« Previous 1 2 3 Next »
Application-aware batch scheduler
Eruption
Multipod Analytics and AI
Unlike the simple single-pod example, typical Kubernetes-native AI/ML applications require that several pods be scheduled simultaneously or in a certain order. A good example of this is the Kubernetes implementation of Apache Spark [3], a distributed analytics engine on which users can run SQL-type queries across large datasets. "Distributed" in this case means that a program is controlled by a driver process and split up into a workflow with parallel tasks shared between a number of executor processes. In the Kubernetes context, the driver is one pod, and each executor is another pod, and they all have to run simultaneously for the Spark application to succeed.
Another example is the Kubeflow Training Operator, which is designed to work closely with the PyTorch library to train AI models – neural networks – on large datasets with multiple GPU-enabled pods. Submitting a single PyTorch training job to the Kubernetes cluster requires the cluster to have the requested number of GPUs available for the model training to succeed. I'll give an example of each in turn, to show how creating such jobs can cause a state of scheduling deadlock in the cluster and how the use of the Volcano scheduler can help.
Scheduling Deadlock
Imagine a team of data scientists running their Apache Spark jobs on a shared Kubernetes (K8s) cluster [3]. On aggregate, the cluster contains ample resources for the whole team, but not enough to run all their jobs simultaneously. Section 3 of the GitHub repository [1] shows how Apache Spark can be downloaded, compiled for use with Kubernetes and Volcano, and containerized. It also shows the JAR files and configuration (spark-defaults.conf) needed to enable it for S3 access to work with the MinIO object store used in the single-pod workload example. In this example, I'll run a word count on the same file as before, but as a Spark job distributed between one driver and two executor pods, requesting one CPU each. The first Spark command runs just a single instance of this job:
export APISERVER=<K8s API server URL> spark-submit --master k8s://$APISERVER --deploy-mode cluster --name spark-wordcount --class org.apache.spark.examples.JavaWordCount local:///opt/spark/examples/jars/spark-examples_2.12-3.5.2.jar s3a://data/war-and-peace.txt watch kubectl get po
You'll see that the Spark driver pod is created first. After it has been running for a minute or so, it'll create a couple of executor pods (you set the number of executors in spark-defaults.conf). The pods will run together for a few seconds more, the executors will terminate, and you'll be left with the driver pod in the Completed state with its logs (again, accessible with kubectl logs) showing the results of the word count.
Now, say that six data scientists simultaneously submit Spark jobs, which is simulated with a for loop that runs each Spark command as a background process (by suffixing it with the & character):
for i in $(seq 1 6); do spark-submit --master k8s://$APISERVER --deploy-mode cluster --name spark-wordcount --class org.apache.spark.examples.JavaWordCount local:///opt/spark/examples/jars/spark-examples_2.12-3.5.2.jar s3a://data/war-and-peace.txt & done watch kubectl get po
This example shows that the driver pods of all six jobs start running at about the same time. Each driver is trying to create its two executor pods, but none of them can, because all of the cluster's six available CPUs are consumed by the driver pods themselves (Figure 4).
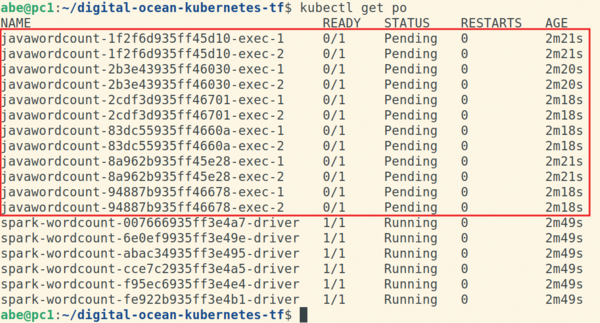 Figure 4: Scheduling deadlock of Apache Spark executor pods.
Figure 4: Scheduling deadlock of Apache Spark executor pods.
The drivers keep running for a while before entering the Error state and the Spark jobs just hang until the administrator comes to clean things up. As you can probably tell, I conveniently chose the number of jobs and the pod specifications to trigger this sad state of affairs, but it can easily happen in real life, especially if corporate keeps a close eye on your departmental cloud spend.
Volcano Scheduler
The open source project Volcano [4] was created to solve exactly the problem described here. It is a Kubernetes batch scheduler for workloads that require multiple pods to be scheduled in a timely manner, which it does by creating the custom resources PodGroup and Queue and implementing them with its own admission controller, ControllerManager, and scheduler that operate in parallel to the standard Kubernetes control plane.
When you create a PodGroup, you specify the minimum number of member pods and the minimum amount of resources that the cluster must be able to provide for any pod labeled as being a member of the group to be scheduled. None of the pods in the group will be scheduled until the cluster can provide the resources specified in the PodGroup (in terms of compute resources and pod numbers), and PodGroups can be added to any chosen Queue object; Queues can be assigned different priorities to give further control over how resources are allocated. The following commands install Volcano with Helm and show the new custom resources created:
helm repo add volcano-sh https://volcano-sh.github.io/helm-charts helm repo update helm install volcano volcano-sh/volcano -n volcano-system --create-namespace kubectl api-resources | grep volcano
Listing 1 shows the relevant additions made to the spark-defaults.conf file to configure Spark to use Volcano as its scheduler. The complete file is available in the project Git repository [1]. With this configuration, Spark's Kubernetes integration will create all pods for a certain job as members of the same PodGroup, allowing Volcano to gang-schedule them together and avoid the deadlock situation created by partially created jobs.
Listing 1
Additions to spark-defaults.confi
#VOLCANO spark.kubernetes.scheduler.name=volcano spark.kubernetes.scheduler.volcano.podGroupTemplateFile=/home/abe/spark-on-k8s/podgroup-template.yaml spark.kubernetes.driver.pod.featureSteps=org.apache.spark.deploy.k8s.features.VolcanoFeatureStep spark.kubernetes.executor.pod.featureSteps=org.apache.spark.deploy.k8s.features.VolcanoFeatureStep
When you rerun the spark-submit command, it's exactly the same as before, only now you are leveraging Volcano, and all the jobs are executed quickly. Figure 5 shows the details of one of the PodGroups, and Figure 6 shows all of the pods that were created. It's not clear from the pod names, but each of the two running Spark driver pods has two running executor pods. The other driver pods are pending, and the remaining executor pods have not been created at all (because they are created by their associated driver pod).
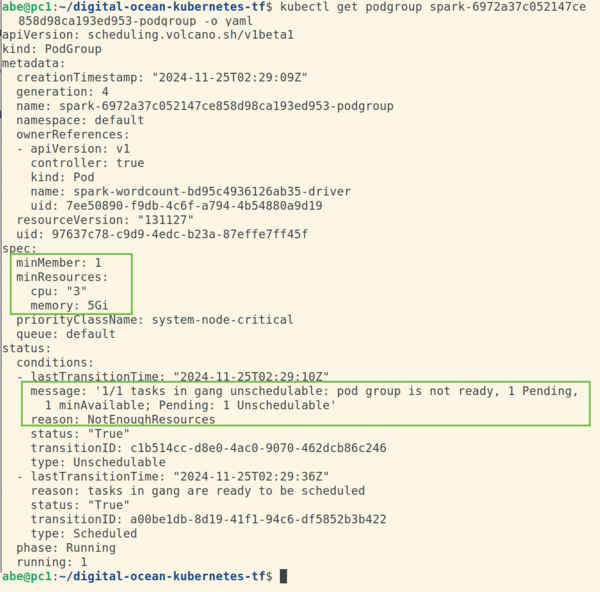 Figure 5: Example of a PodGroup created by Spark, showing that the group requires a total of three CPU resources to run. The group has transitioned from the Unschedulable (Pending) to the Running (Scheduled) state.
Figure 5: Example of a PodGroup created by Spark, showing that the group requires a total of three CPU resources to run. The group has transitioned from the Unschedulable (Pending) to the Running (Scheduled) state.
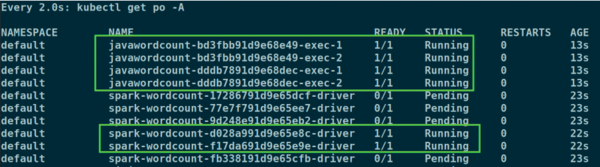 Figure 6: When configured to use Volcano, Spark will assign all pods for a given Spark job (driver and executors) to the same PodGroup, ensuring they are gang-scheduled. While all cluster resources are occupied with Running pods, all the pods for Pending jobs must wait together.
Figure 6: When configured to use Volcano, Spark will assign all pods for a given Spark job (driver and executors) to the same PodGroup, ensuring they are gang-scheduled. While all cluster resources are occupied with Running pods, all the pods for Pending jobs must wait together.
« Previous 1 2 3 Next »
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
Kick-start your AI projects with Kubeflow
 Training language models and AI algorithms requires a powerful infrastructure that is difficult to create manually. Although Kubeflow promises a remedy, it is itself a complex monster … unless you are familiar with the right approach that lets you get it up and running fairly quickly.
Training language models and AI algorithms requires a powerful infrastructure that is difficult to create manually. Although Kubeflow promises a remedy, it is itself a complex monster … unless you are familiar with the right approach that lets you get it up and running fairly quickly. -
Persistent storage management for Kubernetes
 The container storage interface (CSI) allows CSI-compliant plugins to connect their systems to Kubernetes and other orchestrated container environments for persistent data storage.
The container storage interface (CSI) allows CSI-compliant plugins to connect their systems to Kubernetes and other orchestrated container environments for persistent data storage. -
An open source object storage solution
 We introduce the MinIO high-performance object store, its key features and applications, and some performance tips.
We introduce the MinIO high-performance object store, its key features and applications, and some performance tips. -
Kubernetes containers, fleet management, and applications
 Kubernetes is all the rage, but many admins find themselves struggling to get started. We present the basic architecture and the most important components and terms.
Kubernetes is all the rage, but many admins find themselves struggling to get started. We present the basic architecture and the most important components and terms. -
Nested Kubernetes with Loft
 Kubernetes has limited support for multitenancy, so many admins prefer to build multiple standalone Kubernetes clusters that eat up resources and complicate management. As a solution, Loft launches any number of clusters within the same control plane.
Kubernetes has limited support for multitenancy, so many admins prefer to build multiple standalone Kubernetes clusters that eat up resources and complicate management. As a solution, Loft launches any number of clusters within the same control plane.
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
