Getting the Most from Your Cores

CPU utilization metrics tell you how well your applications are using your processing resources.
In a general sense, high-performance computing means getting the most out of your resources. This translates to utilizing the CPUs (cores) as much as possible. Consequently, CPU utilization becomes a very important metric to determine how well an application is using the cores. On today’s systems with multiple cores per socket and various cache levels that may or may not be shared across cores, determining CPU utilization might not be easy or simple to determine.
To explain this, a definition of CPU utilization is needed. As a starting point, I’ll use the definition from Technopedia, which states:
CPU utilization refers to a computer’s usage of processing resources, or the amount of work handled by a CPU. Actual CPU utilization varies depending on the amount and type of managed computing tasks. Certain tasks require heavy CPU time, while others require less because of non-CPU resource requirements.
The definition goes on to state:
CPU utilization should not be confused with CPU load.
This is a very important point in the quest for measuring CPU utilization of HPC applications – don’t confuse CPU load and CPU utilization.
In the days of single-core CPUs, CPU utilization was fairly straightforward. If a processor was operating at a fixed frequency of 2.0GHz, CPU utilization was the percentage of time the processor spent doing work. (Not doing work is idle.) For 50% utilization, the processor performed about 1 billion cycles worth of work in one second. Current processors have multiple cores, hardware multithreading, shared caches, and even dynamically changing frequencies. Moreover, the exact details of these components varies from processor to processor, making CPU utilization comparison difficult.
Current processors can have shared L3 caches across all cores or shared L2 and L1 caches across cores. Sometimes these resources are shared in interesting ways. The example in Figure 1 is the Xeon E5 v2 to Xeon E5 v3 processors (courtesy of EnterpriseTech).
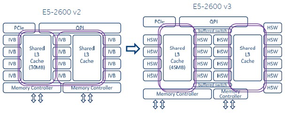
Figure 1: Xeon E5v2 to Xeon E5v3 architectures.
Notice how the specific CPU architecture changes, moving from the Ivy Bridge (Xeon E5 v2) generation to the Haswell (Xeon E5 v3) generation and how the resources are shared differently in the two architectures.
Equally as important is how the various applications or “bits of work” are distributed. As a result, when resources are shared, the net effect on performance becomes dependent on workload.
Illustrating this point is fairly simple. If an application benefits from a larger cache and the cache space is shared, the performance can suffer because of cache misses. Memory access performance is also an important aspect of application performance (getting/putting data into either caches or main memory). The reported CPU utilization times include the time spent waiting for cache or memory access. This time can be larger or smaller based on the amount and the kind of resource sharing that is going on in the CPU.
Symmetric Multithreading (SMT), as in Intel’s Hyper-Threading technology, have logical cores that are the same as physical cores and may have execution units shared between them. These processors also have non-uniform memory access (NUMA) characteristics, so the placement of processes, including pinning them to certain cores, can have an effect on CPU utilization.
Also affecting CPU utilization is the frequency of the cores (logical units) doing work. Many processors have the ability to turn up their frequency if neighboring cores are idle or doing very little work. The goal is to keep the temperature of the collective processors below a threshold. This means that the frequency of the various cores can vary while an application is running, which also affects CPU utilization and, more importantly, how the frequency or work capability of the processor is computed.
Yet another event with an effect on CPU utilization is virtualization. Virtualization can introduce more complexity into the problem of CPU utilization because allocation of work to the various cores is performed by the hypervisor rather than the guest OS, so the performance counters used for measuring CPU utilization should be hypervisor-aware.
All of these factors interact so that measuring CPU utilization is not as easy as it might seem. Furthermore, trying to translate CPU utilization from one CPU architecture to another can result in very different results. Understanding the CPU architectures and how CPU utilization is measured are keys for making the transition.
CPU Utilization or CPU Load?
As mentioned in the first section of the article, “CPU utilization should not be confused with CPU load.” This is a very critical distinction that will prevent confusion.
In Linux (and *nix computing in general), system load is a measure of work that the system performs. The classic uptime (or w) command lists three load averages for 1-minute, 5-minute, and 15-minute time periods. When the system is idle, the load number is zero. For each process that is using or waiting for the CPU, the load is incremented by one. Typically, this includes the effect of processes blocked in I/O, because busy or stalled I/O systems are increasing the load average even though the CPU is not being used. Moreover, the load is computed as an exponentially damped/weighted moving average of the load number. Note that the average is computed.
As a result, using load to measure CPU utilization has drawbacks, because processes blocked in I/O mask the true load and the use of a computed load average skews the results. The moral is that if accurate CPU utilization measurements are needed, don’t use load measurements.
psutil
You can find a number of articles around the Internet about CPU utilization on Linux machines. Many of them use uptime or w, which aren’t the best ways to determine CPU utilization, particularly if testing an HPC application that uses a majority of the cores.
For this article, I use the psutil, which is a cross-platform library for gathering information on running processes and system utilization. It currently supports Linux, Windows, OS X, FreeBSD, and Solaris; has a very easy-to-use set of functions; and can be used to write all sorts of useful tools. For example, the author of psutil wrote a top-like tool in a couple of hundred lines of Python.
The pustil documentation discusses several functions for gathering CPU stats, particularly CPU times and percentages. Moreover, these statistics can be gathered with user-controllable intervals and for either the entire system (all cores) or every core individually. Thus, psutil is a great tool for gathering CPU utilization stats.
As an example of what can be done with psutil for gathering CPU utilization statistics, a simple Python program was written that gathers CPU stats and plots them using Matplotlib (Listing 1). The program is just an example of gathering CPU statistics with some values hard-coded in.
Listing 1: Collect and Plot CPU Stats
#!/usr/bin/python
import time
try:
import psutil
except ImportError:
print "Cannot import psutil module - this is needed for this application.";
print "Exiting..."
sys.exit();
# end if
try:
import matplotlib.pyplot as plt; # Needed for plots
except:
print "Cannot import matplotlib module - this is needed for this application.";
print "Exiting..."
sys.exit();
# end if
def column(matrix, i):
return [row[i] for row in matrix]
# end def
# ===================
# Main Python section
# ===================
#
if __name__ == '__main__':
# Main dictionary
d = {};
# define interval and add to dictionary
interv = 0.5;
d['interval'] = interv;
# Number of cores:
N = psutil.cpu_count();
d['NCPUS'] = N;
cpu_percent = [];
epoch_list = [];
for x in range(140): # hard coded as an example
cpu_percent_local = [];
epoch_list.append(time.time());
cpu_percent_local=psutil.cpu_percent(interval=interv,percpu=True);
cpu_percent.append(cpu_percent_local);
# end for
# Normalize epoch to beginning
epoch_list[:] = [x - epoch_list[0] for x in epoch_list];
# Plots
for i in range(N):
A = column(cpu_percent, i);
plt.plot(epoch_list, A);
# end if
plt.xlabel('Time (seconds)');
plt.ylabel('CPU Percentage');
plt.show();
# end ifExample
The point of the code is not to create another tool but to implement it when running example programs to illustrate how CPU utilization stats can be gathered. The programs used in this example are the NAS Parallel Benchmarks (NPB). Version 3.3.1 using OpenMP was used for the example. Only the FT test (discrete 3D fast Fourier transform, all-to-all communication) was run and the Class B “size” standard test (4x size increase going from one class to the next) was used on a laptop with 8GB of memory using two cores (OMP_NUM_THREADS=2).
Initial tests showed that the application finished in a bit less than 60 seconds. With an interval of 0.5 seconds between statistics, 140 function calls gathered the statistics (this is hard-coded in the example code).
To better visualize the CPU utilization statistics, a “pause” is used at the beginning so that CPU utilization is captured on a relatively quiet system. Also, the application finishes a little faster than 60 seconds, so the CPU utilization stats capture the system “quieting down” after the run.
One important thing to note is that the application was run on a system that was running X windows and a few other applications and daemons; therefore, the system was not completely quiet (i.e., 0% CPU utilization) when the application was not running.
Figure 2 is the plot of CPU utilization versus time in seconds (relative to the beginning of gathering the statistics).
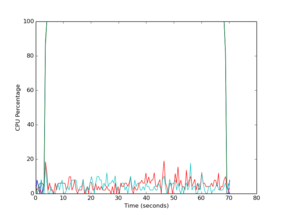
Figure 2: CPU utilization while running NPB FT Class B with two cores.
This plot doesn’t have a legend, so it might be difficult to see the CPU utilization of all four cores. However, at the bottom of the plot are two lines representing CPU utilization of two of the four cores. For these two cores, CPU utilization while the NPB FT Class B application is running is quite low (<20%). However, for the other two cores, the CPU utilization quickly goes to 100% and stays there most of the time the statistics were gathered, although in this graph, it only looks like one line.
For this particular example, the application was not “pinned” to any cores, which means the processes were not tied to a specific core in the processor and were not moved by the kernel. If processes are not pinned to a core, it is possible for the kernel to move them between cores. In that case, the CPU utilization plots would show a specific core at a high percentage that then drops low, while the CPU utilization on a different core rises dramatically.
For this example, the kernel did not move any processes, most likely because two cores are available for running daemons or any other process that needs CPU cycles. If the application had been run with four threads, the plot would have been more chaotic because the kernel would have had to move or pause processes to accommodate daemons or other processes when they started.
Conclusion
CPU utilization charts can be very useful because they visually indicate how heavily a core is utilized. If the utilization is fairly high (close to 100%) but then drops low for a noticeable period of time, something is causing the core to become idle. The reasons for CPU utilization to drop could be from waiting on I/O (reads or writes) or because of network traffic from one node to another (possibly MPI communication).
In a general sense, CPU utilization provides an idea of how well an application is performing and if it is using the cores as it should. Remember, the first two letters in HPC stand for “High Performance.”
Tags:
![]() application performance ,
application performance , ![]() utilization
utilization