Side Channel Attacks
If you believe the movies, expert hackers only need to type a few cryptic characters at the command line to gain full access to the target within seconds. In reality, however, attacks on IT systems are usually not so easy to accomplish. Instead, the attacker sometimes needs days or weeks to succeed. During this time, the intruder explores the system to find a way around defensive measures, determines the best strategy for the attack, and avoids telltale log entries. Such attacks often occur in several successive steps and are called side channel attacks if they exploit hidden information just from observing the target system.
If this scrutiny relates to the hardware, it can include runtimes, processor power consumption, or electromagnetic radiation; if the intruder is focused on software resources, the attack might center on error messages or log entries. An intruder who is looking for information on the software might try to find out the version and patch level of the operating system, the database, the network components, or any active applications. The study might also include file paths to confidential data or configuration files.
Of course, the security of encryption and cryptographic signatures depends first and foremost on keeping the key a secret (Kerckhoffs’s principle) Ð but why give the attacker a head start by revealing other clues, such as the cryptographic encryption algorithms? Without this information, the attacker has to spend valuable time snooping around looking for answers. “Security by obscurity” is known to be bad if the security of a system largely depends on it. But, conversely, a system doesn’t become safer if you disclose all its details; that just makes life easier for the attacker.
Annoyingly, however, many systems are very verbose by default and share the manufacturer, version, or patch level with attackers. For example, the default configuration for the Apache web server not only reveals its own identity but also provides detailed version information for the loaded plugins as shown in the following listing.
Apache/2.2.16 (Debian) DAV/2 SVN/1.6.12 mod_fcgid/2.3.6 Phusion_Passenger/3.0.11 mod_ssl/2.2.16 OpenSSL/0.9.8o Server at www.domain.tld Port 80
Treacherous Error Messages
Technical error messages from the web server, such as stack traces, are another source of information. These messages not only inform users of error conditions, but also reveal confidential information that goes well beyond the manufacturer and version number. This information includes, for example, the file paths that an application uses:
Warning: include( ): Failed opening 'File.php' for inclusion (include_path='.:') \ in /home/www/domain.tld/http/index.php on line 42
The preceding example shows a message that has occurred in a PHP application. Here, the attacker learns that the application has not found a file called file.php and discovers the local path on the server filesystem, under which the web application is stored. In this case, the attacker could possibly even deduce the file paths to other websites also hosted on that server, because the domain name is a part of the path. From there, it is an easy guess that the example.com domain would reside in the path /home/www/example.com/http/ . But, even if applications are not quite this loquacious, they often reveal more about themselves than you might think.
Take for example, the login screen on a web page, which consists of a username and a password field. If the attacker enters an arbitrary username/password combination, and the server responds with the error message Invalid User Name , the attacker learns that this username does not exist.
Figure 1 shows that Wikipedia freely communicates such information.
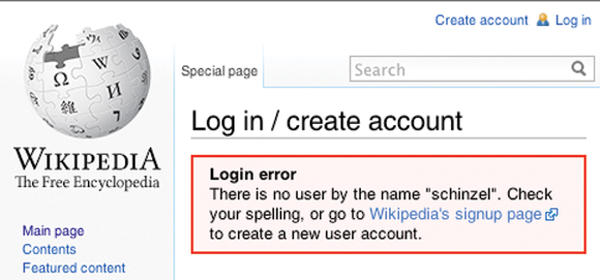 Figure 1: Wikipedia unnecessarily reveals whether or not a user exists. This allows a targeted brute-force attack.
Figure 1: Wikipedia unnecessarily reveals whether or not a user exists. This allows a targeted brute-force attack.
This information is interesting for the attacker who wants to create a targeted brute-force attack on an existing username. Therefore, websites should respond with a generic error message, indicating an error but not revealing any information about user accounts.
In extreme cases, simply the fact that an attacker can detect error conditions can lead to fatal vulnerabilities. For example, Jager and Somorovsky recently published an attack on the “XML Encryption” encryption standard that gives an attacker the ability to decrypt cipher text [1].
The attacker needs to be able to sniff the cipher text and send a modified version of it to the target server. The simple fact of whether or not the server reports a decryption error is sufficient for the attacker to decrypt the individual bytes of the cipher text. In the described attack, the attacker requires only around 14 requests to the server to decipher a byte of the cipher text.
The underlying attack is based on padding oracles, which were revealed back in 2002 by Serge Vaudenay, and which were recently used by Juliano Rizzo and Thai Duong [2] to break captchas and view states in web development frameworks. The attacks described by Rizzo and Duong took advantage of the fact that the vulnerable applications encrypted confidential information and forwarded it to the browser. The developers of the vulnerable applications had relied on the attacker’s inability to read the data.
The user’s browser sends the captcha-obfuscated text back to the captcha provider as an encrypted message, along with the captcha. The provider then decrypts the solution and compares it with the user input. This has the advantage that the captcha provider does not need to manage the user session server-side. Rizzo and Duong were able to decrypt this solution via a padding oracle, thus breaking the captcha. That story illustrates how an attacker can sometimes break even complicated cryptographic concepts by evaluating the error messages from a system.
Side Channels on the Web
So far, error messages that attackers can read directly have provided the side channel. However, an application can reveal information through less obvious clues. An example of an application providing too much information was fixed in version 4.5.4 of the popular Typo3 Content Management System: Attackers were able to detect whether a given username was a valid administrative user for the present Typo3 instance simply by evaluating the HTTP header order of the Typo3 back end (Table 1).

The root cause of this error is that Typo3 separates the task of checking the username and password. The username is checked first. If the username is valid, some configuration values are loaded for the user, and a session is started by the PHP session_start( ) function. This call also affects the cache settings that the server reveals in the HTTP header. Thus, cache directives in the HTTP header are changed precisely if the username you have chosen belongs to a valid administrative user. Interestingly, you will only find these differences if you specifically look for them; there is no visual difference that users or programmers can see in the browser.
A similar vulnerability was fixed in version 2.3.2 of Postfix Admin, a management web application for the Postfix mail server. In previous versions, attackers were able to determine whether or not an email address belonged to a valid administrative user. To do this, the attacker only had to enter the email address to be tested as the username in the login screen of Postfix Admin and confirm. The result was that an error message was issued and the user was prompted to correct the email address or the password. However, there was the subtle difference: Postfix Admin left the previously entered email address in the username field if it was correct and belonged to an administrator account. Figure 2 shows the vulnerable portion of the HTML source code for the Postfix Admin login screen. The gray part is shown or hidden, depending on whether a valid or invalid email address is entered.
 Figure 2: Valid and invalid addresses are handled differently, as the grayed areas indicate.
Figure 2: Valid and invalid addresses are handled differently, as the grayed areas indicate.
Generally speaking, these information leaks are very difficult to find because many popular websites generate parts of the HTTP header and the HTML content dynamically. It is, therefore, not enough to compare responses from multiple web servers, instead you need to target differences related to confidential information. In 2011, Schinzel and Freiling [3] presented a method for finding this kind of dynamic content that depends on confidential information. The core of the method is shown in Figure 3.
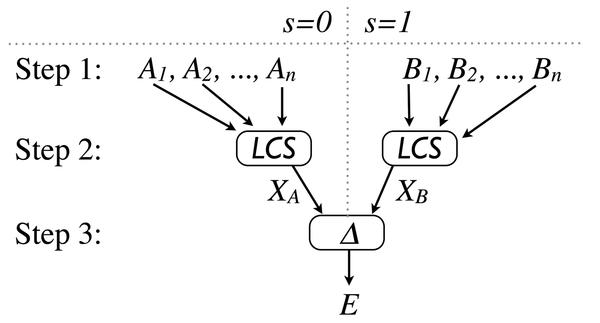 Figure 3: Filtering out the dynamic parts without reference to the username shows the differences that depend on the existence of the username.
Figure 3: Filtering out the dynamic parts without reference to the username shows the differences that depend on the existence of the username.
In the first step, the attacker issues n login requests with an existing user and collects the responses (A_1, A_2, …, A_n ). The attacker then continues to issue n login requests with a non-existing user and collects the responses (B_1, B_2, …, B_n ).
In the second step, the attacker forms the joint longest common subsequence (LCS) of A and B , which filters out all the dynamic parts that do not depend on the existence of the user. As a result, X_B X_A then contain the static core of the responses. In the third step, the attacker compares X_A and X_B . If differences are found in this step, these differences depend on whether or not the username exists, and the attacker has found a generic weakness in the target application. The attacker can now launch a brute-force attack with different usernames and determine, on the basis of the response, whether or not a username exists.
Countermeasures
To prevent information leakage through error messages, the error messages should be as generic as possible. It is sufficient, in many cases, to show a generic page to the users, which assigns a randomly generated and unique error ID in addition to showing a generic error message.
If the user cannot solve the problem, administrators can use the error ID to view the detailed error message. This prevents an attacker from gleaning confidential information through analysis of the error messages. Additionally, administrators should log the error conditions and monitor the total number of error messages. If the number of errors increases substantially over time, or if many errors can be traced back to just a few users, this could be a sign of an attack.
Side channels lead to information leaks that are only visible on closer inspection and can remain undetected for years. The side channels illustrated here relate to information leaks in the dynamic fragments of the HTTP and HTML sections of websites. Because websites are becoming increasingly dynamic, there is a growing probability of side channels occurring, and it will become increasingly difficult to tell the side channels from the non-risky dynamic components. Therefore, the burden is on the programmers of the applications to discover side channels and individually close them down, as the Postfix Admin and Typo3 developers have already done.
Info
[1] “How to Break XML Encryption” by Tibor Jager and Juraj Somorovsky
[2] “Practical Padding Oracle Attacks” by Juliano Rizzo and Thai Duong
[3] “Detecting Hidden Storage Side Channel Vulnerabilities in Networked Applications” by Felix C. Freiling and Sebastian Schinzel
Author
Dr. Sebastian Schinzel is a member of the scientific staff at the University of Erlangen-Nuremberg, where he studies hidden information leaks in web applications. He has more than six years of experience as an author, speaker, and active penetration tester, and he advises companies on software application security.
Related content
-
Security risks from insufficient logging and monitoring
 Although inadequate logging and monitoring cannot generally be exploited for attacks, it nevertheless significantly affects the level of security.
Although inadequate logging and monitoring cannot generally be exploited for attacks, it nevertheless significantly affects the level of security. - OpenSSH Fixes Side Channel Attacks
-
Distributed denial of service attacks from and against the cloud
 In some particularly sophisticated DDoS attacks, the attackers rely on and target the cloud, allowing attackers to work around conventional defense mechanisms. We explain how a DDoS attack in the cloud works, and how you can defend against it.
In some particularly sophisticated DDoS attacks, the attackers rely on and target the cloud, allowing attackers to work around conventional defense mechanisms. We explain how a DDoS attack in the cloud works, and how you can defend against it. -
Denial of Service in the Cloud

In some particularly sophisticated DDoS attacks, the attackers rely on and target the cloud, which allows them to work around conventional defense mechanisms. We explain how a DDoS attack in the cloud works, and how you can defend against it.
- Two New Speculative Execution Vulnerabilities Found in the Linux Kernel
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Focus On Self-Hosting
• Self-Hosted Collaboration with Forgejo
• Self-Hosted PaaS with Coolify
• Build and Host Docker Images
• Self-Hosted Pritunl VPN Server with MFA
• Self-Hosted Chat Servers
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
