
Lead Image © Joe Belanger, 123RF.com
Best practices for KVM on NUMA servers
Tuneup
Non-uniform memory access (NUMA) [1] systems have existed for a long time. Makers of supercomputers could not increase the number of CPUs without creating a bottleneck on the bus connecting the processors to the memory (Figure 1). To solve this issue, they changed the traditional monolithic memory approach of symmetric multiprocessing (SMP) servers and spread the memory among the processors to create the NUMA architecture (Figure 2).
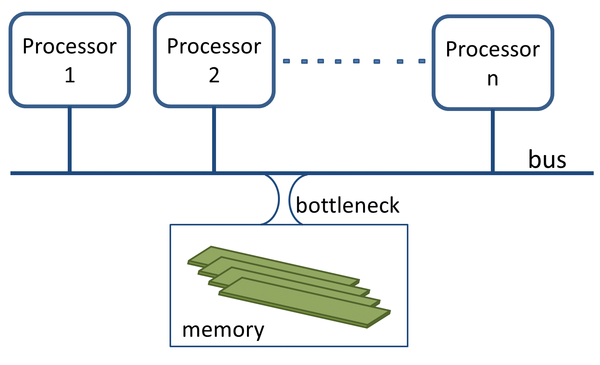 Figure 1: Traditional SMP architecture.
Figure 1: Traditional SMP architecture.
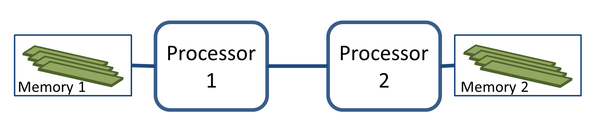 Figure 2: NUMA architecture.
Figure 2: NUMA architecture.
The NUMA approach has both good and bad effects. A significant improvement is that it allows more processors with a corresponding increase of performance; when the number of CPUs doubles, performance is
...
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
Related content
-
Getting your virtual machine dimensions right
 Massive, performance-hungry VMs require proper handling to meet their dynamic requirements. We give you some rules to help size these monsters properly.
Massive, performance-hungry VMs require proper handling to meet their dynamic requirements. We give you some rules to help size these monsters properly. -
Virsh Libvert Tool
With the command-line tool virsh, a part of the libvirt library, you can query virtual machines to discover their state of health, launch or shut down virtual machines, and perform other tasks – all of which can be conveniently scripted.
-
Remotely controllingvirtual machines with virsh
 With the command-line tool virsh, a part of the libvirt library, you can query virtual machines to discover their state of health, launch or shut down virtual machines, and perform other tasks – all of which can be conveniently scripted.
With the command-line tool virsh, a part of the libvirt library, you can query virtual machines to discover their state of health, launch or shut down virtual machines, and perform other tasks – all of which can be conveniently scripted. -
CPU affinity in OpenMP and MPI applications
 Get better performance from your nodes by binding processes and associating memory to specific cores.
Get better performance from your nodes by binding processes and associating memory to specific cores. -
Processor and Memory Affinity Tools

Get better performance from your nodes by binding processes and associating memory to specific cores .
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Focus On Self-Hosting
• Self-Hosted Collaboration with Forgejo
• Self-Hosted PaaS with Coolify
• Build and Host Docker Images
• Self-Hosted Pritunl VPN Server with MFA
• Self-Hosted Chat Servers
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
