« Previous 1 2
A Hands-on Look at Kubernetes with OpenAI
Learning in Containers
GPU Scheduling
Graphics processors do most of the calculations in the field of deep learning, because the individual "neurons" of the network, similar to the pixels of a screen, act independently of each other. Computer games, for example, use this parallelism for hardware-accelerated 3D rendering. OpenAI relies on Nvidia's CUDA [9] to map neural networks using GPUs (Figure 3).
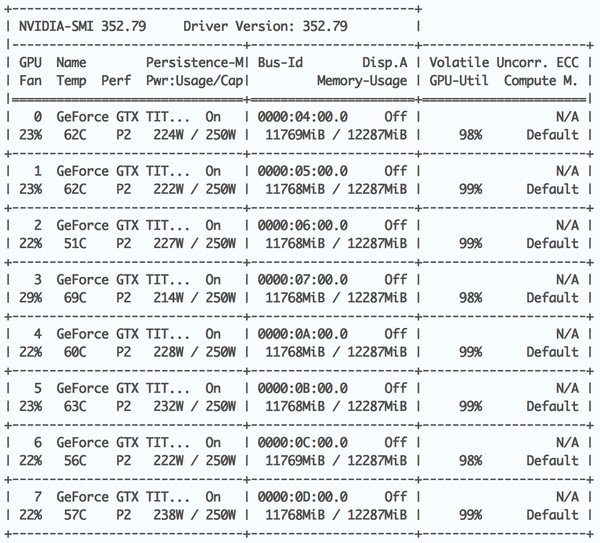 Figure 3: Nvidia's system management interface nvidia-smi – top for GPUs – reports on a machine with eight fully utilized Nvidia graphics processors.
Figure 3: Nvidia's system management interface nvidia-smi – top for GPUs – reports on a machine with eight fully utilized Nvidia graphics processors.
In connection with Kubernetes, the problem is managing multiple GPUs as well as other resources (CPU, RAM, etc.). For example, suppose you have a node comprising 64 cores and eight Nvidia graphics cards. A pod requires 16 CPU cores and two graphics cards for experiments. You are probably wondering how you can notify the Kubernetes scheduler of these resource requirements.
The CPU part is easy: Set the spec.containers[].resources.requested.cpu field to 16; Kubernetes will never place more than four such pods on the node, so it does not exceed the specified capacity.
To negotiate which pods get which GPUs, you use good old flock(2) [10] inside the pods to secure exclusive locks on GPU devices /dev/nvidia<X>, where <X> is a value between 1 and 8 (Figure 4).
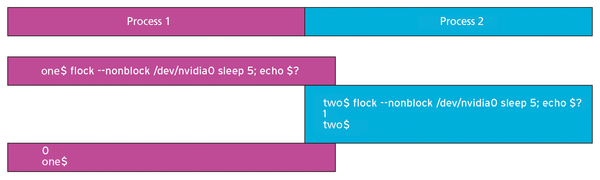 Figure 4: Ensuring exclusive access to the graphics card. The second process detects whether the first process has already used the resource.
Figure 4: Ensuring exclusive access to the graphics card. The second process detects whether the first process has already used the resource.
Originally, Kube could not do much with GPUs, so the schema above only worked if the relationship between the CPU and GPU was constant. If another pod required 16 CPU cores but eight graphic cards, without batting an eye, Kube would place that pod on the same node; all of a sudden, you ran out of GPUs. The solution was to split the nodes into several classes using labels and only place a certain type of pod in a class. It was certainly not ideal, but it fulfilled its purpose.
Meanwhile, since version 1.6, Kubernetes has natively supported GPU scheduling. Thus, the hack was replaced with a clean version, but without changes visible to users [11]. This is also a good example of how the infrastructure team handles such changes to Kubernetes without the assistance of all users.
Teething Problems
One potential performance bottleneck in the operation of Kubernetes is communication between the Kubernetes master and the Kubelet, the program that runs on each of the nodes and launches and manages the pod container. When the clusters used by the company became bigger over time, it turned out that there was a surprisingly large volume of traffic – one of the clusters with about 1,000 nodes generated about 4-5GBps of data. (By the way, the Kubernetes master spent about 90 percent of its time encoding and decoding JSON.)
Kubernetes assumes that all nodes on a fast and cheap network communicate with one another. If you want to stretch a single Kubernetes cluster across multiple data centers, you need to dig deep into your bandwidth pockets. Only since version 1.6 was released in March 2017 has communication between the components become far more efficient, thanks to gRPC (Google's RPC framework), which uses protocol buffers, not JSON. Nevertheless, latencies of a few hundred milliseconds can still lead to problems or slow response times when you run kubectl (Kubernetes command-line interface) commands.
Another surprise may be that some elements of Kube work on the "eventual consistency" principle, so the effect of an instruction is only realized after some time. For example, the service resource in Kubernetes follows the principle that facilitates load balancing between multiple pods:
1. Someone (e.g., the replica set controller) generates a new pod, which is part of the service.
2. The scheduler positions the pod, and the Kubelet launches the container.
3. The service controller generates the service endpoint for the pod in a corresponding service.
The pod runs in the period between steps 2 and 3 but is not visible to the service. No wonder the pod doesn't respond to HTTP requests to the service. Normally this isn't a problem, because this period is very small. However, it sometimes takes several minutes for large clusters with thousands of services and pods and posed a big problem for our company, because our experiments needed several minutes to launch.
After a bit of research, it soon became apparent that the service controller is a single process that iterates across all services in a for loop and activates new pods (i.e., creates the service endpoints). Kubernetes hides all this behind the service abstraction. As a symptom, you can only see that your service is down without knowing why.
In addition to performance problems with large clusters, the Kube abstractions are unclean ("leaky") in other areas. The previously mentioned autoscaler ensures that the size of the cluster adapts to the requirements; to do this, it launches new nodes or removes excess nodes from the cluster. However after a few months of intensive use, it transpires that Kubernetes does not always deal well with emerging and disappearing nodes: For example, it deletes logging output from pods when the underlying node goes offline, although the pod itself still exists.
Many of these details are not yet sufficiently tested and documented because Kube is still too new; delving deep into the source code [12] was therefore unavoidable in the end.
Conclusions
After one and a half years of intensive use, our impression is that Kubernetes provides well-designed, Unix-compatible data structures and APIs to create an interface between the users and operators of an infrastructure. This interface offers flexibility to users when faced with changing requirements and for the operators when deploying new cloud resources. The users of the infrastructure do not need to know all the details; the Kube API can serve as an organizational interface between the infrastructure team and other teams.
However, Kubernetes is not a panacea and does not replace an experienced team of administrators. An out-of-the-box installation package provides a Kube cluster with a single Bash script, but what looks simple can be deceptively complex. The ready-made cluster, at least, is not sufficient for the requirements of OpenAI; it still does not pay sufficient attention to the changing needs of system users who want to connect to a new cloud provider or other external systems, such as databases, and who need some additional features, such as the previously mentioned GPU scheduling.
One great strength of Kubernetes, which I've previously neglected, is the open source developer community [13]. New Kube versions usually trigger great anticipation, especially in projects, because the users appreciate the time savings they will experience in the future with access to the new features.
Under the management of the Cloud Native Computing Foundation, supported by the Linux Foundation and Google, the Kubernetes ship is making good headway – and at an impressive speed.
Infos
- OpenAI: https://openai.com
- Elon Musk: https://en.wikipedia.org/wiki/Elon_Musk
- Y Combinator: http://www.ycombinator.com
- Learning robot: https://blog.openai.com/robots-that-learn/
- Docker: https://www.docker.com
- Kubernetes: https://kubernetes.io
- TensorFlow deep learning framework: https://www.tensorflow.org
- Autoscaler: https://github.com/openai/kubernetes-ec2-autoscaler
- Nvidia CUDA: http://www.nvidia.com/object/cuda_home_new.html
- flock(2): https://linux.die.net/man/2/flock
- GPU scheduler: https://kubernetes.io/docs/tasks/manage-gpus/scheduling-gpus/
- Kubernetes source code: https://github.com/kubernetes/kubernetes
- Kubernetes News: http://kube.news
« Previous 1 2
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
Kubernetes clusters within AWS EKS
 Automated deployment of the AWS-managed Kubernetes service EKS helps you run a production Kubernetes cluster in the cloud with ease.
Automated deployment of the AWS-managed Kubernetes service EKS helps you run a production Kubernetes cluster in the cloud with ease. -
Linking Kubernetes clusters
 When Kubernetes needs to scale applications, it searches for free nodes that meet a container's CPU and main memory requirements; however, when the existing hardware is at full capacity, the Kubernetes Cluster Federation project (KubeFed) takes the pain out of adding clusters.
When Kubernetes needs to scale applications, it searches for free nodes that meet a container's CPU and main memory requirements; however, when the existing hardware is at full capacity, the Kubernetes Cluster Federation project (KubeFed) takes the pain out of adding clusters. - Turing Pi Now Offers a Raspberry Pi Kubernetes Cluster
-
Run Kubernetes in a container with Kind
 Create a full-blown Kubernetes cluster in a Docker container with just one command.
Create a full-blown Kubernetes cluster in a Docker container with just one command. -
Kubernetes Auto Analyzer
 The fast pace of Kubernetes development can patch and introduce security vulnerabilities between versions. The Kubernetes Auto Analyzer configuration analyzer tool automates the review of Kubernetes installations against CIS Benchmarks.
The fast pace of Kubernetes development can patch and introduce security vulnerabilities between versions. The Kubernetes Auto Analyzer configuration analyzer tool automates the review of Kubernetes installations against CIS Benchmarks.
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
