
Lead Image © 3dkombinat, 123RF.com
Monitor and optimize Fibre Channel SAN performance
Tune Up
In the past, spinning hard disks were often a potential bottleneck for fast data processing, but in the age of hybrid and all-flash storage systems, the bottlenecks are shifting to other locations on the storage area network (SAN). I talk about where it makes sense to influence the data stream and how possible bottlenecks can be detected at an early stage. To this end, I will be determining the critically important performance parameters within a Fibre Channel SAN and showing optimization approaches.
The Fibre Channel (FC) protocol is connectionless and transports data packets in buffer-to-buffer (B2B) mode. Two endpoints, such as a host bus adapter (HBA) and a switch port, negotiate a number of FC frames, which are added to the input buffer as buffer credits at the other end, allowing the sender to transmit a certain number of frames to the receiver on a network without having to wait for each individual data packet to be confirmed (Figure 1).
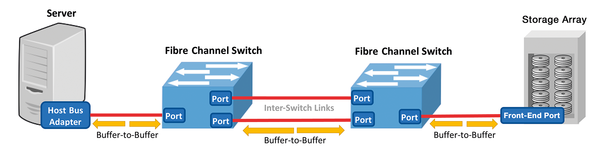 Figure 1: The Fibre Channel frames are transferred by the SAN from the sender (server) to the receiver (storage array) over the FC switch ports by the connectionless buffer-to-buffer method.
Figure 1: The Fibre Channel frames are transferred by the SAN from the sender (server) to the receiver (storage array) over the FC switch ports by the connectionless buffer-to-buffer method.
For each data packet sent, the buffer
...
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
Related content
-
A buyer's guide to NVMe-based storage
 An all-flash NVMe-based data storage solution can contribute to a lean, powerful, and future-proof data center.
An all-flash NVMe-based data storage solution can contribute to a lean, powerful, and future-proof data center. -
Storage protocols for block, file, and object storage
 The future of flexible, performant, and highly available storage.
The future of flexible, performant, and highly available storage. -
Realistic Ceph Performance Tuning Measures
 Administrators regularly criticize Ceph performance tuning, because some elements can be tweaked effectively, while others are difficult or impossible to fine tune. We look at how to measure performance, compare actual requirements with what is technically possible, and determine realistic objectives.
Administrators regularly criticize Ceph performance tuning, because some elements can be tweaked effectively, while others are difficult or impossible to fine tune. We look at how to measure performance, compare actual requirements with what is technically possible, and determine realistic objectives. -
Storage innovations in Windows Server 2016
 The upcoming release of Windows Server 2016 introduces major innovations in the field of storage. With built-in storage replication, Storage Spaces Direct, and traffic shaping for storage access via QoS, Windows Server looks like a good candidate for employee of the month.
The upcoming release of Windows Server 2016 introduces major innovations in the field of storage. With built-in storage replication, Storage Spaces Direct, and traffic shaping for storage access via QoS, Windows Server looks like a good candidate for employee of the month. - The Role of Storage in Generative AI
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Focus On Self-Hosting
• Self-Hosted Collaboration with Forgejo
• Self-Hosted PaaS with Coolify
• Build and Host Docker Images
• Self-Hosted Pritunl VPN Server with MFA
• Self-Hosted Chat Servers
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
