_TAG;
08
09 END;
10 $function$
11
12 CREATE EVENT TRIGGER etg_deny_alter_table
13 ON ddl_command_start
14 WHEN tag IN ('ALTER TABLE')
15 EXECUTE PROCEDURE deny_alter_table();
16
17 ALTER TABLE test ADD COLUMN another_col integer;
18 ERROR: ALTER TABLE is disabledBesides the ddl_command_start event trigger event, there are also the ddl_command_end and SQL_DROP events. dl_command_start is executed before running the respective DDL command and ddl_command_end , accordingly, before the DDL command is terminated. Event triggers with the SQL_DROP event are executed before the ddl_command_end event trigger for all objects that are removed within the event.
Event triggers currently can be implemented in PL/pgSQL or C. A CREATE EVENT TRIGGER command itself cannot trigger an event trigger.
Checksums
In PostgreSQL 9.3, database blocks written to disk can be checksummed to help diagnose hard disk problems by unambiguously detecting data corruption. This is interesting especially for systems running on fairly unreliable hardware. You must specify whether to use checksums when you initialize the PostgreSQL instance using initdb or the new --data-checksums command-line parameter. This feature cannot be enabled or disabled retroactively. Moreover, it is effective for all databases and objects.
The checksums are written and checked at the block level for all database objects such as tables or indexes. Confirmation of checksums cannot be deactivated for individual objects, and enabling checksums will affect the speed of the database.
Improved Concurrency for Foreign Keys
The FOR SHARE or FOR UPDATE lock types have been used for changes to data relying on foreign keys to refererence tables. Unfortunately, this led to massive locking for many concurrent changes, which could impair application speed significantly.
PostgreSQL 9.3 offers two new lock types: FOR KEY SHARE and FOR NO KEY UPDATE . These lock types do not block each other. Now, if a tuple that has a foreign key is updated and the key is not a part of the update, a FOR NO KEY UPDATE lock request is issued. Tests of foreign key integrity have always been implemented as implicit triggers in PostgreSQL. Now, instead of FOR SHARE , they use FOR KEY SHARE , which speeds up most applications that have this kind of database requirement profile. In general, foreign key values are only rarely updated as such.
Background Worker API
For quite some time, the PostgreSQL community has been thinking about background processes that can be started in addition to the normal database connections – also separate processes – and can handle dedicated tasks, such as the periodic execution of specific tasks or commands.
PostgreSQL 9.3 provides the infrastructure and API necessary to implement background processes. A reference implementation is provided in the worker_spi contrib module, where interested developers can study the required steps.
Background processes launch when the database instance starts up and remain active throughout the duration of the instance. If a background process terminates, it is immediately restarted by the PostgreSQL database server.
Conclusions
The new features and additions described in this article represent the most important and far-reaching changes in PostgreSQL 9.3. A much larger number of smaller, but still significant, changes have been made, as well, especially related to speed improvements of the database server or streaming replication. These improvements alone are reason enough to justify taking a look at the new version.
The JSON data type introduced in PostgreSQL 9.2 now has a comprehensive set of additional functions for data access and manipulation. This functionality, in particular, simplifies interaction between interactive web applications and the database, for example, via scripting languages that themselves have extensive JSON functionality.
With the advent of DML-enabled FDWs in particular, PostgreSQL 9.3 has developed into a multifunction tool in heterogeneous, distributed database environments.
Related content
-
New in PostgreSQL 9.3
 The new PostgreSQL 9.3 release introduces several speed and usability improvements, as well as SQL standards compliance.
The new PostgreSQL 9.3 release introduces several speed and usability improvements, as well as SQL standards compliance. -
What's new in PostgreSQL 9.4
 The PostgreSQL Global Development Group recently introduced the new major version 9.4 of the popular free database, which includes innovative functions as well as a whole range of changes regarding speed and functionality.
The PostgreSQL Global Development Group recently introduced the new major version 9.4 of the popular free database, which includes innovative functions as well as a whole range of changes regarding speed and functionality. - PostgreSQL 15 Released
- A Quick Guide to Setting Up PostgreSQL
-
PostgreSQL 9.5 – What's new; what's better?
 As expected, a further release of the PostgreSQL open source database system was launched last fall, offering a number of impressive new features.
As expected, a further release of the PostgreSQL open source database system was launched last fall, offering a number of impressive new features.
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
