« Previous 1 2 3 Next »
Databases in the Google Cloud
Spoiled for Choice
Cloud Firestore
In comparison, Cloud Firestore resides in the NoSQL camp and acts as a document database. In contrast to the databases already described, Cloud Firestore is completely serverless and has no management overhead. With this database, you only pay for what you use and don't have to worry about rightsizing or underutilized resources. The pricing model envisages users paying a certain sum for the volume of data stored (in gigabytes) and for the number of read, delete, and write operations.
Google sees Cloud Firestore's main area of application in mobile, web, and Internet of Things (IoT) databases. Offline mode for smartphones or tablets is particularly interesting. As soon as the user is back online, they can synchronize with the Firebase back end in the Google Cloud with an integrated live synchronization tool. If your users work with multiple devices, real-time updates are important because they support synchronization of data across different connected devices. One benefit for developers is that Cloud Firestore, a highly scalable NoSQL database for applications, supports transactions.
Cloud Firestore also has some technical drawbacks: It is not designed for use cases that require high write performance. If you put a great deal of emphasis on analytics, Cloud Firestore will not necessarily be your first choice; in this case, you should take a closer look at Cloud SQL or Cloud Bigtable. Normal read processes, on the other hand, are straightforward and quick and can be further optimized with the Memcached caching service.
Much like Cloud Spanner, Cloud Firestore provides automatic replication for multiple regions while ensuring strict data consistency. Google states the availability of the data as 99.999 percent. The volume of data that can be stored in Cloud Firestore is broadly similar to Cloud SQL and is in the terabyte range. Saving data in Cloud Firestore is a quick process: Unlike a relational database, you do not need to create a schema, so storage can begin immediately.
Applications access the database over the client API. As with Google's other products, client libraries exist in a variety of programming languages. Listing 1 shows how this works with Node.js. The listing creates a key and an entity. The key Task references the key and contains a data element with the fields name, description, and done. It then interacts with the Cloud Firestore API and stores the entity.
Listing 1
Accessing Cloud Firestore with Node.js
01 async function addTask(description) {
02 const taskKey = datastore.key('Task');
03 const entity = {
04 key: taskKey,
05 data: [
06 {
07 name: 'created',
08 value: new Date().toJSON(),
09 },
10 {
11 name: 'description',
12 value: description,
13 excludeFromIndexes: true,
14 },
15 {
16 name: 'done',
17 value: false,
18 },
19 ],
20 };
21 try {
22 await datastore.save(entity);
23 console.log(`Task ${taskKey.id} created successfully.`);
24 } catch (err) {
25 console.error('ERROR:', err);
26 }
27 }
In the same way –
const query = datastore
.createQuery('Task')
.filter('done', '=', false)
.filter('priority', '>=', 4)
.order('priority', {
descending: true,
});– queries can be implemented with the client library.
Low Latency with Cloud Bigtable
Cloud Bigtable is a fully managed NoSQL database that originates from the big data environment where you can store data in the petabyte range for low-latency access. The underlying storage engine takes care of scaling, lifting the need to optimize off the admin's shoulders.
This kind of performance is achieved by Cloud Bigtable's internal separation of processing and storage. Figure 2 shows how clients access nodes. A Cloud Bigtable node is responsible for a subset of data. If more data is available or more performance is desired, you can increase the number of nodes. HDDs or SSDs are available as the storage types. HDDs are less expensive in principle, but they suffer from significantly higher access latency, especially in random read processes. In contrast, they perform well in batch analytics applications such as machine learning or data analytics involving a large amount of sequential reading. In contrast, SSDs are recommended for real-time access, such as ad serving or recommendation apps. Storage is billed by data volume (in gigabytes).
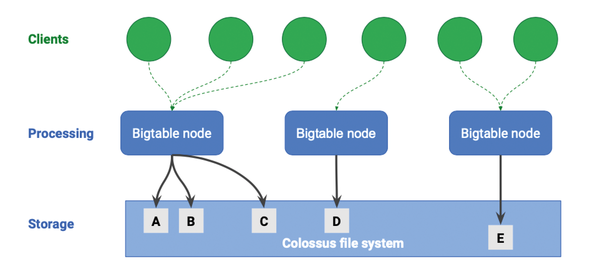 Figure 2: Isolation of processing from storage in Cloud Bigtable.
Figure 2: Isolation of processing from storage in Cloud Bigtable.
The number of Cloud Bigtable nodes can either be set manually or managed automatically, which allows you to avoid unforeseen costs – although you do need to keep an eye on the utilization status of the Cloud Bigtable cluster – or with autoscaling, which automatically sets the number of nodes and adds or removes them depending on the workload. For a highly available cluster, you can set up a second cluster and replication.
The main use cases for Cloud Bigtable are streaming and batch operations, as well as applications that require low latency when accessing data. Cloud Bigtable is usually accessed over the Apache HBase interface, which avoids vendor lock-in because access is not handled by a proprietary interface.
Data is stored as key-value pairs in tables. Each row describes an entity and each column has an individual value. Columns that belong together can be grouped into families. Indexing goes by the line key.
Data Warehouse with BigQuery
BigQuery is a fully managed, serverless data warehouse. As such, it scales easily into the petabyte range – without operational overhead. Google claims that the total cost of ownership is 26 to 34 percent cheaper compared with competitors. A special feature that BigQuery has had for some time is machine learning functionality. In particular, it provides an integrated platform for classification and regression models that is based on structured data. Machine learning functionalities such as training a model or executing predictions are easy to learn and can be handled with normal SQL syntax.
Typical fields of application are recommendation systems or regression analyses. With BigQuery Omni, Google has opened up to other cloud providers and supports querying data stored in AWS or Azure, for example. Like Microsoft with its Power BI, Google also offers a fast in-memory analytics service that lets users analyze large volumes of data with sub-second response times. Additionally, BigQuery also acts as a system for analyzing spatial-geographical information.
In addition to the option of local data, you can load data into BigQuery from various sources, such as cloud storage buckets or Google Drive data. Special connectors exist for a number of third-party systems that can be addressed with the BigQuery data service. If you need your own special logic when transforming the input data, the Google Cloud Data services Fusion and Dataflow are there to help you. A number of other partner integrations exist, as well. Data is stored in tables that can be combined to create datasets and assigned the appropriate authorizations. The easiest way to work with BigQuery is through the Google Cloud console (Figure 3).
 Figure 3: BigQuery can be managed in the Google Cloud console.
Figure 3: BigQuery can be managed in the Google Cloud console.
« Previous 1 2 3 Next »
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
US / Canada
UK / Australia
Related content
-
Building Big Iron in the Cloud with Google Compute Engine
 Google Compute Engine removes the technical and financial headaches of maintaining server, networking, and storage.
Google Compute Engine removes the technical and financial headaches of maintaining server, networking, and storage. -
Scale-out with PostgreSQL
 The world of scale-out is stateless; unfortunately, databases are not. YugabyteDB solves this dilemma for PostgreSQL.
The world of scale-out is stateless; unfortunately, databases are not. YugabyteDB solves this dilemma for PostgreSQL. -
A Distributed SQL Database
 CockroachDB is an SQL database that is fully distributed and designed for excellent scalability.
CockroachDB is an SQL database that is fully distributed and designed for excellent scalability. -
Why databases are moving to the cloud
 Demand for cloud databases continues to increase, not only because of better scalability and availability, but because of lower investment and operating costs. We'll look at some of the limitations.
Demand for cloud databases continues to increase, not only because of better scalability and availability, but because of lower investment and operating costs. We'll look at some of the limitations. -
MySQL as a Service
If you need a hosted solution that provides all the features of MySQL, a MySQL-as-a-service product might be the database option you’re looking for.
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
