
Lead Image © Lucy Baldwin, 123RF.com
Planning Performance Without Running Binaries
Blade Runner
Usually the task of a performance engineer involves running a workload, finding its first bottleneck with a profiling tool, eliminating it (or at least minimizing it), and then repeating this cycle – up until a desired performance level is attained. However, sometimes the question is posed from the reverse angle: Given existing code that requires a certain amount of time to execute (e.g., 10 minutes), what would it take to run it 10 times faster? Can it be done? Answering these questions is easier than you would think.
Parallel Processing
The typical parallel computing workload breaks down a problem in discrete chunks to be run simultaneously on different CPU cores. A classic example is approximating the value of pi. Many algorithms that numerically approximate pi are known, variously attributed to Euler, Ramanujan, Newton, and others. Their meaning, not their mathematical derivation, is of concern here. A simple approximation is given by Equation 1.
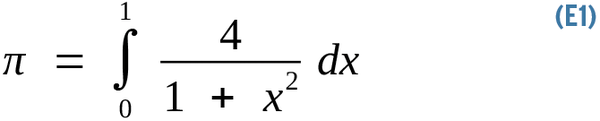
The assertion is that pi is equal to the area under the curve in Figure 1. Numerical integration solves this equation computationally, rather than analytically, by slicing this space into an infinite number of infinitesimal rectangles and summing their areas. This scenario is an ideal parallel numerical challenge, as computing one rectangle's area has no data dependency whatsoever with that of any another. The more the slices, the
...Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
Related content
-
Why Good Applications Don’t Scale

You ha ve parallelized your serial application , but as you use more cores you are n o t seeing any improvement in performance . What gives?
-
Why Good Applications Don't Scale
 You have parallelized your serial application, but as you use more cores you are not seeing any improvement in performance. What gives?
You have parallelized your serial application, but as you use more cores you are not seeing any improvement in performance. What gives? -
Embarrassingly parallel computation
 Determine pi by throwing darts.
Determine pi by throwing darts. -
Failure to Scale

Your parallel application is running fine, but you want it to run faster. Naturally, you use more and more cores, and everything is great; however, suddenly performance starts decreasing. What just happened?
-
Improved Performance with Parallel I/O

Understanding the I/O pattern of your application is the starting point for improving its I/O performance, especially if I/O is a fairly large part of your application’s run time.
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
