
Lead Image © THISSATAN KOTIRAT , 123RF.com
A self-healing VM system
Server, Heal Thyself
A common definition of a self-healing system is a set of servers that can detect a malfunction within its own operations and then repair any error(s) without outside intervention. "Repair" in this case will specifically mean replacing the problematic node entirely. In the example discussed in this article, I used Monit [1] to monitor the state of each virtual machine and Ansible to execute the replacement of faulty nodes. A DHCP server was also configured to assign new network addresses and reclaim the addresses that are no longer used.
An in-depth tutorial of the technologies used in the examples is not given. It is left up to the reader to acquire additional documentation if needed. Figure 1 below shows an overview of the setup.
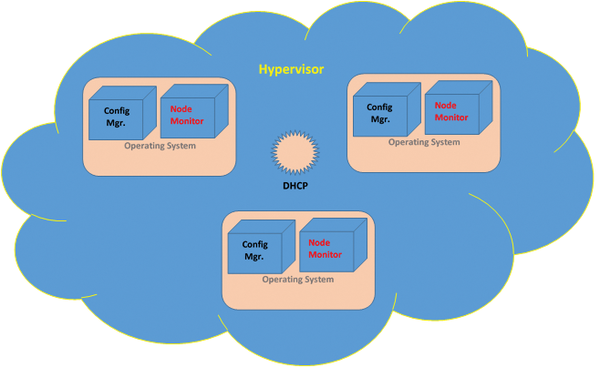 Figure 1: The big picture. DHCP services may exist on an outside system, if desired.
Figure 1: The big picture. DHCP services may exist on an outside system, if desired.
Clouds and Hypervisors
The term "hypervisor" in this article means any platform or program that manages virtual machines to share the underlying hardware resources of a cluster of host servers. Under this definition, Amazon Web Services and Azure are included as hypervisors. Traditional examples, such as Red Hat KVM, VMware ESXi, and Xen are more suitable for this
...
Buy this article as PDF
(incl. VAT)
Buy ADMIN Magazine
Related content
-
Bare metal deployment with OpenStack
 Automating processes in the age of the cloud is not just a preference, but a necessity, especially as it applies to the installation and initial setup of compute nodes. OpenStack helps with built-in resources.
Automating processes in the age of the cloud is not just a preference, but a necessity, especially as it applies to the installation and initial setup of compute nodes. OpenStack helps with built-in resources. -
Automated OpenStack instance configuration with cloud-init and metadata service
 Today's OpenStack has become a mature product with automated asset configuration tools, including cloud-init, a powerful script that saves time by automatically configuring a large number of virtual servers in the cloud.
Today's OpenStack has become a mature product with automated asset configuration tools, including cloud-init, a powerful script that saves time by automatically configuring a large number of virtual servers in the cloud. -
What's new in Ansible 2.0
 The new version of the Ansible IT automation platform has a revised and faster engine and 200 new modules.
The new version of the Ansible IT automation platform has a revised and faster engine and 200 new modules. -
Ansible collections simplify AIX automation
 Starting your AIX automation journey has never been easier with the IBM AIX collections from Ansible Galaxy.
Starting your AIX automation journey has never been easier with the IBM AIX collections from Ansible Galaxy. -
Jira, Confluence, and GitLab
 Jira, Confluence, and GitLab are very popular DevOps tools and often form the basis for agile work flows. With the right Ansible playbooks, Ubuntu can be turned into an agile work center.
Jira, Confluence, and GitLab are very popular DevOps tools and often form the basis for agile work flows. With the right Ansible playbooks, Ubuntu can be turned into an agile work center.
Subscribe to our ADMIN Newsletters
Subscribe to our Linux Newsletters
Find Linux and Open Source Jobs
Most Popular
Focus On Self-Hosting
• Wiring the Modern Stack with Node-RED
• Self-Hosted Collaboration with Forgejo
• Self-Hosted PaaS with Coolify
• Build and Host Docker Images
• Self-Hosted Pritunl VPN Server with MFA
• Self-Hosted Chat Servers
Support Our Work
ADMIN content is made possible with support from readers like you. Please consider contributing when you've found an article to be beneficial.
