Go Live
The cloud is said to be efficient and flexible, but neither virtualization nor billing by resource use are new; in fact, the concepts come from prehistoric IT. Because cloud solutions are now considered mainstream, planners and consultants in IT companies assume that admins will virtualize any new server platform, saving hardware and ongoing operating costs and offering numerous other benefits, more or less incidentally.
One of these benefits is live migration of running systems, which would be impossible on real hardware but which virtualized systems manage quite easily. Freezing a VM running on a host, moving it to another virtualization host, and continuing operations there with no noticeable hiccups in service from the user’s point of view, is the art of virtualization and is what separates the wheat from the chaff.
Games Without Frontiers
A few years ago, an archetypal demo setup, in which players of the 3D first-person shooter Quake 3 didn’t even notice that the VM and its server had moved from one host to another during the game, caused a sensation. The effective downtime for the client was a few seconds, which could be mistaken as a hiccup on the network.
Admins enjoy live migration for other reasons, however. For example, it allows them to carry out maintenance work on virtualization hosts without extended downtime. Before work starts on a computing node, administrators migrate all the VMs to other servers, allowing them to work on the update candidates to their heart’s content. Unfortunately, this process does not work between different products, architectures, or CPU variants, as related in the “Not Without Downtime” box.

Technical Background
Today, prebuilt solutions exist for live migration; they have this capability out the box, and in many cases even offer a GUI option for point-and-click live migration. The technical backgrounds of most of these solutions are the same. The virtualization solution copies the content of a virtual machine running on Host A (i.e., the RAM data that needs to be migrated on the fly to a different host) to the target host and launches the virtualization process on the target while the system on host A still continues to run.
When the RAM content has been received in full by the target host, the virtualizer stops the VM on the source host, copies the current delta to the target, and finally terminates the emulator on the source host. In an ideal case, this short time is the only downtime that occurs.
For this principle to work, a few conditions must be met. The main issues relate to storage. To run the virtual machine simultaneously on two hosts, their storage must be available to both computers for read and write operations at the specified time. How this works in reality depends on the shared storage technology and the architecture of the virtualization solution.
Storage: NFS, iSCSI, DRBD, Ceph
A storage area network (SAN) is often a component of a VM setup. SANs serve up their data mostly via NFS or iSCSI. With NFS, shared access to the data is managed easily; after all, this is just what NFS was designed for. iSCSI SANs are trickier and require additional functions in terms of the software that manages the virtual machines. The iSCSI standard does not actually envisage concurrent access to the same logical unit number (LUN) for two servers, so workarounds using LVM or cluster filesystems like OCFS2 and GFS2 are necessary.
VM live migration is easier to set up on a distributed replicated block device (DRBD) cluster basis. DRBD basically provides the option of using an existing resource in dual primary mode, for which write access is possible on both sides of a cluster. Together with modern cluster managers such as Pacemaker and Libvirt, this configuration can be used to provide genuine, enterprise-grade live migration capabilities. The drawback of this solution is that DRBD restricts migration to two nodes, at least until DRBD 9 is mature enough for use in a production environment.
Administrators who are looking for reliable virtualization with live migration, as well as scale-out capabilities, should consider Ceph when planning their new setups. The components required for this kind of setup are now viewed as stable and suitable for production use.
An Object Store
The Ceph solution belongs in the object storage category; files stored in Ceph are split into binary objects and then distributed to a plurality of storage locations. Object stores use this approach to work around a problem that arises when you try to design distributed systems on the basis of block storage: Blocks are rigid and closely tied to the filesystem, which makes block-based data media accessible to the user in the first place.
However, it makes little sense to use a bare metal hard disk directly from the factory. Although you could store data on it, reading the data in a meaningful way later on would be impossible. The structure that allows meaningful access to block-based storage is provided by a filesystem, but because a filesystem cannot be divided easily into several strips and then distributed to different servers, blocks are basically useless for scale-out solutions.
Object stores work around this problem by handling internal management themselves and constructing binary objects that are divisible and can be reassembled. In a way, they add an intermediate layer between the filesystem and the user.
Arbitrary Front Ends
One major advantage of object stores is that they are ultimately capable of providing an arbitrary front end to the client. After all, if the object store handles its internal organization on the basis of binary objects, it can also deliver them to the clients in any format. In the case of Ceph, for which the object store is called RADOS, the developers make multiple use of this capability. In addition to the POSIX-compatible Ceph FS and the REST API, Radosgw, RADOS publishes its data in the form of a RADOS Block Device (RBD).
The good news is that current Libvirt versions already support RADOS, and current versions of Qemu come with a native connection to RADOS via RBD (by way of the Librados C library).
The effect is quite impressive: The object store can be connected directly to Libvirt or Qemu on any number of virtualization nodes, and simultaneous access to the same binary objects from multiple locations is possible, which solves the problem of live migration.
Libvirt makes sure that nothing goes wrong; that is, it prevents hostile, or even competing write access during the actual VM migration.
En Route to the Virtualization Cluster
The prerequisite for a meaningful Ceph setup is three servers. Why three? To ensure that Ceph’s quorum-handling functions work in a meaningful way. Ceph treats each drive as a separate storage device, so the number of disks (OSDs, object storage daemons; Figure 1) per host ultimately plays a subordinate role.
 Figure 1: Ceph manages its OSDs centrally, creating an intermediate layer between users and the block device to achieve flexibility.
Figure 1: Ceph manages its OSDs centrally, creating an intermediate layer between users and the block device to achieve flexibility.
It is advisable, initially at least, to use three computers with an identical hardware configuration for the setup.
Admins should not look for a low-budget hardware option. In addition to the object store role, the computers simultaneously act as virtualization hosts, so that each is thus part of the object store and a virtualizer.
In combination with Pacemaker and a configuration similar to that described for DRBD, a self-governing VM cluster is created from the individual cluster nodes. On the cluster, any virtual machine can run on any host, and live migration between computers also works fine – thanks to the Qemu and RBD pairing. For more information on Ceph, check out some of my previous articles (“RADOS and Ceph,”“The RADOS Object Store and Ceph Filesystem,” “CephX Encryption,” and “Ceph: Maintenance”).
DRBD, Pacemaker, and Libvirt
The VM migration concepts of various other third-party suppliers are just as varied as they are complex. However, Linux systems have some built-in tools with the ability to set up VM migration with Libvirt and Pacemaker. The following example is initially based on a simple two-node cluster that uses DRBD to keep its data synchronized between hosts. This type of setup is not particularly complex and offers useful insights into how it works.
For live migration with Libvirt and Pacemaker to work as intended on the basis of DRBD, DRBD must first be taught to run in dual-primary mode; this option is disabled out the box for safety reasons.
DRBD 8.3
How you enable this mode for DRBD depends on the DRBD version you are using. If you are using DRBD 8.3, which is the case for the majority of enterprise systems, the following entry in the resource configuration enables dual-primary mode:
net {
allow-two-primaries;
}With DRBD 8.4, you need to add the following entry to the resource configuration:
net {
protocol C;
allow-two-primaries yes;
}These changes can be made on the fly; you simply need to issue a
drbdadm adjust <resource>
command when you are done. Caution: With Pacemaker, it is advisable at least to switch the cluster to maintenance mode before making any changes to DRBD or Libvirt. To do so, you can type:
crm configure property maintenance-mode=true
directly at the command line of one of the nodes belonging to the cluster; the command is effective throughout the cluster.
Pacemaker with More than Two Nodes
If you use a two-node cluster for virtualization, you will typically want to let Pacemaker manage DRBD. How-tos on the web configure the DRBD resources so that only one of the two nodes runs in primary mode (Figure 2).
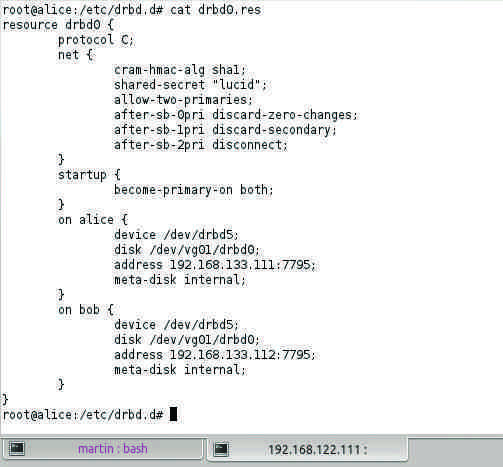 Figure 2: DRBD can be used with the dual-primary function for live migration of virtual machines in two-node clusters.
Figure 2: DRBD can be used with the dual-primary function for live migration of virtual machines in two-node clusters.
To change this, you need to make a configuration change to Pacemaker. DRBD resources in Pacemaker typically look like this:
ms ms_drbd-vm1 p_drbd-vm1 meta notify="true" master-max="1" clone-max="2"
To enable dual-primary mode for a DRBD resource like this, just set the value that follows master-max to 2 . Pacemaker then automatically configures the DRBD resource so that it runs in primary mode on the two cluster nodes.
Libvirt Instances
The next obstacle en route to live migration is to introduce the Libvirt instances to one other on the nodes. For a live migration between nodes A and B to work, the Libvirt instances need to cooperate with one other. Specifically, this means that each Libvirt instance needs to open a TCP/IP socket. All you need are the following lines in /etc/libvirt/libvirtd.conf :
listen_tls = 0 listen_tcp = 1 auth_tcp = "none"
The configuration shown does not use any kind of authentication between cluster nodes, so you should exercise caution. Instead of TCP, you could set up SSL communication with the appropriate certificates. Such a configuration would be much more complicated, and I will not describe it in this article.
In addition to the changes in libvirtd.conf , administrators also need to ensure that Libvirt is launched with the -l parameter. On Ubuntu, you just need to add the required parameter to the libvirtd_opts entry in /etc/default/libvirt-bin then restart Libvirt. At this point, there is nothing to prevent live migration, at least at the Libvirt level (Figure 3).
 Figure 3: Given the right configuration parameters, Libvirt listens on a port for incoming connections from other Libvirt instances on the network.
Figure 3: Given the right configuration parameters, Libvirt listens on a port for incoming connections from other Libvirt instances on the network.
Live Migration with Pacemaker
For Pacemaker to control the live migration effectively, you still need to make a small change in the configuration that relates to the virtual machine definitions stored in Pacemaker. Left to its own devices, the Pacemaker agent that takes care of virtual machines would by default stop any VM that you try to migrate and then restart it on the target host.
To avoid this, the agent needs to learn that live migration is allowed. As an example, the following code shows an original configuration:
primitive p_vm-vm1 ocf:heartbeat:VirtualDomain params \ config="/etc/libvirt/qemu/vm1.cfg" op start interval="0" timeout="60" \ op stop interval="0" timeout="300" op monitor interval="60" timeout="60" \ start-delay="0"
To enable live migration, the configuration would need to be modified as follows:
primitive p_vm-vm1 ocf:heartbeat:VirtualDomain params \ config="/etc/libvirt/qemu/vm1.cfg" migration_transport="tcp" \ op start interval="0" timeout="60" op stop interval="0" timeout="300" \ op monitor interval="60" timeout="60" start-delay="0" \ meta allow-migrate="true" target-role="Started"
The additional parameters and the new meta attribute are particularly important. Given this configuration, the command
crm resource move p_vm-vm1
would migrate the virtual machine on the fly.
iSCSI SANs
If you need to implement live migration on the basis of a SAN with an iSCSI connection, you face a much more difficult task, mainly because SAN storage is not really designed to understand concurrent access to specific LUNs from several nodes. Therefore, you need to add an intermediate layer and retrofit this ability.
Most admins do this with the cluster version of LVM (CLVM) or a typical cluster filesystem (GFS2 or OCFS2). In practical terms, the setup is as shown in Figure 4: On each node of the cluster, the iSCSI LUN is registered as a local device; an instance of CLVM or OCFS/GFS2 takes care of coordinated access. Also, this requires that Libvirt itself provides reliable locking.
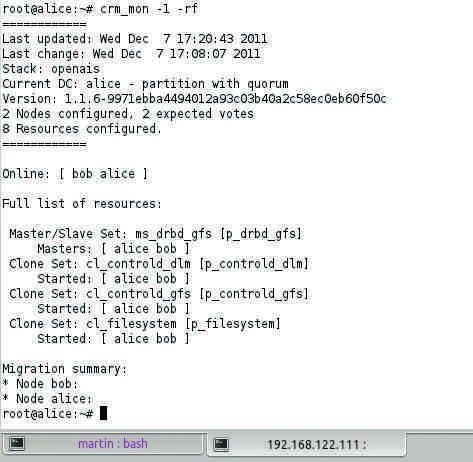 Figure 4: A typical Pacemaker setup.
Figure 4: A typical Pacemaker setup.
Setups like the one I just mentioned are thus only useful if Libvirt uses the sanlock tool at the same time. This is the only way to prevent the same VM running on more than one server at any given time, which would also be fatal to the consistency of the filesystem within the VM itself.
The Weakest Link
Although the SAN solution above sounds plausible in theory, it can quickly become an annoyance in the sys admin’s daily grind. The weakest link in the Libvirt, SAN, Pacemaker, and GFS2/OCFS2/CLVM combination is undoubtedly CLVM, partly because the distributed locking manager (DLM) stack on Linux has been repeatedly modified in recent years. Thus, SLES, RHEL, Debian, and Ubuntu each have different tasks to handle, if a setup of this kind is to get off the ground.
Moreover, DLM-based components are highly complex and affect both the services themselves as well as management by a cluster manager, which is a must-have in this kind of setup.
Bastian Blank, who is heavily involved in maintaining the Linux kernel for Debian, recently even disabled the CLVM service in the Debian kernel, commenting that it had never worked reliably anyway. If you have a SAN that supports NFS, you would do well to use it instead of resorting to a cluster filesystem or distributed LVM.
DIY or Buy?
Admins who rely on one of the prebuilt virtualization solutions, such as VMware or Red Hat oVirt, no longer need to worry about the issue of migration and live migration as a general rule.
All of the ready-made solutions here offer live migration. If a small virtualization setup is desired on the basis of DRBD, a combination of DRBD, Pacemaker, and Libvirt is all you need for live migration.
However, if you have SAN storage, you can only hope that the device offers NFS capabilities; otherwise, you will need to resort to tools that convert a SAN into distributed storage.
Ceph is definitely an alternative; it has relied on Libvirt live migration from the outset (Figure 5).
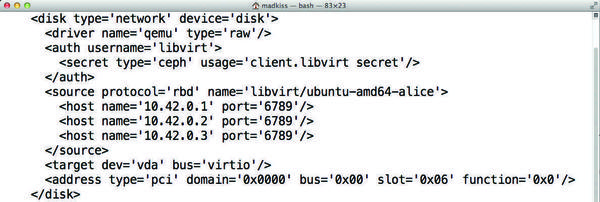 Figure 5: The current version of Libvirt offers native Ceph connectivity. Live migration is no longer a problem in this kind of setup.
Figure 5: The current version of Libvirt offers native Ceph connectivity. Live migration is no longer a problem in this kind of setup.
Now that its manufacturer, Inktank, has also officially declared the required components – Ceph, RADOS, Librados, and DRBD – to be stable, Ceph certainly should be considered within the scope of a setup like that discussed here.
The Author

Martin Gerhard Loschwitz is Principal Consultant at hastexo, where he is intensively involved with high-availability solutions. In his spare time, he maintains the Linux cluster stack for Debian GNU/Linux.
Related content
-
Live migration of virtual machines
 A big advantage in virtualization is the ability to move systems from one host to another without exposing the user to a long period of downtime. To that end, the hypervisor and storage component need to cooperate.
A big advantage in virtualization is the ability to move systems from one host to another without exposing the user to a long period of downtime. To that end, the hypervisor and storage component need to cooperate. -
Create a high availability VM with DRBD9 and Reactor
 DRBD9 and DRBD Reactor create a Linux high-availability stack for virtual instances with replicated storage comparable to the classic Corosync and Pacemaker solution.
DRBD9 and DRBD Reactor create a Linux high-availability stack for virtual instances with replicated storage comparable to the classic Corosync and Pacemaker solution. -
CephX Encryption

We look at the new features in Ceph version 0.56, alias “Bobtail,” talk about who would benefit from CephX Ceph encryption, and show you how a Ceph Cluster can be used as a replacement for classic block storage in virtual environments.
-
Monitoring KVM instances with Opsview
 In emergencies, administrators need to know as quickly as possible whether computers in a private cloud are failing. A simple setup with KVM, Pacemaker, DRBD, and Opsview will help keep watch.
In emergencies, administrators need to know as quickly as possible whether computers in a private cloud are failing. A simple setup with KVM, Pacemaker, DRBD, and Opsview will help keep watch. -
OpenStack workshop, part 3:Gimmicks, extensions, and high availability
 OpenStack has a number of useful extensions that can help admins protect their cloud against failures.
OpenStack has a number of useful extensions that can help admins protect their cloud against failures.
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Focus On Self-Hosting
• Self-Hosted Collaboration with Forgejo
• Self-Hosted PaaS with Coolify
• Build and Host Docker Images
• Self-Hosted Pritunl VPN Server with MFA
• Self-Hosted Chat Servers
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
