
Lead Image © Kheng Ho Toh, 123RF.com
Distributed MySQL with Vitess
Ubiquitous
Whereas IT organizations in the past maintained individual setups with separate infrastructures, scalable platforms today almost inevitably set the tone. Because customers take it for granted that their providers will continually reduce the cost of IT infrastructure and its operation, today IT can only be operated efficiently if it relies on sheer mass.
In the past, admins might have had a few dozen systems in their care; however, today they are more likely to have hundreds of machines or even more. Of course, this also affects the applications that run on these platforms: They need to be able to grow along with the environments. Several examples do this impressively, including Ceph, which offers storage that grows with the usage scenario, or applications that adhere to a cloud-ready design and can internally scale seamlessly at every level.
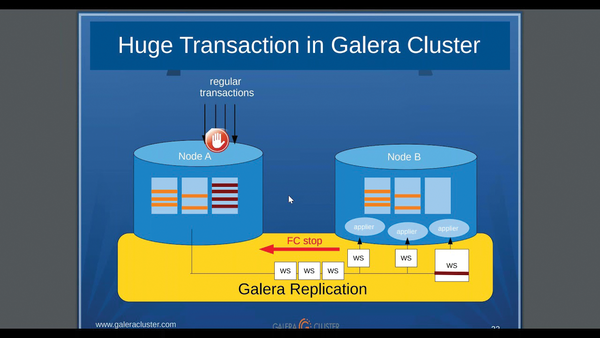
The trend toward scaling does not stop at databases either. You might think this topic no longer needs further consideration. After all, you have Galera for MySQL and a cornucopia of solutions for PostgreSQL that retrofit scalability. Unfortunately, it's not that simple. Galera (Figure 1) has a fan base, but comes with architectural weaknesses that often make its use impossible. PostgreSQL is nowhere near as popular as MariaDB or MySQL; it is used in far fewer setups and is considered more complicated and cumbersome. Not to mention that quite a few of the replication solutions for PostgreSQL are also plagued with critical design flaws.
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
Sharding and scale-out for databases
 Apache ShardingSphere extends databases like MySQL or PostgreSQL, adding a modular abstraction layer to support horizontal sharding and scalability – but not replication or encryption at rest.
Apache ShardingSphere extends databases like MySQL or PostgreSQL, adding a modular abstraction layer to support horizontal sharding and scalability – but not replication or encryption at rest. -
Key-value stores: an alternative to relational databases
 Relational databases have been long-lived, but a completely different type of database, the key-value store, has established itself in the cloud market.
Relational databases have been long-lived, but a completely different type of database, the key-value store, has established itself in the cloud market. -
MySQL is gearing up with its own high-availability Group Replication solution
 Oracle recently introduced Group Replication as a trouble-free high-availability solution for the ubiquitous MySQL.
Oracle recently introduced Group Replication as a trouble-free high-availability solution for the ubiquitous MySQL. -
MariaDB MaxScale: A smart proxy for MySQL
 MaxScale by MariaDB is a smart proxy server for MySQL that speaks the same protocol as the database server. The manufacturer claims solid high availability and horizontal scalability.
MaxScale by MariaDB is a smart proxy server for MySQL that speaks the same protocol as the database server. The manufacturer claims solid high availability and horizontal scalability. -
Exploring OpenStack's Trove DBaaS
 DBaaS moves the database service to the cloud, promising a new database instance at the click of a mouse.
DBaaS moves the database service to the cloud, promising a new database instance at the click of a mouse.
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
