« Previous 1 2 3
Application-aware batch scheduler
Eruption
Training a PyTorch Model
The second example of a resource-intensive job comes from PyTorch, which is a Python machine learning library that (among many other capabilities) simplifies the training of ML models on CPU or GPU hosts. The Kubeflow Kubernetes machine learning platform offers a particular feature called the Kubeflow Training Operator [5] with an accompanying PyTorchJob custom resource that is designed to train models on behalf of PyTorch programs, with the use of the resources of a Kubernetes cluster. This use case is well suited to a team of data scientists who want to run Python code on their local machines but use a shared group of GPU resources to train their models as fast as possible.
PyTorch spreads training across multiple hosts (and therefore GPUs) with its DistributedDataParallel (DDP) module. When run with the Kubeflow Training Operator, it necessarily translates to multiple pods running simultaneously. The Kubeflow Training Operator is designed to work with Volcano to provide gang-scheduling so that if the cluster doesn't have sufficient resources to set up all of the training job's resources, then none will be scheduled at all, and the PodGroup will remain in the Queue until such a time as the resources do become available.
Running in its default state, without Volcano, multiple PyTorchJobs can each take up all available cluster GPUs without any one of them having enough to train their model properly, leading to another deadlock situation. In this example, the test cluster is recreated with the gpupool section of the doc8s.tf OpenTofu module ([1], section 1) uncommented.
To create six PyTorchJobs simultaneously with Python threads, install the Kubeflow Training Operator [5] and run the mnist-gpu.py script from section 4 of the GitHub repo [1], which is a slightly modified version of the example given in the Kubeflow Training Operator documentation:
kubectl apply -k "github.com/kubeflow/training-operator.git/manifests/overlays/standalone?ref=master" python mnist-gpu.py
As Figure 7 and Figure 8 show, you hit a deadlock situation with GPU hosts tied up by different partially created jobs.
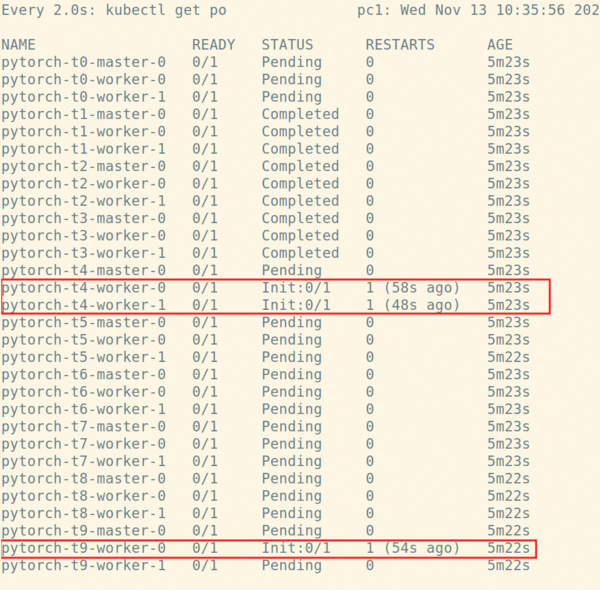 Figure 7: The first few jobs completed successfully, but because of no coordination at the job level, pods with GPU resources soon become split between partially deployed jobs and hang indefinitely.
Figure 7: The first few jobs completed successfully, but because of no coordination at the job level, pods with GPU resources soon become split between partially deployed jobs and hang indefinitely.
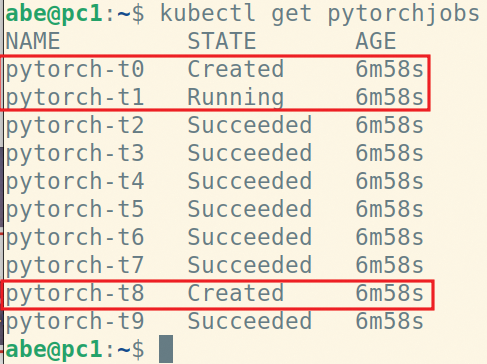 Figure 8: The PyTorchJobs corresponding to the pods in Figure 7 are stuck in this state.
Figure 8: The PyTorchJobs corresponding to the pods in Figure 7 are stuck in this state.
To leverage Volcano in the Kubeflow Training Operator [6], edit the training-operator deployment to set the gang-scheduler command-line option (Listing 2).
Listing 2
Edited training-operator
kubectl -n kubeflow edit deploy training-operator
spec:
containers:
-- command:
-- /manager
+ -- --gang-scheduler-name=volcano
image: kubeflow/training-operator
name: training-operator
After retrying the training example, you can see that the PyTorchJobs are created one after the other so that each one can consume the GPU resources it needs (Figure 9).
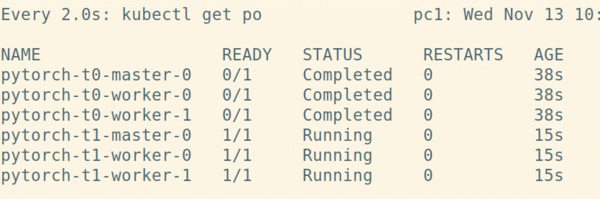 Figure 9: Even though the jobs pytorch-t0 through pytorch-t5 have all been submitted to the cluster, Volcano doesn't even begin to create the pods for a particular job until it can be sure sufficient GPU hosts are available.
Figure 9: Even though the jobs pytorch-t0 through pytorch-t5 have all been submitted to the cluster, Volcano doesn't even begin to create the pods for a particular job until it can be sure sufficient GPU hosts are available.
Conclusion
Shared compute resources are expensive, whether they are private or in the public cloud, and nobody wants their jobs to be delayed indefinitely because of deadlock caused by scheduling limitations. In this article, I described how Volcano schedules PodGroups and demonstrated how easily it can be used by common open source AI/ML frameworks to get the most out of Kubernetes worker hosts.
Infos
- Examples in this article: https://github.com/datadoc24/admin-volcano-article/tree/main
- War and Peace from Project Gutenberg: https://www.gutenberg.org/ebooks/2600
- Apache Spark on Kubernetes: https://spark.apache.org/docs/latest/running-on-kubernetes.html#using-volcano-as-customized-scheduler-for-spark-on-kubernetes
- Volcano scheduler: https://volcano.sh/en/docs/
- Kubeflow Training Operator: https://www.kubeflow.org/docs/components/training/getting-started/
- Enabling Volcano gang scheduling for Kubeflow Training Operator: https://www.kubeflow.org/docs/components/training/user-guides/job-scheduling/#running-jobs-with-gang-scheduling
The Author

Abe Sharp is a Distinguished Technologist at Hewlett Packard Enterprise, where he works on containerized AI and MLOps platforms in the Ezmeral business unit.
« Previous 1 2 3
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
Kick-start your AI projects with Kubeflow
 Training language models and AI algorithms requires a powerful infrastructure that is difficult to create manually. Although Kubeflow promises a remedy, it is itself a complex monster … unless you are familiar with the right approach that lets you get it up and running fairly quickly.
Training language models and AI algorithms requires a powerful infrastructure that is difficult to create manually. Although Kubeflow promises a remedy, it is itself a complex monster … unless you are familiar with the right approach that lets you get it up and running fairly quickly. -
Persistent storage management for Kubernetes
 The container storage interface (CSI) allows CSI-compliant plugins to connect their systems to Kubernetes and other orchestrated container environments for persistent data storage.
The container storage interface (CSI) allows CSI-compliant plugins to connect their systems to Kubernetes and other orchestrated container environments for persistent data storage. -
An open source object storage solution
 We introduce the MinIO high-performance object store, its key features and applications, and some performance tips.
We introduce the MinIO high-performance object store, its key features and applications, and some performance tips. -
Kubernetes containers, fleet management, and applications
 Kubernetes is all the rage, but many admins find themselves struggling to get started. We present the basic architecture and the most important components and terms.
Kubernetes is all the rage, but many admins find themselves struggling to get started. We present the basic architecture and the most important components and terms. -
Nested Kubernetes with Loft
 Kubernetes has limited support for multitenancy, so many admins prefer to build multiple standalone Kubernetes clusters that eat up resources and complicate management. As a solution, Loft launches any number of clusters within the same control plane.
Kubernetes has limited support for multitenancy, so many admins prefer to build multiple standalone Kubernetes clusters that eat up resources and complicate management. As a solution, Loft launches any number of clusters within the same control plane.
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
