Creating and Evaluating Kernel Crash Dumps
A dump of the operating system kernel as a means of problem analysis is nothing new in the Unix world. However, this topic has been sadly neglected on Linux for a long time. The first attempts were made in 1999 with the Linux Kernel Crash Dump (LKCD) project. This approach originally initiated by SGI was successful in that it made its way into the SUSE Enterprise distribution; however, the problem of writing a dump to an MD RAID or transferring larger kernel images ultimately proved unfixable.
Further attempts with Netdump (Red Hat) or Diskdump in 2002 and 2004 also had only moderate success. Meanwhile, an approach that can be used reliably in production environments comes in the form of kexec and kdump. A core issue and the biggest challenge in writing kernel dumps is: Who should do it? The obvious answer is surely: the kernel itself. However, this approach, which the LKCD project pursued, involves some risks.
How far can you trust a kernel that just crashed? Are the kernel structures and data intact? Are the drivers still correctly initialized so that the hard drive or the NFS share is accessible? These are exactly the problems that LKCD encountered.
It would be preferable to use an entity outside of the kernel to save the kernel dumps. With the growing proliferation of virtualization, a hypervisor is an obvious candidate for this, and you can use VMware, Xen, or KVM to save a dump of the Linux kernel – but I’ll get to that later.
If Linux is running directly on the metal, the hypervisor approach is worthless, which is where kdump – or, more precisely, kexec – enters the game. The kexec tool is a kind of kernel-to-kernel bootloader, and the current kernel can use it to load and run a new kernel. The BIOS plays no part in this, and it is up to the new kernel to decide whether to leave the content of memory untouched or to delete certain entries.
This new kernel, known as the crash or dump kernel, starts a part of the remaining Linux system and saves the dump. For kexec to work, admins need three things: a 2.6.13 kernel or newer, a kernel configured for kexec, and the corresponding userland tools (Figure 1).
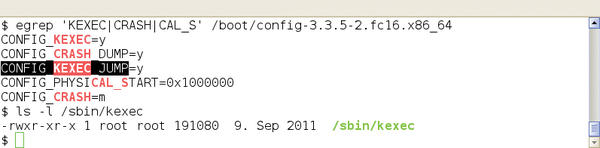 Figure 1: Dependencies for kdump/kexec must be met both on the kernel side and in userland.
Figure 1: Dependencies for kdump/kexec must be met both on the kernel side and in userland.
Kernel Loads Kernel
Booting a new kernel from the context of a running kernel sounds easier than it is. Before version 2.6.26, the Linux kernel could only boot from a single specified memory address, and this was, of course, already occupied by the current kernel. Additionally, the memory area of the new kernel requires protection from data being overwritten by continuous direct requests to main memory (DMA).
Finally, the new kernel needs to access certain information from the time of the crash and, thus, needs to know where the old operating system kernel resides in memory. Fortunately, the administrator does not need to worry about this seemingly hopeless mission. This job is handled by the kexec command and the kexec_load system call. The former loads the new kernel into a reserved memory area and is responsible for execution in collaboration with the system call.
The specific configuration of the kexec/kdump duo is a little different for each Linux distribution, so I’ll describe the approach on a more generic level on the basis of Red Hat’s and SUSE’s enterprise distributions (RHEL 6.2 and SLES 11 SP2). Admins have the choice between a completely manual configuration with rpm and vi or emacs or the use of the manufacturer’s system tools. In the case of SLES, you need to use the yast2-kdump module; for RHEL, use system-config-kdump .
To begin, you need to install the tools for booting the crash kernel and writing the dumps. The appropriate package is usually called kexec-tools or something similar. You might need to install the crash kernel. In older distributions, a separate package exists for this. Here, kexec loads a new binary file.
Kernel to Crash
Today, distributors take a different approach: The normal kernel has all the required features and can also serve as a crash kernel. This is the case for the current versions of RHEL and SLES, for which loading another kernel package is not necessary.
The next step is the configuration of kexec and kdump . The former is responsible for loading and running the crash kernel. For this to happen, the tool needs to know which kernel to load, where it is located, and whether any additional kernel options are necessary. The kdump configuration determines the settings for writing the kernel dump. These include the storage location, what information to include, optional compression, or splitting the dump. For your first experiments, it is advisable to start with the default settings.
For the kexec/kdump method to work, the crash kernel must already be loaded at the time of the problem. This process is handled by the kdump startup script, but only if a protected memory area is also present. To let the original kernel know this, you need to specify the boot loader option crashkernel=XM[ @YM] , where X is the size of the reserved area in megabytes and Y specifies the start address. If you omit the second parameter or set it to 0M , the system automatically selects an appropriate location. A subsequent restart enables this change.
Test Crash
If you are not convinced, you can check /proc/iomem to see that the protected memory space is marked (Listing 1).
Listing 1: Preparations for the Kernel Dump
[root@rhel ~]# grep -i crash /proc/iomem 03000000-0affffff : Crash kernel [root@rhel ~]# grep crash /proc/cmdline ro root=/dev/mapper/VolGroup00-LogVol00 rd_NO_LUKS KEYBOARDTYPE=pc \ KEYTABLE=de-latin1-nodeadkeys rd_NO_MD quiet SYSFONT=latarcyrheb-sun16 rhgb \ rd_LVM_LV=VolGroup00/LogVol01 rd_LVM_LV=VolGroup00/LogVol00 \ LANG=de_DE.UTF-8 rd_NO_DM crashkernel=128M [root@rhel ~]# /etc/init.d/kdump status Kdump is operational [root@rhel ~]# which kexec /sbin/kexec [root@rhel ~]# which kdump /sbin/kdump [root@rhel ~]# sles:~ # grep -i crash /proc/iomem 27000000-2effffff : Crash kernel sles:~ # grep crash /proc/cmdline root=/dev/disk/by-uuid/10a83ffe-5a9f-48a2-b8cb-551c2cc6b42d resume=/dev/sda3 \ splash=silent text showopts crashkernel=128 sles:~ # /etc/init.d/boot.kdump status kdump kernel loaded running sles:~ # which kexec /sbin/kexec sles:~ # which kdump /sbin/kdump sles:~ #
Then, if everything works correctly, the kdump startup script can load the crash kernel into memory. Typically, you want to add this step to the regular boot process, but for initial testing, a manual start is fine.
At this point, you need to test the configured setup – that is, you need to trigger a kernel crash artificially, which should then automatically start a dump write. To do so, use
echo 1 > /proc/sys/kernel/sysrq
to enable the “Magic SysRequest Keys.” Under normal circumstances, this has already happened if you used the distribution tools to set up the kernel dump.
Next, type
echo c > /proc/sysrq-trigger
to trigger a kernel panic. If everything works, the system starts the crash kernel, which in turn triggers kdump or makedumpfile (Figure 2).
 Figure 2: The crash kernel in action.
Figure 2: The crash kernel in action.
The system writes each dump to a separate directory named according to the creation date. If the system crashes multiple times, this prevents information you have already saved from being overwritten.
Another note for those using SUSE: You can also trigger a kernel panic by loading the crasher.ko module. Incidentally, this module comes courtesy of Btrfs developer Chris Mason, when he was still working for SUSE .
De Luxe
If the first dump attempts were successful, you can proceed with the fine tuning step. The first item on the agenda is reserving memory for the crash kernel. The generic statement is:
crashkernel=Range1:Size1[,Range2:Size2, ... ] [@address]
In the specific case of
crashkernel=512M-2G:64m,2G-:128M
this means: “For a RAM size of 512MB up to 2GB, the system reserves 64MB; this becomes 128MB if you have more than 2GB of RAM.” This step simplifies the configuration of the boot loader for a heterogeneous hardware environment. Regardless of RAM; the crashkernel entry is always the same. On SUSE, YaST does this automatically. The size and range information can also be stated in kilobytes according to the kernel documentation; however, that is not relevant in practical terms.
In the default configuration, the system saves the kernel dump on the local disk. For systems with a lot of memory, this behavior can quickly become a problem. Fortunately, the kexec/kdump combination also allows you to save on the network. You have a choice between NFS and SSH/SCP. Table 1 lists the available options.

Writing a dump via SSH/SCP presupposes a non-interactive authentication key. Thus, it’s a good idea to create a separate and restricted target user account.
Emergency Switch
The approach shown here for provoking a kernel dump will not work if the system stops responding and, for example, a login is impossible. One option is to trigger on a particular keyboard shortcut that is mapped to a SysRq key. In fact, you just need to press Alt+SysRq+C at the same time to trigger a kernel dump.
Again, the challenge is in the details. Many keyboards do not have a separate SysRq key, in which case the Print key assumes this function. However, the graphical user interface might intercept precisely this keyboard combination to create a screenshot. You can work around this by additionally pressing the Ctrl key.
Sometimes, you can trigger SysRq through a second assignment with the function (Fn) key. The list is almost infinite. Again, you need to test so that, in the event of an emergency, you will find the right buttons to press. Incidentally, the SysRequest keys can do much more than just trigger a kernel dump (see Table 2).

Sometimes the administrator has no physical access to the server keyboard, and you might not be able to pass keypresses on the local keyboard to the server, but normally, you can map certain key combinations to others.
Non-Maskable Interrupts
If the keyboard shortcut fails, you still have the option of using a non-maskable interrupt (NMI). You can start by configuring the Linux kernel so that it processes a panic routine when it receives an NMI and thus triggers the kernel dump. This procedure is easily done via the Sysctl interface.
The required parameter is kernel.unknown_nmi_panic and must be set to 1 (Listing 2).
Listing 2: Panic Routine for NMI Event
# cat /proc/sys/kernel/unknown_nmi_panic 1 # sysctl kernel.unknown_nmi_panic kernel.unknown_nmi_panic = 1 # grep nmi /etc/sysctl.conf kernel.unknown_nmi_panic = 1 #
Techniques for managing remote computers, such as iLO (integrated Lights-Out) by HP or DRAC (Dell Remote Access Controller) by Dell, let you manually trigger an NMI event, which then triggers a kernel dump. Note that other problems, for example, defective hardware or firmware, can also trigger an NMI. Such events will not necessarily prompt a system crash in normal operation and might just show up as a message in syslog (“Uhhuh. NMI received. Dazed and confused, but trying to continue”).
The above configuration changes this behavior, and the server always boots.
Easier Virtual Approach
Admins on virtualized Linux guests can relax. VMware, Xen, and KVM let you write a kernel dump without specially having to prepare the guest. The kernel dump contains information on the currently active RAM, that is, in the simplest case a 1:1 copy of the entire RAM.
The hypervisor systems I just mentioned can access the guest’s memory and let you write this to a file. In the case of Xen and KVM, the memory dump is compatible with the crash dump evaluation tools on Linux. The VMware memory dump needs to be processed – but more on that later. The native Linux hypervisor systems give administrators even more options. It is possible to create a dump on the fly.
Normally, Xen and KVM stop the guest while writing the dump and then let it continue to run. The commands for this are
xm dump-core <domain output file>
or
virsh dump <domain output file>
(Figure 3). If you add the --live option, Xen and KVM minimize the interruption. This avoids booting the crash kernel and also setting up the kexec/kdump configuration on the Linux guest.
 Figure 3: Kernel dump of a KVM guest on the fly.
Figure 3: Kernel dump of a KVM guest on the fly.
Converting VMware Images to Crash Dumps
VMware also can write memory dumps of its guests. The first method involves suspending and creates a vmss format file, but when you create a checkpoint as a VMware admin, you can write a memory dump, which then takes the form of a vmsn file. However, both variants require some post-processing before the default kernel debugging tools can handle them.
VMware provides the vmss2core command for this, but only with the workstation product in versions for Windows and Linux. ESX admins do not have this option.
Basically, vmss2core will also work outside of a full-fledged VMware workstation installation. Users who are prepared to experiment can simply copy the tool to a computer of their choice and convert the image there. The
vmss2core -N6 <file>.vmss
command generates the kernel dump (Listing 3). During testing, this conversion failed on both RHEL5 and RHEL6, but it worked as anticipated with SLES.
Listing 3: VMware Images to Kernel Dumps
# vmss2core -N6 rhel.vmss The vmss2core version 591240 Copyright (C) 1998-2012 VMware, Inc. All rights reserved. Started core writing. Writing note section header. Writing 1 memory section headers. Writing notes. ... 10 MBs written. ... 20 MBs written. ... ... 1020 MBs written. Finished writing core. # # ls vmss.core vmss.core #
Writing the kernel dump via the hypervisor has the advantage of not needing a kexec/kdump configuration on the guest. Additionally, the file is stored outside of the guest and does not occupy any local space. Thus, things look much easier.
However, there is one specific scenario that the hypervisor-only setup cannot cover: the kernel dump after a crash with an automated reboot. If you need this, there’s no way to work around a kexec/kdump configuration. The approach is exactly as described previously.
Conclusions
Generating a kernel dump is definitely not rocket science and can be done easily with a couple of actions. If your Linux systems are virtualized, the process is even easier. Thus, you have no excuse not to create a kernel dump for troubleshooting. Experienced users can even run the crash tool themselves to perform an initial evaluation.
The Author
Dr. Udo Seidel is a teacher of math and physics. After completing his Ph.D., he worked as a Linux/Unix trainer, system administrator, and senior solution engineer. He is now the leader of a Linux/Unix team at Amadeus Data Processing GmbH in Erding, Germany.
Related content
-
Creating and evaluating kernel crash dumps
 If the Linux server crashes, not only do you need to restore operations, you also need to analyze the problem. What happened? Where is the root of the error? What preventive measures are necessary? A kernel crash dump at the time of the crash can be a big help.
If the Linux server crashes, not only do you need to restore operations, you also need to analyze the problem. What happened? Where is the root of the error? What preventive measures are necessary? A kernel crash dump at the time of the crash can be a big help. - Red Hat Rolls out RHEL 6.5
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Focus On Self-Hosting
• Self-Hosted Collaboration with Forgejo
• Self-Hosted PaaS with Coolify
• Build and Host Docker Images
• Self-Hosted Pritunl VPN Server with MFA
• Self-Hosted Chat Servers
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
