Remora – Resource Monitoring for Users

Remora provides per-node and per-job resource utilization data that can be used to understand how an application performs on the system through a combination of profiling and system monitoring.
While chatting with some colleagues, we discussed how some applications return unusual results, even though previous runs had produced the expected results. As they were discussing ways to tell whether applications were running correctly or incorrectly, I thought it would be great to get a snapshot of what was happening on all of the nodes involved in the job. I like to think of this as “application telemetry.”
A simple search on “telemetry” brings up a definition like, “… the process of recording and transmitting the readings of an instrument.” In this case, the instrument is the high-performance computing (HPC) system, and the readings are resource aspects of the system (e.g., CPU, memory, network, and storage usage, etc.). Here, the telemetry is used to help the user understand what their application was doing during execution. The key word in that last sentence is user. The case in point: The user has access to resource usage for their application to spot problems, prompting me to revisit Remora.
REMORA: REsource MOnitoring for Remote Applications, from the University of Texas Advanced Computing Center (TACC), combines monitoring and profiling to provide information about your application. Not strictly a profiler and not strictly a monitoring tool in the traditional sense of monitoring the entire cluster, Remora provides per-node and per-job resource utilization data that can be used to understand how an application performs on the system. The user (not just the admin) can go back and examine what was happening on systems while a job was running.
The goal of Remora is simplicity, which is achieved by using commonly installed tools that focus on the user, putting data and possibly information in the user’s hands (and probably the admin’s if an issue crops up). The data can also be used by admins in a collective way to understand how the system is being used.
Overview
Before diving into the ins and outs of Remora, keep in mind two things: (1) It is focused on the user, and (2) it is neither a profiling tool nor a monitoring tool. In essence, Remora is more of a higher level usage reporting tool that tells what resources your job used along with some associated details. It does not dive deep – that's more the function of a profiler – and it doesn’t produce fine-grained system monitoring details; rather, it focuses on information that the user can use to understand whether a job seems to perform correctly and, if not, information that can start the “debugging” process. System admins have access to the same information, so they too can examine the job if the user feels something went wrong.
Remora collects several streams of information with simple userspace tools:
- Memory usage, including CPUs, Xeon Phi, and Nvidia GPUs
- CPU utilization
- I/O usage – Lustre, data virtualization service (DVS)
- Nonuniform memory access (NUMA) properties
- Network topology
- Message passing interface (MPI) communication statistics (currently you have to use Intel MPI or MVAPICH2)
- Power consumption
- CPU temperatures
- Detailed application timing
To capture all this information, Remora uses SSH to connect to all the nodes used in the application by spawning a background task on each of the nodes and regularly capturing the data. However, I/O data is only captured on the master node of the application.
No Remora-specific applications are used to gather the information. Rather, existing applications are used along with information parsed from the /proc/ table. A partial list of the tools and data sources used are:
- numastat
- mpstat (one of my personal favorites)
- nvidia-smi
- ibtracert
- ibstatus
- xltop
- mpip
- python
- /proc/meminfo
- /proc/[pid]/status
- /proc/sys/lnet/stats
- /sys/class/infiniband …
Remora uses these tools and sources to collect information at a specific interval while the application runs. Because Remora runs in user space, it only collects information associated with the application and can’t gather escalated privileged information. In the case of MPI applications, it grabs the hostnode list of environment variables and uses that for SSHing into the nodes for data gathering.
As of version 1.8.4, Remora requires either Intel MPI or MVAPICH2. The profiling library mpiP, is used in conjunction with one of these two MPI libraries to gather MPI profile stats.
When Remora is finished, it creates a directory in the form remora_XXX in the directory in which the application runs. Subdirectories contain the raw data, and you’ll find an HTML page you can open to examine and plot the data (this is REALLY amazing!).
Remora collects data from as many of the sources possible. For example, if it detects that Lustre is installed, it will grab data for that. If it detects the presence of an InfiniBand network, it will collect data for that. If it doesn't detect something, it won’t try to gather data for it, and you won’t be able to create a chart for the data.
The sources for which it attempts to gather information is controlled by a configuration file. On my test system the path to the file is /home/<user>/bin/remora-1.8.4/bin/config/modules. You can edit that file to remove resources you do not want gathered. When installed, that file contains all the sources of information. In the default list below, each line comprises the name of the module and the directory in which the metric belongs.
cpu,CPU memory,MEMORY numa,NUMA dvs,IO lustre,IO lnet,IO ib,NETWORK gpu,MEMORY network,NETWORK power,POWER temperature,TEMPERATURE eth,NETWORK
For example, if you do not have an InfiniBand network, you remove it from the list and Remora won't attempt to gather that information.
For this article, my config file is:
cpu,CPU memory,MEMORY eth,NETWORK
Installing Remora
Installation is not difficult. The approach is slightly different from the usual ./configure; make; make install, and you need to be aware that because Remora can provide MPI statistics, you need to build it with the intended version of MPI (i.e., do not cross the MPIs). Of course, you don't have to use MPI tools, and Remora will just continue with the configuration and installation.
For this article, I built Remora into my home account with the command:
REMORA_INSTALL_PREFIX=/home/laytonjb/bin/remora-1.8.4 ./install.sh
You can install it in a common directory if all users are to have access. (Note that a previous article on Remora originally had a typo (now corrected) in the installation command, in which the letter P was missing in PREFIX.)
If you use multiple versions of MPI, you need to build Remora for each version. If you are using environment modules (e.g., Lmod), you can easily write an environment module for Remora so that it is added to the user environment when the corresponding MPI module is loaded.
Example 1
Remora is very, very simple to use: Just add remora before your usual command. For example, a simple command line for the application ./myapp.exe would become:
$ remora ./myapp.exe
In the case of MPI code, the command mpirun [...] ./mpiapp.exe
would become:
$ remora mpirun [...] ./mpiapp.exe
Notice that both commands are run as a user – elevated or root privileges are not required, which goes back to Remora’s design of focusing on and providing users with useful information.
The code in this article is for a simple serial Poisson solver for a rectangular grid. Although I used it in the past, the link to it no longer works. If you really want something equivalent, then use the OpenMP version of the code and just set OMP_NUM_THREADS to 1. You won't get the exact same timings as the old serial code, but it is probably a reasonable substitute.
To get a fairly long run time, I adjusted a few of the application parameters
nx = 8000 ny = 8000 t_max = 10000 tolerance = 0.00004D+00
and compiled the code with GFortran on a CentOS 7.8 system.
Remora first creates a subdirectory that contains the system information as a function of time. For this particular test, that subdirectory is remora_1605743629. This directory then has several subdirectories with the raw data. You can parse through the data, or Remora creates a web page (HTML) that plots the data for you, which is the easiest way to get a quick glimpse of what happened during application execution. Just open the web page in your favorite browser (Figure 1).

Figure 1: The web page showing the Remora output for the Example 1 code.
The HTML summary page lists the system metrics that Remora is capable of monitoring. A link below the metric means the corresponding data is available. Notice that for this simple case, only some of the metrics have been monitored.
The images are created by Google Charts. To include them in this article, they have been screen captured. Figure 2 is a plot of CPU usage versus time for Example 1, which is a serial application, so only one core was used. Notice how the kernel moves the application from one core to another. Remora itself uses little CPU time.
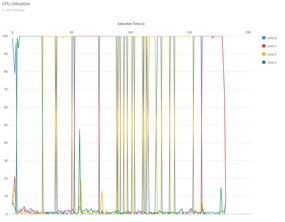
Figure 2: Example 1 CPU utilization plot.
The second plot of memory usage during the application run is shown in Figure 3. These memory metrics are gathered from /proc/<pid>/status and /dev/shm.
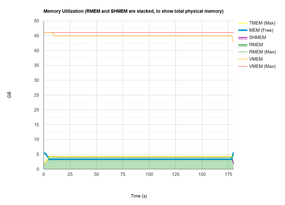
Figure 3: Example 1 memory utilization plot.
The memory stats include:
- TMEM (Max): Total free memory. Considers the memory not being used by the application, the libraries needed by the application, and the OS.
- SHMEM: Shared memory (/dev/shm). Applications have access to shared memory by means of /dev/shm. Any file put there counts toward the memory used by the application.
- RMEM: Resident memory. Physical memory used by the application.
- RMEM (Max): Maximum resident memory.
- VMEM: Virtual memory. This information is important for watching to see if the OOM killer kicks in.
- VMEM (Max): Maximum virtual memory.
Finally, Figure 4 is a plot of Ethernet usage during the run.
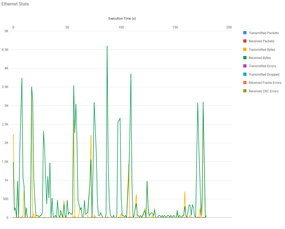
Figure 4: Example 1 Ethernet utilization plot.
Remora uses SSH to gather stats because the application can use MPI; otherwise, the usage is just regular network traffic.
A few environment variables can be used with Remora to control its behavior:
- REMORA_PERIOD: How often statistics are collected. The default is 10 seconds. Integer values are acceptable.
- REMORA_VERBOSE: If set to 1, this variable tells Remora to send all information to a file. The default is 0 (off).
- REMORA_MODE: Which stats are collected. Possible values include:
- FULL (default): CPU, memory, network, Lustre.
- BASIC: CPU, memory.
- REMORA_PLOT_RESULTS: Controls whether the results are plotted:
- 1 (default): generates HTML files.
- 0: generates plots only if the postprocessing tool (remora_post) is involved.
- REMORA_CUDA: If set to 0, turns off GPU memory collection when a GPU module is available on the system.
You can set these variables as you like or need. Setting REMORA_PERIOD to 1 second could produce a fair amount of data if the application runs over a long period. A period that is too short could also affect application performance.
REMORA_VERBOSE is a good flag to set if you want to learn more about the code and understand how it measures resource usage. Of course, its obvious use is for when you are having issues with Remora.
I never use REMORA_MODE because I can control what I want measured by changing the module config file, as previously mentioned. The same is true for REMORA_PLOT_RESULTS, because I always want to see the plots.
Example 2
Example 2 is basically the same as Example 1, but it uses the OpenMP version of the Poisson solver. In this case, all of the cores in the system are used.
Notice in Figure 5 that the application execution time with OpenMP is much shorter when using four cores than when using one core. Figure 6 shows CPU usage versus time for Example 2. Remember, this is an OpenMP application running on all cores, which is reflected by 96%-100% core utilization during the entire run.

Figure 5: The web page showing the Remora output for Example 2.
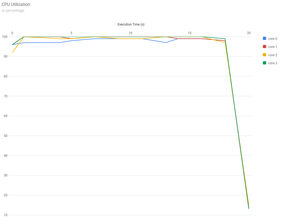
Figure 6: Example 2 CPU utilization plot.
Figure 7 shows the plot of memory usage and Figure 8 a plot of Ethernet during the application run.
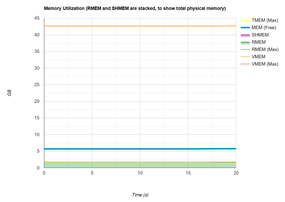
Figure 7: Example 2 memory utilization plot.
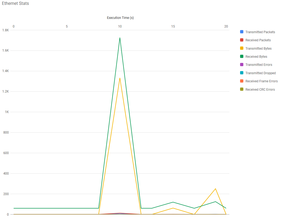
Figure 8: Example 2 Ethernet utilization plot.
Summary
HPC admins are always looking for better ways to monitor the systems for which they are responsible by understanding how the hardware is operating and seeing how user applications are performing. Many tools and techniques – both hardware and software – are available to coordinate monitoring with resource managers (job schedulers), all of which are administrator-oriented tools.
Users have precious few tools to monitor the resources their applications are using. With “application telemetry” information, users can understand the pattern of their application, whether it seems to be performing correctly or incorrectly, what resources it consumed, and how their application is balanced across several nodes in the system – or even a single node.
Remora from TACC can gather this information for you and create plots to help guide you to a better understanding of your application without affecting its performance. Typically, the system administrator installs Remora, but users can install it in their accounts, as well.
Tuning the Remora installation is possible, particularly around what is monitored. Once installed, you just put the command remora before the command that runs the application, and you start gathering information. A few environment variables adjust how Remora gathers the data, but for the most part, it just silently gathers the data for you.
Remora is a great tool for users who want an idea of their application resource usage. Not pure profiling, Remora is really a combination of profiling and system monitoring. Remora is easy to install and fairly light on resource usage and can be a great help to users.