
Parallelizing and memorizing Python programs with Joblib
A Library for Many Jobs
In recent years, new programming concepts have enriched the computer world. Instead of increasing processor speed, the number of processors have grown in many data centers. Parallel processing supports the handling of large amounts of data but also often requires a delicate transition from traditional, sequential procedures to specially adapted methods. The Joblib Python library [1] saves much error-prone programming in typical procedures such as caching and parallelization.
A number of complex tasks come to mind when you think about parallel processing. The use of large data sets, wherein each entry is independent of the other, is an excellent choice for simultaneous processing by many CPUs (Figure 1). Tasks like this are referred to as "embarrassingly" parallel. Where exactly the term comes from is unclear, but it does suggest that converting an algorithm to a parallelized version should not take long.
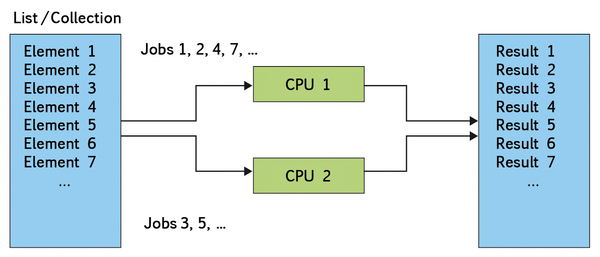 Figure 1: Problems involving input objects that can be independently and concurrently processed are referred to as "embarrassingly" parallel.
Figure 1: Problems involving input objects that can be independently and concurrently processed are referred to as "embarrassingly" parallel.
Experienced developers know, however, that problems can occur in everyday programming practice
...
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
Related content
-
Parallel Python with Joblib

The Joblib Python Library handles frequent problems – like parallelization, memorization, and saving and loading objects – in almost no time, giving programmers more freedom to push on with their core tasks.
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Focus On Self-Hosting
• Self-Hosted Collaboration with Forgejo
• Self-Hosted PaaS with Coolify
• Build and Host Docker Images
• Self-Hosted Pritunl VPN Server with MFA
• Self-Hosted Chat Servers
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
