« Previous 1 2
Kafka: Scaling producers and consumers
Smooth
According to the Kafka home page [1], "Apache Kafka is an open-source distributed event streaming platform … for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications." A basic Kafka ecosystem has three components – producers, brokers, and consumers. Although much has been written about tuning brokers, reliably configuring producers and consumers is something of a dark art. All systems are dependent on your local setup, but some standard metrics that you can look at and knobs that can be tuned can increase performance 10 times or more. In this article, I walk through a real-life(-ish) example of how to diagnose and then fix a bottlenecked stream-processing system.
Assume you are mirroring data from an edge Kafka cluster into a central Kafka cluster that will feed your analytics data warehouse (Figure 1). You've set up the edge with 100+ partitions for many of the topics you are consuming (because you had the forethought to expect scale and knew partitions are generally pretty cheap – go you!). That means you could easily be mirroring 1000+ partitions into your central Kafka for each edge cluster.
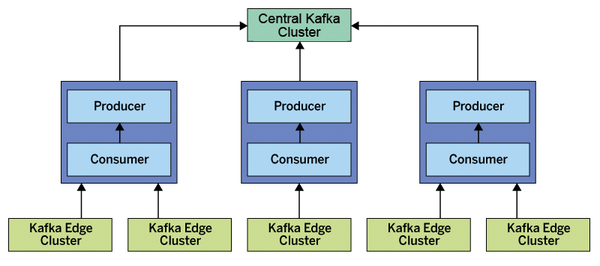 Figure 1: The data generated
Figure 1: The data generatedBuy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
Related content
-
Processing streaming events with Apache Kafka
 Apache Kafka reads and writes events virtually in real time, and you can extend it to take on a wide range of roles in today's world of big data and event streaming.
Apache Kafka reads and writes events virtually in real time, and you can extend it to take on a wide range of roles in today's world of big data and event streaming. -
Agentless automation with Event-Driven Ansible
 Event-Driven Ansible is a reactive extension that uses events to launch automations. We explain the ruleset and present examples that show how to monitor logs and call other tools.
Event-Driven Ansible is a reactive extension that uses events to launch automations. We explain the ruleset and present examples that show how to monitor logs and call other tools. -
A watchdog for every modern *ix server
 Monit is a lightweight, performant, and seasoned solution that you can drop into old running servers or bake into new servers for full monitoring and proactive healing.
Monit is a lightweight, performant, and seasoned solution that you can drop into old running servers or bake into new servers for full monitoring and proactive healing. -
Tracking down problems with Jaeger
 The various components of cloud-native applications are always exchanging information, which makes troubleshooting difficult. The Jaeger tracing framework helps hunt down the perpetrators.
The various components of cloud-native applications are always exchanging information, which makes troubleshooting difficult. The Jaeger tracing framework helps hunt down the perpetrators.
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
